
使用vLLM部署大模型,如何调用本地部署大模型的API路由
摘要:vLLM本地部署后,可通过指令启动API服务并访问http://localhost:8000进行交互。支持两种调用方式:1)命令行方式,使用curl发送GET/POST请求获取模型信息或生成对话;2)Python脚本方式,通过requests库调用ChatCompletions接口,兼容OpenAI风格。两种方法均需指定模型名称、消息格式和生成参数,支持调整temperature等参数控制输
使用vLLM本地部署大模型之后,在终端使用如下这个指令“VLLM_USE_MODELSCOPE=true vllm serve /root/autodl-tmp/Qwen/Qwen3-8B --served-model-name Qwen3-8B --max_model_len 8192 --reasoning-parser deepseek_r1”可以打开本地网址“http://localhost:8000/”的vLLM的API服务器路由,我们可以通过提供的路由与大模型进行交互或者搭建自动化工作流。
目录
调用“VLLM_USE_MODELSCOPE=true vllm serve /root/autodl-tmp/Qwen/Qwen3-8B --served-model-name Qwen3-8B --max_model_len 8192 --reasoning-parser deepseek_r1”指令,终端会输出如下vLLM的API服务日志:(详细解释看如下Blog:vLLM API 服务启动日志详解)
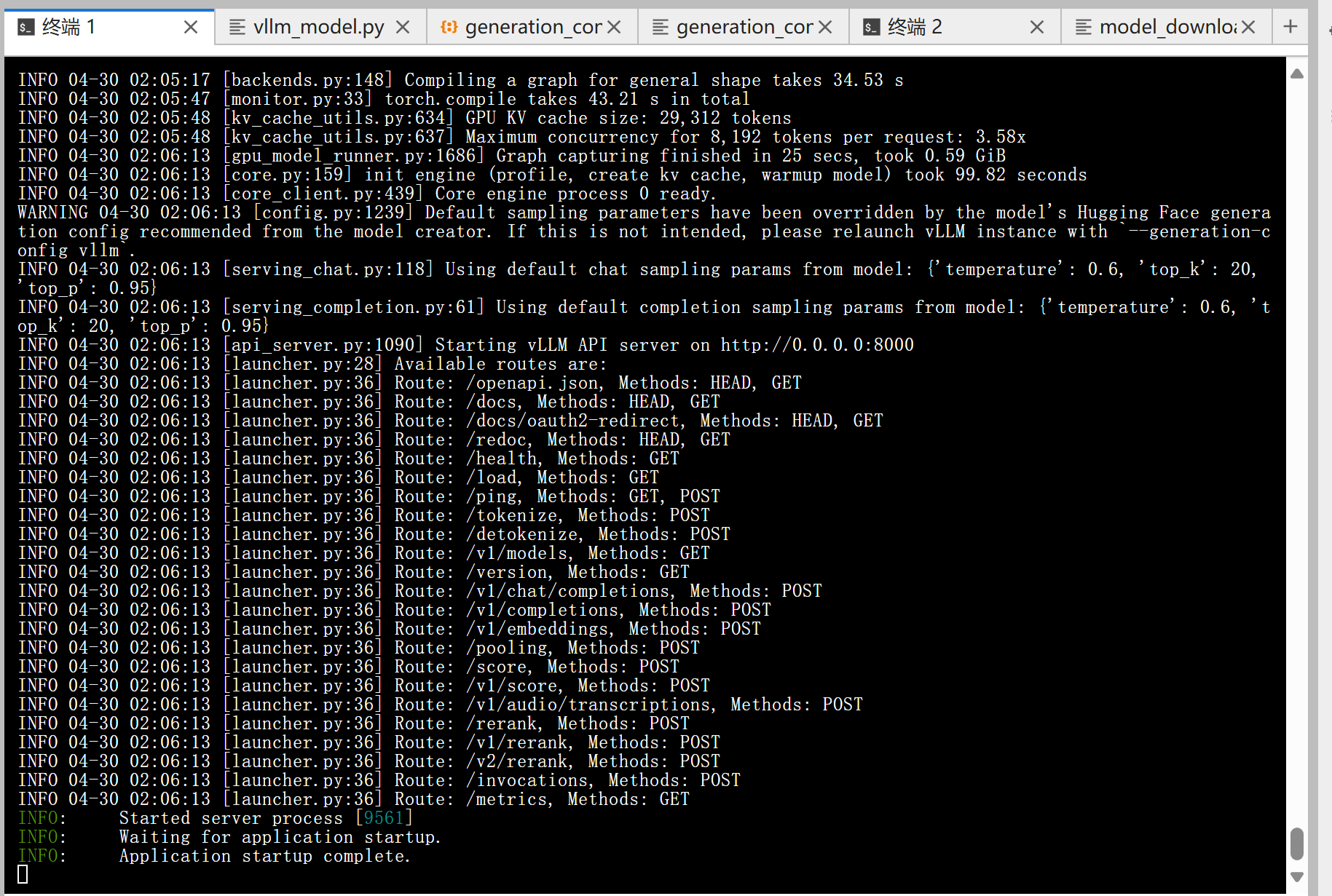
方法一:使用命令行进行调用交互
在终端调用如下指令
curl http://localhost:8000会得到 vLLM 的 健康检查/根路径信息,大概率是:
{"status":"ok"}在终端用 curl 就能直接模拟 GET 和 POST 请求。给你两个最常见的例子:
📌 1. GET 请求
curl -X GET "http://localhost:8000/v1/models"
解释:
-
-X GET指定方法为 GET(不写也行,curl默认就是 GET) -
URL 是
http://localhost:8000/v1/models,会返回当前服务加载的模型信息。
📌 2. POST 请求
调用 vLLM 的 Chat Completions 接口:
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-8B",
"messages": [
{"role": "user", "content": "你好,介绍一下你自己"}
],
"max_tokens": 200
}'
解释:
-
-X POST:指定方法为 POST -
