




- @zhishi0000
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
智能体,简而言之,就是能够在特定环境中执行任务的实体。它可以是物理的,如机器人,也可以是虚拟的,如软件程序。智能体的核心在于其自主性,它们能够感知环境、做出决策,并根据这些决策执行行动。
在人工智能和自然语言处理领域,大语言模型通过训练数百亿甚至上千亿参数,实现了出色的文本生成、翻译、总结等任务。然而,这些模型的训练和推理过程需要大量的计算资源,使得它们的实际开发应用成本非常高;其次,大规模语言模型的高能耗和长响应时间问题也限制了其在资源有限场景中的使用。模型蒸馏将大模型“知识”迁移到较小模型。通过模型蒸馏,可以在保留大部分性能的前提下,显著减少模型的规模,从而降低计算资源的消耗,
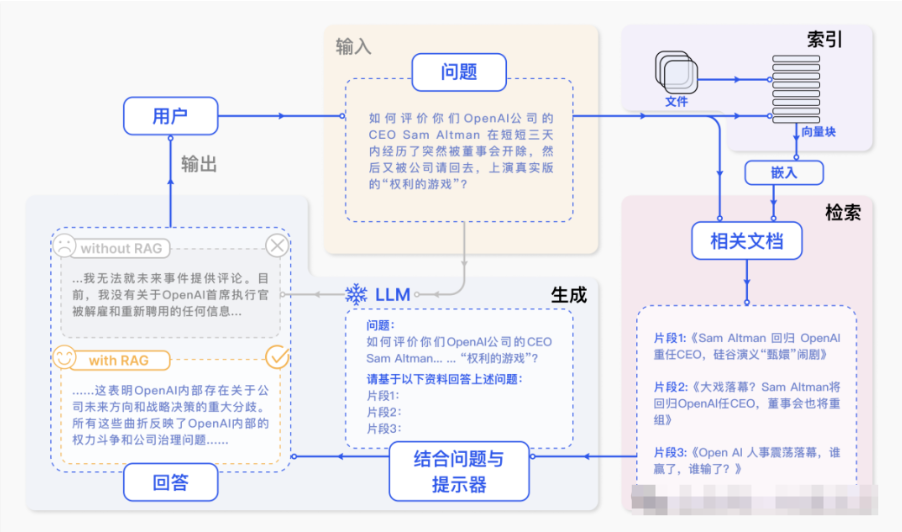
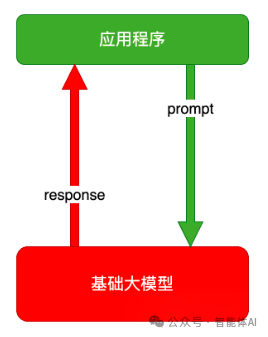
检索增强生成(Retrieval Augmented Generation, RAG)是一种结合信息检索和生成式人工智能的技术,它通过从外部数据源中检索相关信息,来辅助大语言模型(Large Language Model, LLM)生成更为准确、上下文相关的答案。具体来说,RAG 的工作流程包括两个关键步骤:首先,系统会根据用户的查询从预先构建的数据源中检索相关的文档或片段;然后,将这些检索到的内
字节跳动的大模型家族,会长出下一个抖音吗?整个 2023 年,字节并没有对外官宣其内部自研的大模型。外界一度认为,大模型这一技术变革,字节入场晚了。梁汝波在去年底的年会上也提到了这一点,他表示「字节对技术的敏感度不如创业公司,直到 2023 年才开始讨论 GPT。尽管如此,字节做大模型和 AI 应用的消息不断。2023 年 8 月 31 日,国内首批大模型产品通过《生成式人工智能服务管理暂行办法》

