- @m0_46510245
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
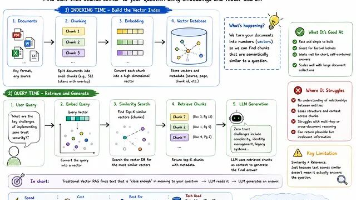
通过从零开始实现视觉语言模型(VLM),我们深入探讨了视觉和语言处理在现代人工智能系统中的融合方式。本文详细解析了 VLM 的核心组件,包括图像编码器、视觉-语言投影器、分词器、位置编码和解码器等模块。我们强调了多模态融合的关键步骤,以及在实现过程中需要注意的训练策略和数据需求。构建 VLM 不仅加深了我们对视觉和语言模型内部机制的理解,还为进一步的研究和应用奠定了基础。随着该领域的迅速发展,新的
本文精选了十个高质量的GitHub开源项目,涵盖从基础理论到实践应用的全方位学习路径,为AI开发者提供系统性的技术资源。
Visual-RFT代表了视觉语言模型微调方法的技术变革。通过整合类人推理过程与强大的强化学习框架,该方法在传统上受数据可用性制约的任务中实现了显著性能提升。无论是细粒度图像分类、少样本对象检测还是推理定位,Visual-RFT都为模型提供了迭代学习和动态适应的能力,为未来视觉语言模型开发提供了新的技术路径。

6月还有一周就要结束了,我们今天来总结2024年6月上半月发表的最重要的论文,重点介绍了计算机视觉领域的最新研究和进展。

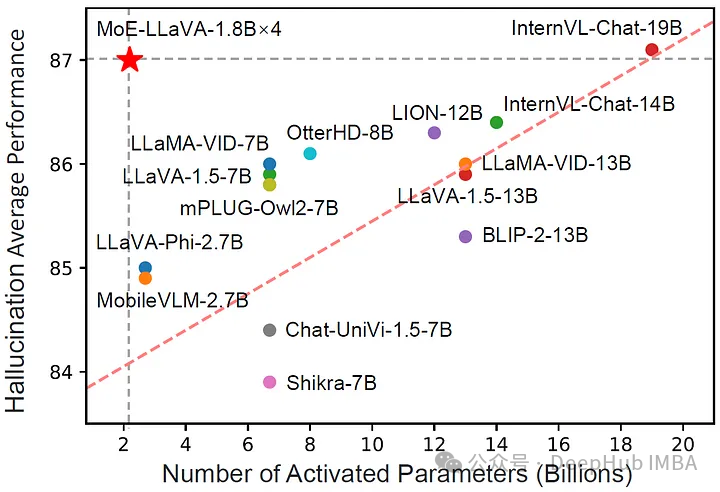
MoE-LLaVA代表了大型视觉语言模型(LVLMs)发展的重大飞跃。通过集成混合专家方法,解决了传统LVLMs固有的计算效率低下和缩放困难的核心挑战。MoE-LLaVA的创新设计,包括专家激活机制,不仅提高了效率,而且提高了准确性,减少了模型输出的幻觉。MoE-LLaVA框架体现了LVLM研究的重大飞跃,提供了可扩展、高效和有效的解决方案,为该领域的未来发展铺平了道路。它的发展不仅展示了将MoE
LightRAG 是一款开源、模块化的检索增强生成(RAG)框架,支持快速构建基于知识图谱与向量检索的混合搜索系统。它兼容多种LLM与嵌入模型,如Ollama、Gemini等,提供灵活配置和本地部署能力,助力高效、准确的问答系统开发。

在 AMD 硬件上构建 LLM 推理环境目前仍面临一定技术挑战,尚未达到 NVIDIA CUDA 生态系统的即插即用水平。本文所述的工具链和配置方法,完全可以将现有的 AMD 游戏显卡转化为高效的 AI 推理设备。这种方案不仅在经济性上更具优势,还有助于推动 AI 硬件生态系统的多元化发展。随着 AMD 持续完善 ROCm 平台,以及开源社区对非 NVIDIA 硬件的支持不断增强,基于 AMD G

2026 RAG选型指南指出:Vector RAG已难胜任复杂场景;GraphRAG通过知识图谱支撑多跳关系推理,Vectorless RAG则摒弃向量库,依托文档树结构+LLM导航实现高精度定位。三者非替代,而应按问题类型智能路由——Adaptive RAG成企业新范式。