登录社区云,与社区用户共同成长
邀请您加入社区
CUDA_VISIBLE_DEVICES这个变量设置成自己想用的gpu序号即可。
PyCharm的缺点是:不能实时同步、操作繁琐,需要维护两份代码。而VS Code是通过SSH(Secure Shell)的方式连接到远程服务器,换句话说,VS Code在远程开发过程中扮演的角色更像是一款终端模拟工具,它不需要繁琐的上传和下载步骤,实时性更好,只需要在Windows上保存一下,就会瞬间同步到远程服务器。
备选方案:Gradio + ChatInterface、Streamlit + 自定义组件。:直接采用第 1 部分的“LlamaIndex + FastMCP + LangGraph + Chainlit”组合,并用。:MiniLLM(反向 KL 散度)、BitNet(1.58-bit 极致压缩):建议建立“预训练 → 指令微调 → RLHF”全流程,并定期做剪枝+量化。已于 2025 年 10
用户输入↓↓│ YES → query() 调用 LLM ││ NO → 本地命令执行,直接返回结果 │↓↓├→ stream_event → 更新使用量├→ system (compact_boundary) → 压缩历史└→ ...其他类型↓预算/轮次检查↓返回 result特性实现方式价值流式处理实时响应、内存高效权限追踪包装 canUseTool透明记录、可审计会话恢复预持久化 trans
很多人第一次接触HarmonyOS卡片开发时,发现卡片做好了,但数据是死的。温度永远是25度,天气永远是晴天——即使外面的太阳已经晒得人发晕,卡片上的信息纹丝不动。这个问题并不是个别案例。提供了两种数据更新方式:定时刷新和事件驱动。前者通过配置让系统自动拉新数据,后者通过在应用内部主动触发更新。但真正难的是:什么时候用定时,什么时候用手动,以及两者如何配合。这篇文章用一个模拟天气卡片来拆解这个问题
摘要:UIAbility生命周期实战指南 本文通过一个包含首页、详情页和定位功能的应用场景,详细讲解HarmonyOS中UIAbility从onCreate到onDestroy的完整生命周期管理。文章包含15个实战步骤,配有代码示例和验证清单,重点阐述: 生命周期回调的正确使用边界(初始化、页面加载、资源释放) 常见开发误区(如业务代码堆砌、资源泄漏) 前后台切换时的数据处理技巧 工程化实践建议(
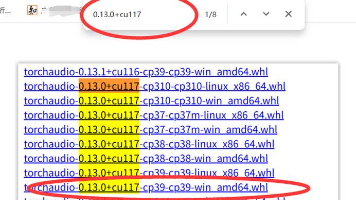
本文详细介绍了CUDA和PyTorch的安装配置流程。首先根据显卡版本安装对应CUDA(通过nvcc -V命令验证),然后创建Python虚拟环境(推荐3.9版本)。安装PyTorch时建议下载.whl文件本地安装以避免死机,需严格匹配CUDA版本(如CUDA11.7对应特定PyTorch版本)。最后通过conda list或pip list验证安装结果,并测试torch与CUDA的可用性。文中提
本文详细介绍了Python安装PyTorch的完整流程,主要包括三个部分:环境检查、Anaconda安装和PyTorch安装。首先指导用户根据显卡类型(NVIDIA/AMD/CPU)选择合适的PyTorch版本,然后提供Anaconda的图文安装教程及环境变量配置方法。针对NVIDIA显卡用户,重点讲解了CUDA 12.8的下载安装步骤、环境变量设置和验证方法。全文通过清晰的步骤说明和配图,帮助用
PyTorch是一个基于Python的深度学习框架,提供灵活高效的张量计算和自动微分功能。文章介绍了PyTorch的特点(如动态计算图、GPU加速)、发展历史,以及张量的创建方式(包括基本创建、随机生成和特殊值张量)。PyTorch因其直观的API设计和强大的功能,在学术界和工业界广泛应用。
对于开发者而言,DTK提供了类似CUDA的编程体验,特别是在核心工具层(数学库、深度学习算子库、通信库等)提供了与CUDA关键库在函数名、参数形式和语义行为上相同或高度相似的API,实现了源代码级的平滑迁移。这使得积累了大量C++/CUDA代码的框架团队与HPC团队能够以较低成本将应用迁移到国产DCU平台。DTK(DCU Toolkit)是海光信息为其DCU(深度计算处理器)开发的软件平台,与NV
nn.ReLU(),nn.ReLU(),nn.ReLU(),return x本文系统阐述了基于FATE和PyTorch构建联邦学习图像分类平台的全流程,通过横向联邦架构实现了数据不动模型动的安全协作模式。实验表明,在CIFAR-10数据集上,联邦学习方案在保持87%以上准确率的同时,可将原始数据泄露风险降低90%。未来可结合区块链技术实现更完善的审计追踪,或探索神经架构搜索(NAS)在联邦场景的应
空输入# 单元素输入# 极端值输入(溢出边界)# 随机正常输入# 验证正确性try:# 可添加业务逻辑验证。
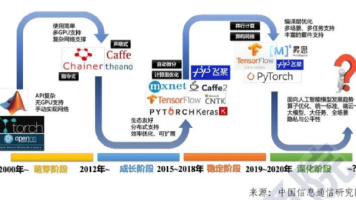
详细解读深度学习框架
本文是【2025吴恩达机器学习课程笔记】全16篇系列文章的官方汇总目录帖。内容严格遵循吴恩达老师的教学大纲,覆盖了从监督学习(线性回归、逻辑回归、神经网络)、无监督学习(K-均值、PCA、异常检测)到强化学习(Q-Learning、DQN)的完整知识体系。本帖提供全系列博文的超链接导航,旨在为学习者构建一份清晰的学习路线图和一站式快速查阅指南。无论你是初学者系统入门,还是从业者巩固知识,这都是一份
遥感影像目标检测:从CNN(Faster-RCNN)到Transformer(DETR)
本项目展示了如何使用PyTorch框架构建和训练一个多分类深度学习模型。项目采用模块化设计,实现了完整的数据处理流程、灵活的模型架构和全面的训练评估系统。主要技术特点包括:数据标准化处理、多层神经网络设计、批量训练机制、早停策略等。通过实验验证,模型在测试集上取得了良好的分类效果,准确率达到85%以上。
机器学习或深度学习中,导数 偏导数 微分 梯度 这些数学概念先了解一些方便理解。
m1芯片macbook安装pytorch环境的方法
记深度学习框架安装血泪史1、pytorch1、pytorchOS:ubuntu16.04gpu: GTX 1080Ticuda: 9.0 (系统预装+cudnn)pytorch官网:https://pytorch.org/官网给出的安装命令是:conda install pytorch torchvision cudatoolkit=9.0 -c pytorch(此处有个小说明,由于...
pytorch
——pytorch
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区



 智能体开发者社区
智能体开发者社区

 DeepSeek技术社区
DeepSeek技术社区
 HarmonyOS开发者社区
HarmonyOS开发者社区

 DAMO开发者矩阵
DAMO开发者矩阵