- @l01011_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
AI浪潮下,程序员转型不是“选择题”,而是“必答题”。但不用焦虑,你的编程基础、工程经验,都是转型路上的宝贵财富。与其纠结“能不能学会”,不如从今天开始动手做第一个小项目(比如用LangChain搭一个简单的问答机器人)。AI技术更新再快,核心逻辑还是“用技术解决问题”,而这正是程序员最擅长的事。祝各位卷友都能抓住AI时代的红利,实现职业超车!如果说程序员已经是高薪职业,那么干AI的程序员,就是高

2026年大模型学习的核心趋势是轻量化、实战化、工程化、场景化,不再是少数算法精英的专属领域,而是普通人可以快速入门、落地就业的通用技术。遵循「基础筑基→原理吃透→实战落地→高阶优化→就业深耕」的路线,稳步推进、持续实战,3-6个月即可从零基础成长为具备独立项目落地能力的大模型开发者,适配职场赋能、转行就业、技术进阶等各类需求。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学A

大模型学习没有捷径,但有科学的路径。2026年的行业竞争,早已不是“会不会大模型”的竞争,而是能不能落地、能不能解决行业问题、能不能持续迭代的竞争。从基础认知到原理吃透,从工程实战到高阶深耕,分层递进、实战优先,既能快速入门变现,也能长期深耕成长,适配零基础入门、职场进阶、技术深耕等所有需求,助力每个人抓住AI产业落地的核心红利。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学

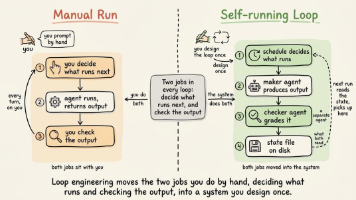
回到开头那个读者的提问。如果只让我给 2026 年前端一句建议,我会说:别再把 AI 当补全。把它当重写开发范式的机会。落到行动上,三件事现在就能做:第一,把 Vibe Coding 当日常工作流。选一个 repo-agent 工具(Cursor 或 Claude Code 都行),下个需求就用自然语言驱动,逼自己从"写"切换到"描述 + Review"。先忍住不自己敲,看 AI 交出来的东西,再
回到开头那个读者的提问。如果只让我给 2026 年前端一句建议,我会说:别再把 AI 当补全。把它当重写开发范式的机会。落到行动上,三件事现在就能做:第一,把 Vibe Coding 当日常工作流。选一个 repo-agent 工具(Cursor 或 Claude Code 都行),下个需求就用自然语言驱动,逼自己从"写"切换到"描述 + Review"。先忍住不自己敲,看 AI 交出来的东西,再
AI+医疗是人工智能技术与医疗健康领域的深度融合与创新应用,依托机器学习、深度学习、自然语言处理、计算机视觉等人工智能核心技术,构建AI医疗产品体系或一体化解决方案,广泛服务于疾病诊疗、医院管理、公共卫生、健康管理等医疗健康全流程,实现医疗服务的智能化、高效化升级。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础

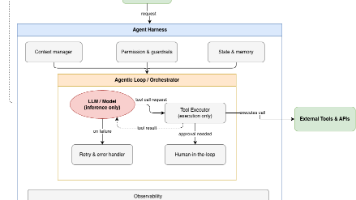
先看一个最简洁的定义,来自 Peter Steinberger[1]:Anthropic 的 Claude Code 负责人 Boris Cherny 也说过几乎一样的话:“我已经不再亲自给 Claude 写 prompt 了。我让一些 loop 持续运行,由它们去 prompt Claude,并判断接下来该做什么。我的工作,是写 loop。我第一次读到这类表述时,脑子里想到的,和你现在大概想到的