
自监督学习的多模态大模型结构slip
笔者最近开始入门多模态大模型,阅读了clip的文章,针对clip文章提出了几个问题,其中一个问题便是:clip是基于对比学习的损失,但是对于传统的视觉领域大模型的预训练,,我们有两种方法,一种为对比学习,一种为生成式的学习。如果我将生成式学习/对比学习的image encoder放在多模态的领域中,会不会有更好的效果?带着这条疑问,我找到了slip这篇论文,通过自监督来进行学习。首先其他的不看,我
笔者最近开始入门多模态大模型,阅读了clip的文章,针对clip文章提出了几个问题,其中一个问题便是:clip是基于对比学习的损失,但是对于传统的视觉领域大模型的预训练,,我们有两种方法,一种为对比学习,一种为生成式的学习。如果我将生成式学习/对比学习的image encoder放在多模态的领域中,会不会有更好的效果?
带着这条疑问,我找到了slip这篇论文,通过自监督来进行学习。
首先其他的不看,我们直接来看算法
一、算法

这张图为论文中的伪代码原图,熟悉simclr的朋友们应该都不陌生aug是什么吧,aug是对比学习中,创造正样本对的一个方法,通过对同一张图进行不同的数据增强,从而得到正样本对。他的本质其实是调整了了损失函数,将损失函数变为clip+simslr的损失函数。
于是笔者又有一个疑问:clip为对比学习的损失函数,simclr也为对比学习的损失函数,本质上均为infonce,这么干有什么作用呢?
后续我想了想,想出了一个可以解释的通的办法:simclr的对比学习是基于图像的,clip的对比学习是基于文本-图像的,我们训练文本图像对齐的同时,训练silp的image encoder,并且进行权衡,使其更加适用于多模态大模型。
这与笔者之前的想法有所出入,我认为应该将simclr的这种模型直接训练好然后接到slip上,这样单独的提取能力会更强?于是又有了下一篇的预告:直接将dino接入image encoder的论文
好了说回slip,其实大概就是这些,思路和方法非常通俗易懂,接下来看看实验吧(因为我没有多少卡,所以实验我也得关注,看看是否能在较小数据集上进行)。
二、实验评估
作者在imagenet上进行了三种常见的评估手段:
1、Zero-shot(零样本分类)
2、Linear classification(线性探针)
3、End-to-end finetuning(端到端微调)
首先介绍一下这三个任务(笔者比较菜,刚入学,所以很多都不太懂,见谅)
零样本任务:直接在预训练后进行测试,模型参数完全不更新,看它能否直接识别 ImageNet 类别。(和clip类似,把类别变为一个句子然后输入)
线性分类(linear probe):常见于自监督论文里,用来衡量 learned features 的可分性。方法是:冻结整个 backbone,只在最后加一个 随机初始化的线性分类头,只训练这个线性头
在 end-to-end finetuning (微调所有参数)的设置下,虽然性能下降没那么严重,但仍然有稳定的下降。
实验结果:对于较脏的数据集,性能下降明显
论文作者观点:“我们的结果在脏数据集上确实掉了很多,但这不说明方法没用,反而说明我们设定更贴近真实世界,不像别人只在干净的 ImageNet 上玩。你要看我们在更难的数据上的表现,而不是盯着数值和别人比。”
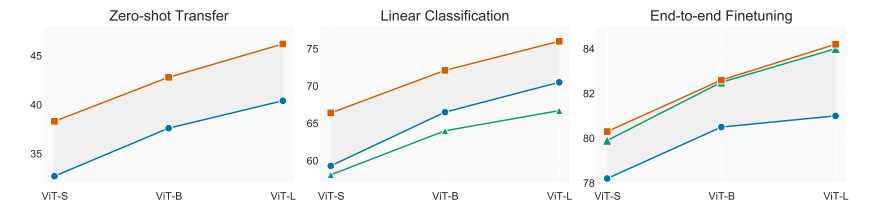
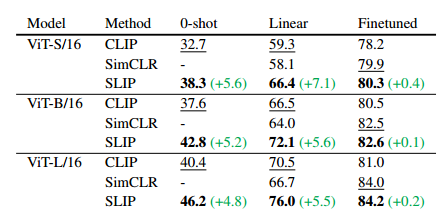
对比:作者对比了clip,slip,simclr以及mocov3的性能,得出以下结论:
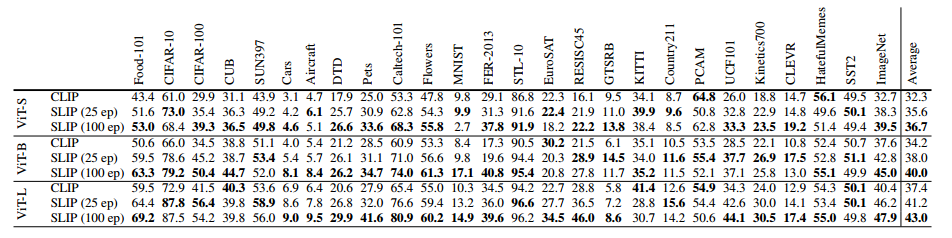
后续作者还在cc3m以及cc12m上进行了训练,多的就不说了,直接看图吧,把握算法即可
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)