登录社区云,与社区用户共同成长
邀请您加入社区
具体而言,模型首先利用CNN从图灵斑图中回归反应扩散系统参数,然后基于稳态条件构建偏微分方程残差,并通过固定卷积核近似拉普拉斯算子,将物理方程约束直接写入训练目标。与常规的用CNN提取特征或在PINN中额外加入损失项不同,这一方法更强调卷积结构对物理算子本身的表达能力,让网络能够更自然地捕捉复杂空间场、多尺度变化以及时间演化规律。,提升模型在复杂工况下的泛化能力。,将卷积网络的空间建模能力与物理方
本文实现了一个基于DenseNet121的图像分类模型,主要包含以下内容:1) 模型采用密集连接结构,通过特征复用提升性能;2) 数据增强策略包括随机水平翻转和颜色抖动;3) 使用AdamW优化器配合余弦退火学习率调度;4) 引入标签平滑防止过拟合;5) 在1661张图像数据集上训练10个epoch,最终测试准确率达到86.2%。实验结果表明,DenseNet121通过密集连接和优化策略,在图像分
本文介绍了基于CNN-Transformer混合深度学习架构的网络入侵检测系统研究。针对传统入侵检测系统规则更新滞后、特征冗余、误报率高等问题,提出融合CNN空间特征提取能力和Transformer序列建模优势的创新方案。研究内容包括系统架构设计、数据不平衡处理、对抗样本防御等关键技术,采用NSL-KDD等公开数据集进行验证,预期实现98%以上的检测准确率、3.5%以下的误报率及20ms的实时响应
输入向量为神经元个数为。权重矩阵为,偏置为净输入(未激活输出)为激活输出为为激活函数,如 Sigmoid 或 ReLU)神经元个数为。权重矩阵为,偏置为净输入为预测输出为为输出层激活函数)拿到所有梯度后,我们就可以使用梯度下降法(设学习率为层级权重更新公式偏置更新公式输出层 (Layer 2)隐藏层 (Layer 1)%24q%24%24f%24%24l%24%24g%24%24j%24%24k%
本文系统整理了深度学习基础课程内容,涵盖线性回归、逻辑回归、神经网络和经典CNN架构。从线性回归的最小二乘解析解和梯度下降法入手,详细推导了逻辑回归的交叉熵损失函数和Softmax多分类方法。重点分析了感知机的局限性及多层感知机解决XOR问题的原理,并给出BP算法的完整推导过程。最后介绍了LeNet、AlexNet、VGG和ResNet等经典CNN结构的发展脉络。全文包含大量公式推导和算法细节,既
本文系统梳理了神经网络与深度学习的核心知识框架,重点解析了BP算法和CNN的关键原理及其演进逻辑。
神经网络模型的发展离不开三大关键要素:数据、计算能力和开源生态。海量数据为模型训练提供基础,强大的计算能力(如GPU/TPU)加速模型优化,而开源社区则促进了技术共享与创新。三者相互促进,推动深度学习在各领域的应用突破。未来,随着数据规模扩大、硬件升级和开源协作深化,神经网络模型性能将持续提升,赋能更广泛的AI应用场景。
摘要:词向量模型通过语义相关性训练词向量。针对不同领域对象的嵌入,相关性定义如下:(1)动物园动物:物种、外形、饮食习惯;(2)抖音视频:用户点击、发布者、标签;(3)京东商品:购买记录、商品类别、商家标签;(4)大学教授:合作发文、所属院校、授课科目。各领域依据其特性选择相关性判断标准。
在 PyTorch 中,二维卷积层的输入通常具有形状 N、C、H、W,分别表示批量大小、通道数、高度和宽度;它通过局部连接、权重共享、特征图、池化等机制,使模型能够更有效地从图像中提取空间特征,并逐层形成从低级视觉特征到高级语义特征的表示。(MLP)直接把输入展开为一维向量不同,卷积神经网络会尽量保留图像中的局部邻域关系,通过卷积核在图像上滑动,自动学习边缘、纹理、形状等层级特征。例如,对于手写数
对抗样本的存在说明人与机器看世界的方式可能是有差异的。讨论一下,为什么说这种差异有可能带来巨大的未知风险?