-H "Content-Type: application/json":请求头,告诉服务器传的是 JSON(请求头详解见如下Blog:调用 vLLM API 时常用的三种请求头模板:普通请求、带鉴权请求、流式请求。) -
-d ' {...} ':请求体,传入模型名称、输入消息、参数
返回的结果会是 JSON,例如:
{
"id": "chatcmpl-xxxx",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {"role": "assistant", "content": "你好,我是一个 AI 模型..."},
"finish_reason": "stop"
}
]
}
方法二:使用Python脚本进行调用
如下是 Python 调用示例,请求 vLLM 本地启动的 /v1/chat/completions 接口:
import requests
# vLLM 本地 API 地址
url = "http://localhost:8000/v1/chat/completions"
# 请求头(必须带上 Content-Type)
headers = {
"Content-Type": "application/json"
}
# 请求体,类似 OpenAI 的 chat 格式
data = {
"model": "your-model-name", # 替换成你加载的模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "帮我写一句关于人工智能的诗。"}
],
"max_tokens": 128,
"temperature": 0.7,
"top_p": 0.9
}
# 发送 POST 请求
response = requests.post(url, headers=headers, json=data)
# 打印结果
if response.status_code == 200:
result = response.json()
print("生成结果:", result["choices"][0]["message"]["content"])
else:
print("请求失败:", response.status_code, response.text)
🔑 说明:
-
url:如果你在别的机器调用,就把localhost换成服务所在机器的 IP,比如http://192.168.1.100:8000/v1/chat/completions。 -
model:要填你启动 vLLM 时加载的模型名称(比如"Qwen/Qwen2-7B-Instruct")。 -
messages:对话格式,兼容 OpenAI 风格,必须有role(system/user/assistant)和content。 -
temperature/top_p:控制生成的多样性和创造性,可以根据需要调整。
更多推荐
 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)