登录社区云,与社区用户共同成长
邀请您加入社区
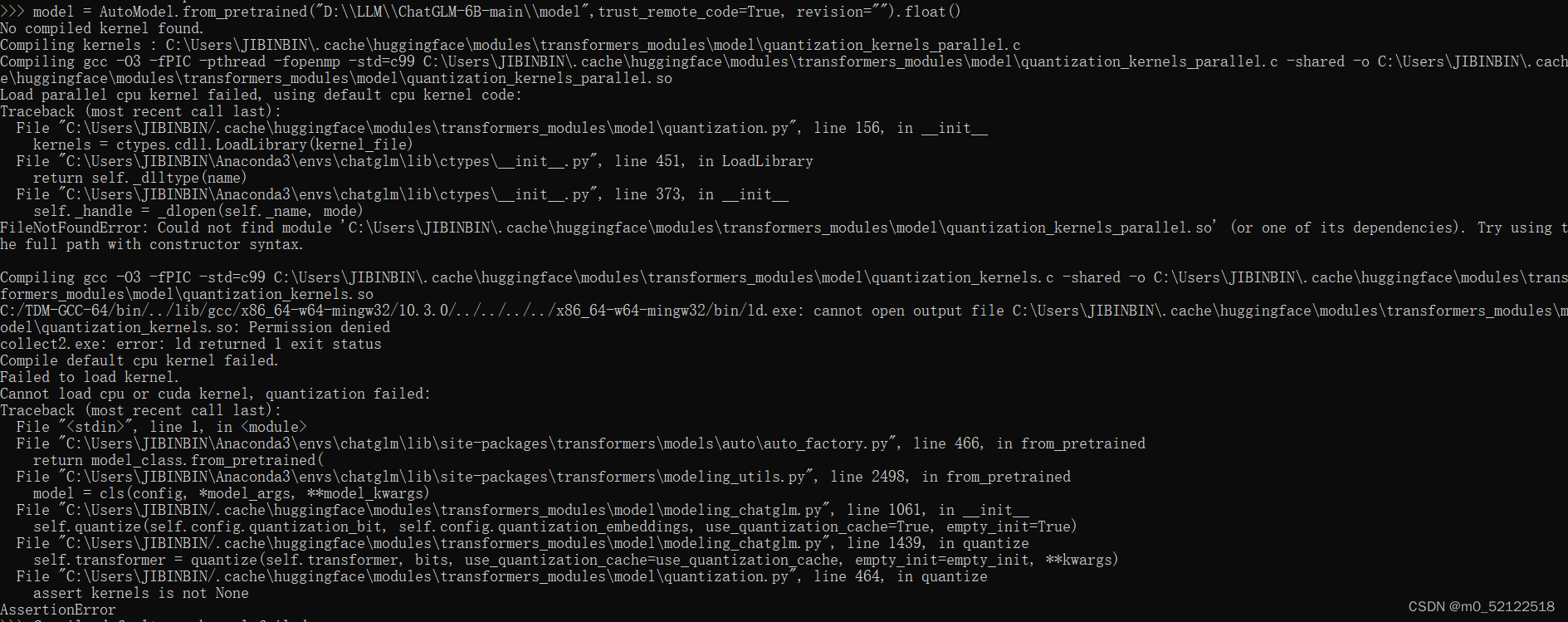
【代码】【求助】Chatglm cpu 本地部署出错。
glm-4 联网搜索api测试
Dify 之前有介绍过。
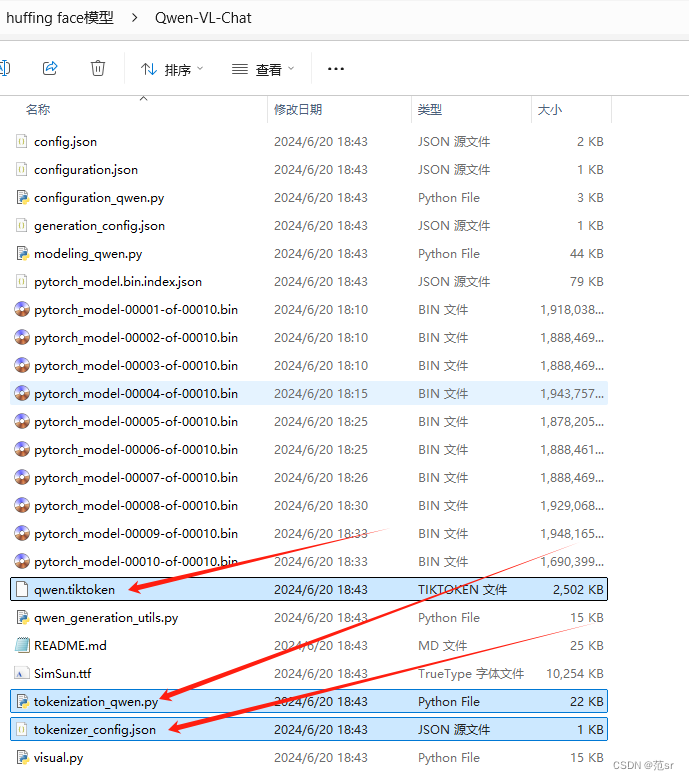
在微调qwen-vl的时候,微调完成之后,模型也保存好了,但是用保存的模型进行推理的时候报错,看样子是找不到分词器tokenizer。
llama.cpp是一个大模型推理平台,可以运行gguf格式的量化模型,并使用C++加速模型推理,使模型可以运行在小显存的gpu上,甚至可以直接纯cpu推理,token数量也可以达到四五十每秒(8核16线程,使用qwen2.5-1.5b模型),另外,该平台几乎兼容所有主流模型。本文介绍了如何使用docker部署llama.cpp和llama.cpp的python绑定llama-cpp-python
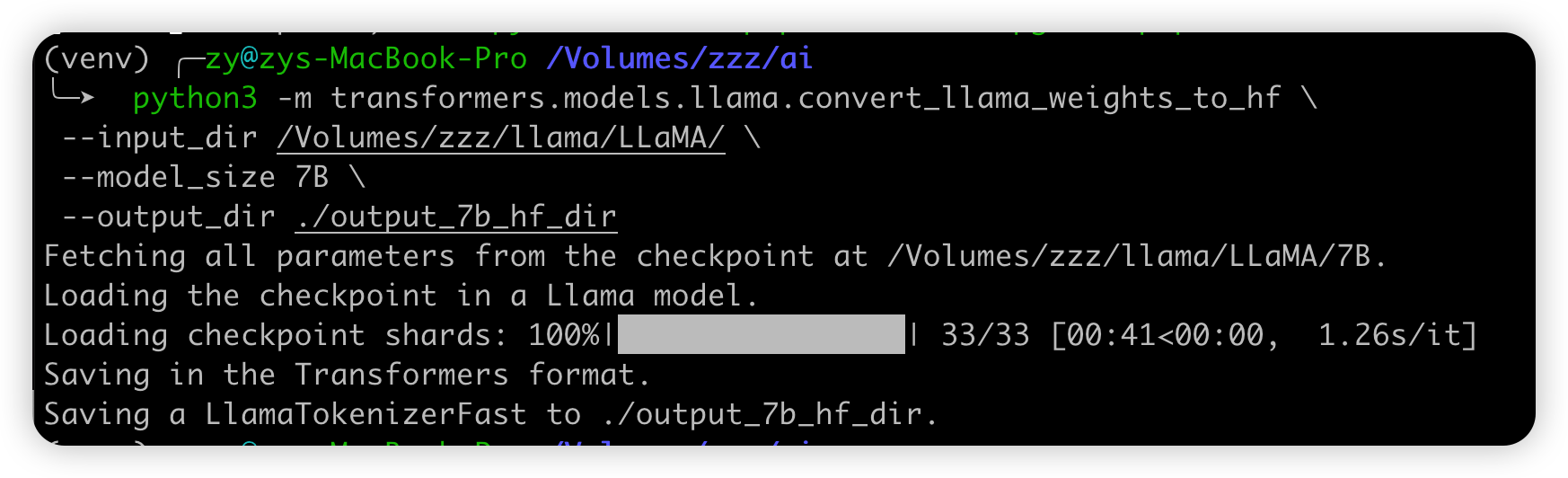
前不久,Meta前脚发布完开源大语言模型LLaMA,随后就被网友“泄漏”,直接放了一个磁力链接下载链接。然而那些手头没有顶级显卡的朋友们,就只能看看而已了但是 Georgi Gerganov 开源了一个项目llama.cpp次项目的牛逼之处就是没有GPU也能跑LLaMA模型大大降低的使用成本,本文就是时间如何在我的 mac m1 pro 上面跑起来这个模型。