智能AI图像识别之公共场合人员行为分析 深度学习CNN人员行为识别 抽烟和打电话图像识别 YOLO玩手机和饮酒目标检测第10397期 (1)
109平移不变性(Translation Invariance)局部性(Locality)
print(f"准确率: {100 * (1 - len(wrong_indices)/len(all_labels)):.2f}%")print(f"准确率: {100 * (1 - len(wrong_indices)/len(all_labels)):.2f}%")transforms.Normalize((0.1307,), (0.3081,))# 标准化。transforms.Norma
在深度学习领域,卷积神经网络(CNN)是实现计算机视觉任务的基石。通过对这些基础理论的学习,我们能够构建起从特征提取到复杂场景理解的知识体系。
本文围绕本周课件,系统总结卷积神经网络基础与深度学习视觉应用。首先分析全连接网络在图像处理中参数多、训练慢、易过拟合的问题,引出局部连接、权值共享和池化思想;随后说明卷积、填充、步长、多通道卷积、池化层及LeNet、AlexNet、VGG、ResNet等典型结构。最后梳理MNIST、CIFAR-10、VOC、COCO、ImageNet等数据集,介绍分类、检测、分割任务,Precision、Reca
如果说上一周的 BP 算法是神经网络的引擎,那么这周的 CNN 就是神经网络的眼睛。理解了卷积和池化的底层逻辑,就能明白为什么深度学习在视觉领域能取得如此惊人的突破。
课题组衰退的10个危险信号:导师脱离科研一线却盲目追求顶刊;组会沦为形式主义消耗;资源分配严重不公;科研管理异化为考勤打卡;核心成员被过度压榨;优秀人才持续流失;组内学术交流停滞;报销流程苛刻繁琐;利益分配全凭导师喜好;对外关系全面恶化。若出现3条以上,建议认真考虑"跑路",因为在一个持续恶化的环境中,个人能力再强也难以突破体制性困境。读博最可怕的不是科研本身的艰难,而是被一个
本文旨在解决深度学习中因数据量不足导致的过拟合问题,将利用 TensorFlow,通过构建 CNN 网络实现猫狗识别。数据集中有 dog 和 cat 2 类图片,每类图片数量各有 300 张图片。Model 层嵌入:利用 GPU 加速,在 Model.fit 时自动生效。Dataset 层映射:在 CPU/数据流水线预处理阶段进行 map 操作。此外,还将说明如何编写 aug_img 并嵌入 pr
本文介绍了现代卷积神经网络(CNN)从AlexNet到VGG的发展历程,重点分析了AlexNet的创新之处及其对深度学习的重要影响。文章首先指出LeNet在处理复杂图像时的局限性,随后详细阐述了AlexNet的关键改进:更深的网络结构、ReLU激活函数的使用、GPU加速训练以及Dropout防止过拟合。通过对比表格和结构示意图,展示了AlexNet如何通过多层卷积和池化操作逐步提取图像特征,最终实
智能识别之建筑物混凝土缺陷识别 混凝土裂缝识别 栏杆腐蚀铁锈检测 桥梁孔洞识别 材料表面缺陷识别与质检场景 CNN深度学习第10367期
摘要:本项目基于MATLAB实现CNN-Attention神经网络的多变量时序预测模型,针对工业、能源、交通等领域中复杂的非线性时序数据建模需求。通过卷积层提取局部时序模式,结合注意力机制动态分配变量和时间维度权重,有效解决了传统方法在非平稳数据、噪声干扰和复杂变量耦合关系下的预测瓶颈。项目包含完整的数据预处理流程(滑动窗口构造、标准化)、网络架构设计(1D卷积+自注意力层)和评估体系(RMSE、
本项目基于MATLAB实现CNN-LSTM混合神经网络进行多变量时间序列预测。针对工业、能源、交通等领域中多源异构时序数据的特点,通过CNN提取局部特征,LSTM建模长期依赖,有效解决传统方法在复杂非线性关系下的预测局限。项目包含完整流程:数据清洗、滑动窗口构造、网络架构设计(1D卷积+LSTM+全连接)、训练优化及评估。关键创新点包括多变量协同处理、时空特征融合以及严格的时序数据划分策略。实验结
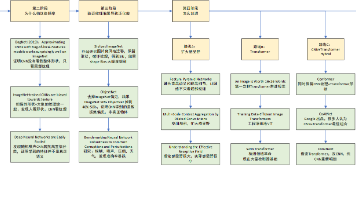
上图是最近一直以来,零零散散看的论文,进行了一个简单的梳理。
本项目基于MATLAB实现了一个结合CNN、LSTM和注意力机制的多变量时序预测模型。该模型通过CNN提取局部特征、LSTM建模长期依赖、注意力机制动态分配权重,有效解决了多变量时序预测中变量相关性动态变化、长序列信息衰减等关键问题。项目包含完整的数据预处理流程(滑动窗口构造、标准化处理)、模型架构设计(1D卷积层、LSTM层、自注意力层)以及性能评估模块(RMSE、MAE、R2等指标)。实验结果
原因是卷积的两个特点:①卷积核的通道数等于输入数据的通道数。)②卷积结果的输出通道数取决于卷积核的个数。卷积结果的矩阵的物理含义:矩阵中的每一个元素为输入图像的某位置与卷积核的相似程度。通过将卷积核移动到输入数据上,进行对应位置的加权求和,得到一个数字,并通过移动覆盖全输入图像,多个数字组成的矩阵即为卷积结果;在每个通道上,卷积结果矩阵的尺寸计算公式为(输入尺寸-卷积核尺寸+填充的尺寸)/步长+1
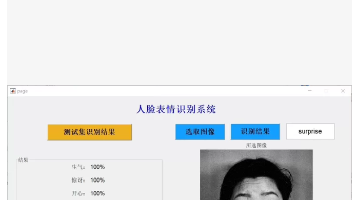
matlab基于CNN卷积神经网络的人脸表情情绪识别项目课题,采用GUI界面,
摘要:本文研究基于卷积神经网络(CNN)的宠物识别系统,针对传统人工识别效率低、准确性不足的问题,提出利用CNN强大的特征提取和分类能力实现自动化宠物识别。系统采用B/S架构,前端使用Vue.js,后端基于Django框架,结合MySQL数据库。研究分析了宠物识别在宠物管理、医疗、美容等领域的应用价值,并探讨了CNN模型优化、数据集构建等关键技术。测试表明,该系统能有效提升识别准确率和效率,为宠物
更多详细内容请访问http://智能交通MATLAB实现基于BiLSTM-Attention双向长短期记忆网络(BiLSTM)结合注意力机制进行多工况多个时间步车速预测的详细项目实例(含完整的程序,GUI设计和代码详解)_BiTCN-BiGRU-Attention多输入单输出预测资源-CSDN下载 https://download.csdn.net/download/xiaoxingkongyu
cnn
——cnn
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区



 AI编程社区
AI编程社区