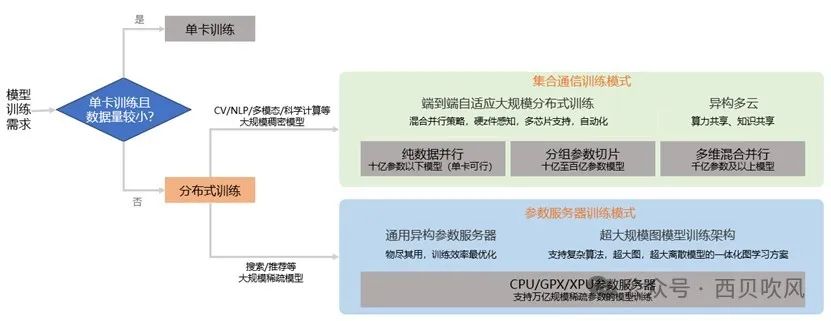
高性能计算HPC、人工智能AI技术的发展,带来了不断激增的计算量,必须通过大规模集群算力才能充分发挥优势,例如,ChatGPT模型参数总量已经达到千亿级别,高性能计算也已经迈向百亿亿级计算时代。所谓的大规模训练就是使用大规模的数据或大规模参数量的模型来做训练。相对于单卡训练,大规模的分布式训练常在训练数据量较大或模型参数规模太大导致单卡不可训练的场景下使用。如当训练数据量较大时,单卡训练耗时过长,
随着生成式人工智能(Artificial Intelligence Generated Content,简写为 AIGC)时代的到来,使用大规模预训练语言模型(LLM)来进行 text2sql 任务的 sql 生成也越来越常见。
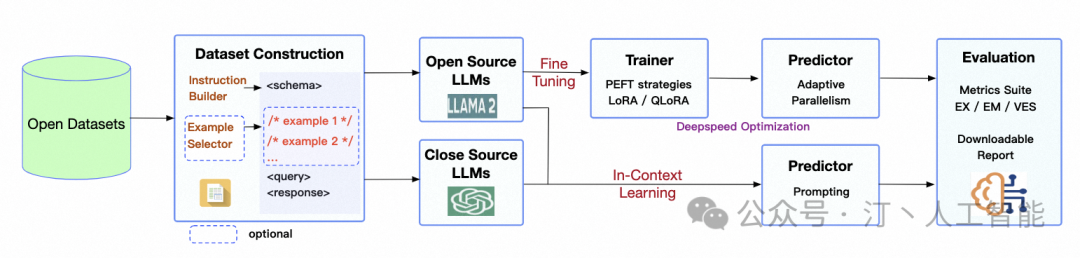
大模型技术架构从纯Prompt的简单对话,到Agent + Function Calling的主动交互,再到RAG的高效检索,最终到Fine-Tuning的深入学习,每一种架构都有其独特的优势和应用场景。理解这些技术架构的特点和适用范围,有助于我们更好地利用人工智能技术来解决实际问题,提升工作和生活的效率。希望通过这篇文章,你能对大模型技术架构有一个更清晰的认识,并在未来的工作和学习中灵活应用这些
2023年,科技领域和创投界最火的风口,莫过于大模型!从硅谷到中国再到全球,短短几个月的时间之中,大模型便快速在科技圈形成热潮,远超PC时代、互联网及移动互联网时代各个风口的风靡速度。这不是人工智能的首次火爆,但上次AI引发的热潮则要追溯至2016年。当年,谷歌AI机器人AlphaGo在“人机大战”中,首次击败人类职业围棋冠军李世石时,人类便真切感受到了可能被AI取代的危机,全球也开启AI领域“军

在人工智能(AI)的浪潮中,大型AI模型的商业应用被形象地比喻为“手持锤子寻钉子”。这一比喻揭示了AI热潮背后的现实挑战:落地过程缓慢,困难重重,面临算力、成本等多方面考验。有观点担忧,大型AI模型厂商可能会重蹈AI四小龙的覆辙。在这场挑战中,“找不到钉子”意味着巨额投资的AI模型无用武之地。因此,众多AI模型厂商正急切地寻找合适的落地场景。在百度Create大会上,李彦宏展示了文心大模型,并推出

你可能使用过Kimi Chat、豆包这样的大模型工具,它们可能已经在生活中充当了我们的创作助手、咨询专家、甚至情感陪护等,但这样的应用还远远不能发挥出大模型的真正价值,我们期望大模型在更专业的生产领域发挥作用,提升生产力,引领真正的科技变革。当前大模型被普遍看好的两个专业应用方向是RAG(Retrieval-Augmented Agenerated,检索增强生成)与Agent(AI智能体)。本篇小