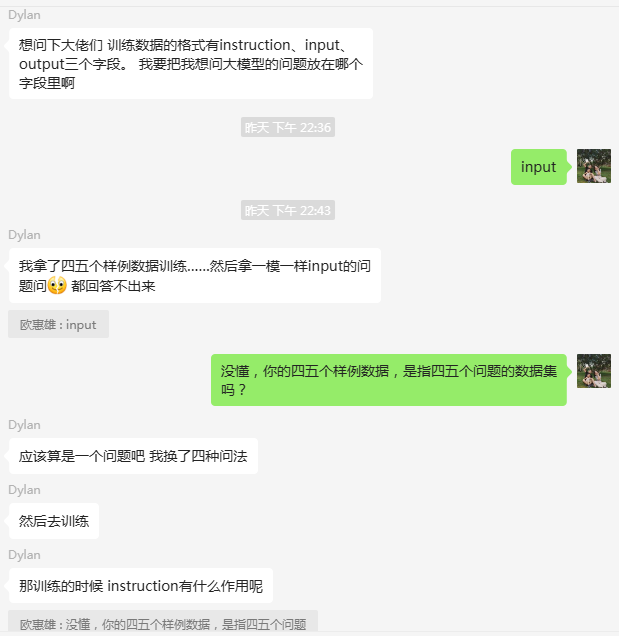
今天,在【NLP学习群】中,一位同学一下问了2个问题,相信大家在微调时也会遇到这样的问题,自己问题应该放在instruction、input、output哪个字段,用什么格式去训练呢?还有同学是几年前的老爷机/笔记本,或者希望大幅提升部署/微调模型的速度,我们应用了动态技术框架,大幅提升其运算效率(约40%),节省显存资源(最低无显卡2g内存也能提升),工众后台:“加速框架”;如果你还不知道该怎么
保姆级本地部署,金牌讲师级工具调用--基于全球10B以下最强LLM模型ChatGLM3-6B
这个问题尝试了很久,实际上是环境的问题,如果在训练过程中,将fp16设置为true+int8量化,那么是可以正常训练推理的,如果不设置int8量化就会报错。可以尝试改变peft的版本。
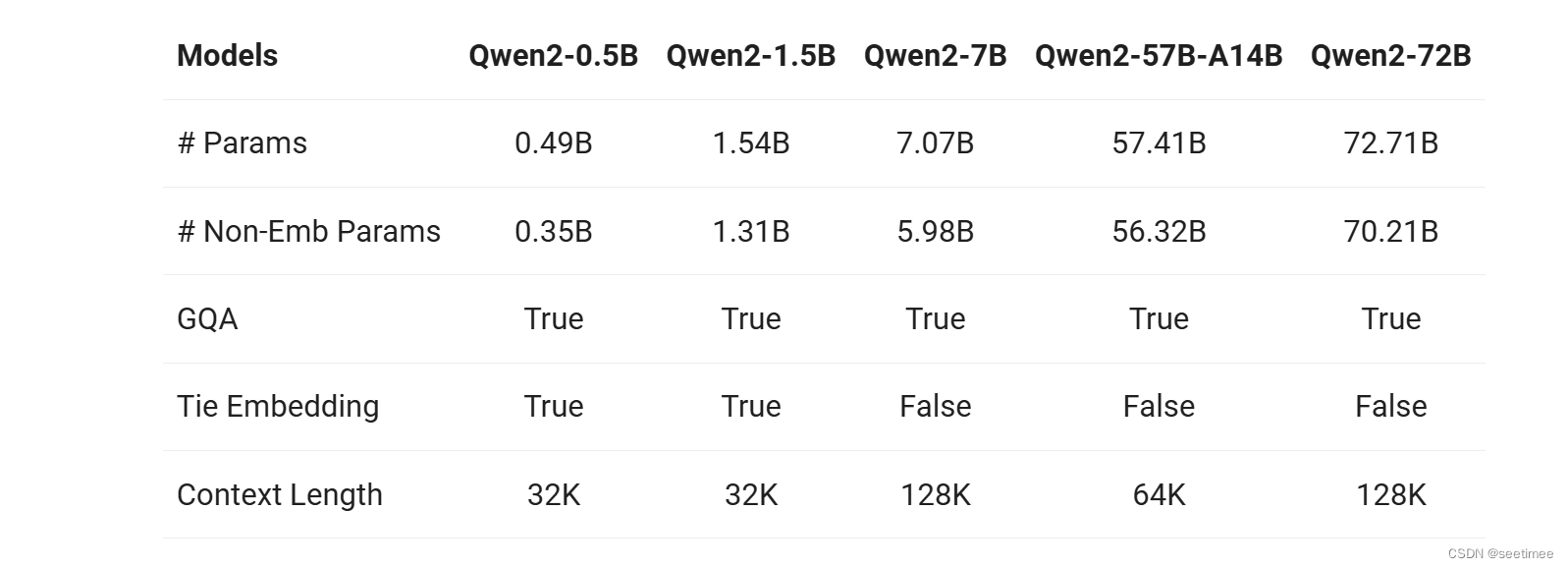
除英语和中文外,还接受过 27 种语言的数据培训显着提高编码和数学表现;Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 的扩展上下文长度支持高达 128K 令牌更详细的benchmark建议去看官网blog。
Ollama支持在Modelfile中导入GGUF模型:创建一个名为Modelfile的文件, 使用带有要导入的模型的本地文件路径的“FROM”指令。在 Ollama 里创建模型运行模型从Ollama 库下载的大模型可以用prompt 自定义. 例如, 要自定义llama3创建Modelfile# 将参数设置为1[越高越有创意,越低越连贯]# 设置系统信息SYSTEM """""">>> hiHe
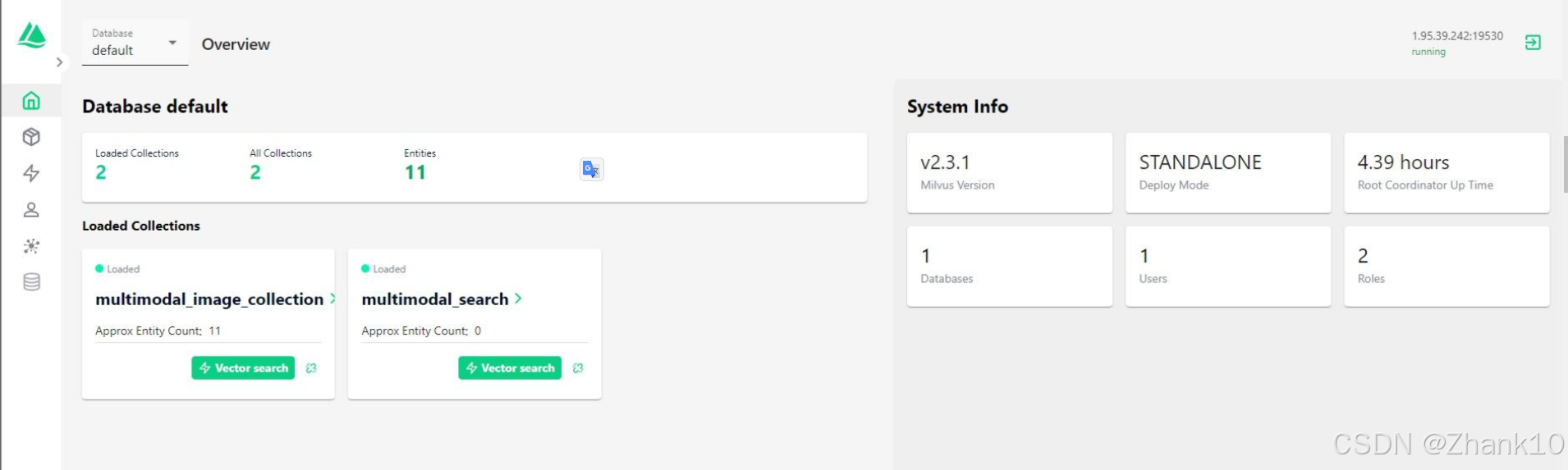
基于milvus的多模态检索,本文包含milvus安装使用、attu 可视化,完整指南启动 Milvus 进行了向量相似度搜索,利用CLIP模型进行多模态检索,附完整代码。
市场洞察:帮助企业了解消费者对其产品、品牌及竞争对手的看法和态度,及时掌握市场动态,为产品研发、市场营销和品牌建设提供决策依据。政策制定:了解公众对政策的反馈和需求,为政府制定更加科学、合理的政策提供参考,提高政策的针对性和有效性。内容管理:帮助平台更好地管理和规范用户生成的内容,打击不良信息和违规行为,营造健康、积极的网络环境。本项目旨在利用 Spark、Hive 和 Hadoop 等大数据技术
【代码】Qdrant 使用指南。
【摘要】本文介绍如何通过Herdsman本地推理引擎和TokenRouter工具,实现在ChatGPT(原Codex)中调用本地大模型,减少云端Token消耗并确保数据本地化运行。教程分六步:1)下载Herdsman并安装适合硬件配置的本地模型;2)安装TokenRouter调度引擎;3)选择智能/端侧/云端三种路由策略;4)可视化连接本地模型;5)一键配置ChatGPT;6)选择TokenRou
这一阶段评价的不是模型本身,而是数据与任务的质量:如果前期数据杂乱,任务边界不清,后续训出的模型跑分再高也不可信。数据质量:去重、去污染;标注一致性(常用一致率或 Cohen κ);垂直域的数据集(法律、医学等)往往没有现成试卷,要先定义合格的题目样本。任务定义:输出是离散类别、固定参考答案文本,还是开放生成?与后续评测的衔接:避免训练、公开榜、业务验收各说各话。对绝大多数普通用户, deepse
DeepSeekV4的HybridAttention架构通过分层记忆系统解决了百万Token上下文的核心瓶颈问题。该系统采用三级结构:SlidingWindow保留最近128个Token的原始KV作为短期精确记忆;CSA(Compressed Sparse Attention)每4个Token压缩为一条KV并建立索引系统,形成可检索的中长期记忆;HCA(Heavily Compressed Att
智能指针是C++标准库提供的类模板,用于自动化管理动态分配的内存资源。它们在对象生命周期结束时自动释放内存,从而有效防止内存泄漏,并帮助开发者编写更安全、更简洁的代码。C++11引入了包括unique_ptr、shared_ptr和weak_ptr在内的多种智能指针,每种都适用于不同的所有权语义场景。智能指针是现代C++编程中管理动态内存的基石。理解unique_ptr和shared_ptr的不同
其设计哲学强调代码的可读性和简洁性,使得初学者能够快速上手,同时为专业开发者提供了处理复杂项目的工具和框架。无论是数据分析、人工智能、Web开发还是自动化脚本,Python都能提供高效且灵活的解决方案,这正是它成为编程入门首选语言的重要原因。类(Class)是对象的蓝图,通过定义属性和方法封装数据与行为。Python的threading模块支持多线程,但由于全局解释器锁(GIL)的存在,多线程更适
本文详细介绍了在Python 3.10环境下安装Sherpa语音处理工具集的完整流程。主要内容包括:系统环境配置(推荐Ubuntu/CentOS系统)、虚拟环境创建、核心组件(PyTorch 2.5.0、k2、kaldifeat等)的安装方法与版本匹配技巧,以及Sherpa-ONNX轻量推理引擎的部署。文章还提供了安装验证方法和TTS语音合成示例,帮助用户快速测试功能。整个安装过程强调版本兼容性,
云蝠智能将于11月14日发布VoiceAgent2.0语音交互系统,标志着语音技术从"应答式"向"情感共鸣"的跨越式发展。该系统基于大模型技术,能理解语境、捕捉情感,实现金融、电商等场景的智能交互升级。发布会将深入解析大模型如何赋能语音智能体,分享技术架构与商业落地经验,为企业提供智能交互解决方案。诚邀行业伙伴共同见证这一语音交互新时代的开启。
当电商行业进入“服务定生死”的精细化运营深水区,智能客服已从单纯的成本削减工具,升级为贯穿售前询单、售中履约、售后留存的核心增长引擎。
智能客服的选型不应陷入“功能越多越好”的误区,回归知识库覆盖深度、更新速度与响应稳定性三大核心能力,才能找到真正适配自身需求的产品。
服务商的选择本质是场景适配的匹配:以电商业务为核心,尤其是服饰、3C、美妆等需要高频处理商品咨询的类目,垂类服务商的场景匹配度通常更高;若业务涉及跨行业全渠道管理,全品类服务商的全域整合能力可能更具优势。
面对市场上技术路径各异的多家服务商,商家们常常感到难以抉择。本文旨在从客观的第三方视角出发,梳理当前市场的主流技术路线,并提供一套务实的选型框架,以帮助商家找到最适合自身业务需求的合作伙伴。
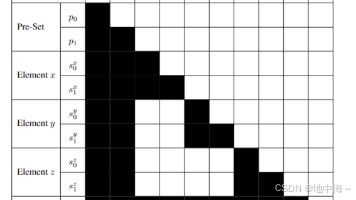
集合编码:让模型将一个集合(一组无序的元素)视为一个整体,其内部元素的排列顺序不会影响模型的输出。
面对市面上众多服务商,“国内电商智能客服机器人哪家好”成为商家高频决策疑问。本文将以第三方视角,结合实测数据与行业标准,聚焦智能客服机器人核心能力,同时对比主流服务商差异,为不同规模商家提供客观选型参考。
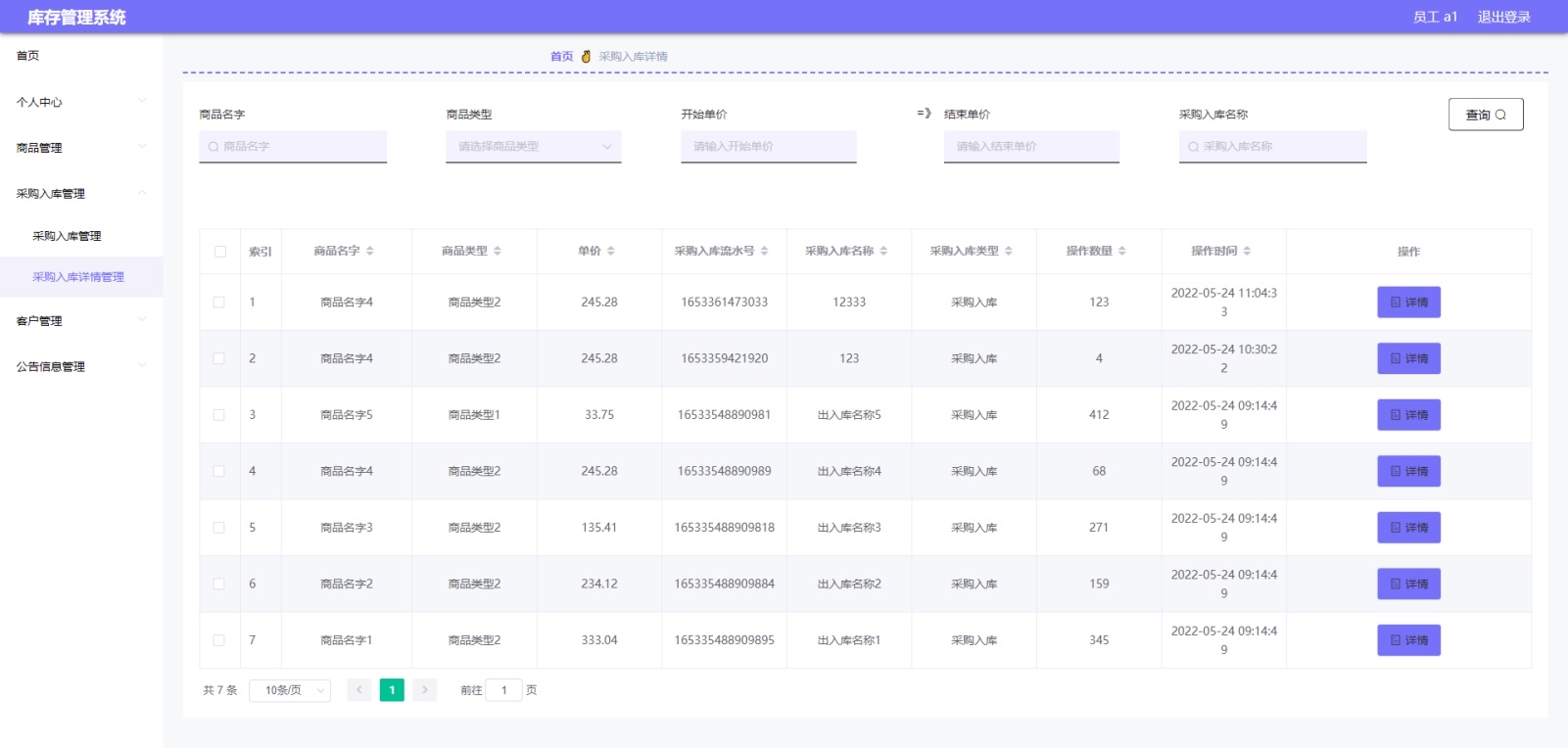
基于springboot+vue库存管理系统springboot+vue+mybatis+mysqlspringboot在当今数字化浪潮下,构建高效的库存管理系统对于企业运营至关重要。本文将带大家走进基于 Spring Boot + Vue 技术栈,搭配 MyBatis 和 MySQL 的库存管理系统开发之旅。
最后,再来一轮 RL。但这次不仅是为推理(Math/Code),还加入了对齐人类偏好(Helpfulness/Harmlessness)。只看最后的 Summary 有没有用。检查整个 CoT 和 Summary 也就是所谓的安全性检查。
nlp
——nlp
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区















 AtomGit AI 社区
AtomGit AI 社区

 DeepSeek技术社区
DeepSeek技术社区
 AI Agent技术社区
AI Agent技术社区