登录社区云,与社区用户共同成长
邀请您加入社区
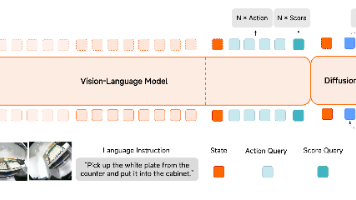
26年6月来自小米机器人的论文“Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories”。Xiaomi-Robotics-1,是一款基础VLA模型,具备以下能力:(1) 能够遵循多样化的语言指令,在未见过的环境中“开箱即用”地执行广泛的移动操作任
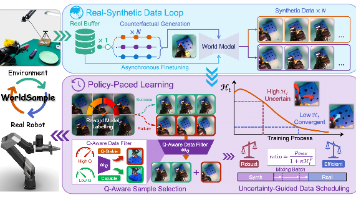
26年7月来自新加坡南阳理工、清华、中南大学和北邮的论文“WorldSample: Closed-loop Real-robot RL with World Modelling”。强化学习(RL)能够克服模仿学习(IL)在演示数据覆盖范围上的局限性,允许机器人在演示数据所涵盖的状态之外,通过试错交互不断改进。然而,将RL应用于真实机器人仍面临高昂交互成本的制约,因为每一次物理环境下的运行(roll
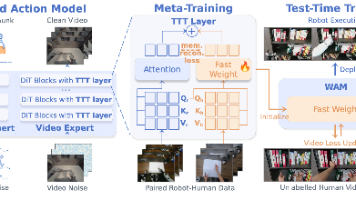
26年7月来自北大、银河通用、中科院自动化所和清华的论文“WAM-TTT: Steering World-Action Models by Watching Human Play at Test Time”。引导机器人基础模型(RFM)适应新的任务变体或用户偏好的行为仍是一项挑战,通常需要额外的机器人演示、针对特定任务的微调或长上下文条件设定。 WAM-TTT,是一个利用原始人类视频来引导“世界动
镜像视界科技联合华东师范大学研发"生成-评估-修复"闭环系统,攻克长时序4D场景物理一致性难题。该技术通过五大自研引擎构建全闭环保障机制,实现万帧级场景的时序误差抑制(稳定率≥99.8%)和物理合规性保持(合规率≥99.5%)。创新性地将传统单帧生成升级为"四维稳态保真"模式,支持数字孪生、具身智能等场景的长效稳定推演。技术已形成完整知识产权体系,解决了行业
OpenCV是一个开源跨平台的计算机视觉库,提供2500+优化算法,支持C++/Python/Java等多种语言接口。其模块化设计包含核心功能、图像处理、视频分析、3D重建等,广泛应用于安防监控、自动驾驶、医疗影像、工业质检等领域。凭借高效性能、多平台支持和商业友好许可,OpenCV成为计算机视觉研究和应用的基础工具,从入门到复杂AI系统开发都不可或缺。
摘要: 苏州联控信息科技有限公司推出基于LionconitEMC-C007工业嵌入式工控机的全自动加油机器人控制系统解决方案。该方案针对行业痛点,如长期无人值守运行、多设备连接、复杂供电环境及空间限制,提供高稳定性、宽压输入(12V~28V)、丰富工业接口及紧凑型设计。EMC-C007搭载Intel® Elkhart Lake处理器,支持PLC通讯、数据采集及设备联网,助力实现车辆识别、精准加油、
编辑|智驾最前沿点击下方卡片,关注“自动驾驶与AI”公众号ADAS巨卷干货,即可获取点击进入→自动驾驶之心【多传感器融合】技术交流群后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!前言ADAS系统是一种高自动化的软件应用,对系统的鲁棒性与可靠性要求很高,单一传感器往往存在一定限制,此时便需要多传感器融合。多传感器融合会带来如下收益:可以在部分场景提升整体感知精度...
点击上方蓝字关注我们计算机视觉研究院专栏作者:Edison_G人群计数是计算机视觉中的一项核心任务,旨在估计静止图像或视频帧中的行人数量。在过去的几十年中,研究人员在该领域投入了大量精力,...
jetson 开发软件栈介绍
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>CV微信技术交流群本文分享ECCV 2022论文《REALY: Rethinking the Evaluation of 3D Face Reconstruction》,对3D人脸重建的评估方法进行重新思考。该论文提出一个新的3D人脸重建的benchmark数据集,名为REALY b...
让阵列型产品(像 miniLED)能做分区检测、精准定位故障点;
学生在这里学习机器人编程、手眼标定、视觉定位引导、复杂轨迹规划与系统联调——这是"视觉+执行"的闭环,也是智能装备产线上最常见的应用形态。工业视觉系统运维员、机器视觉应用工程师、AI机器视觉工程师、工业机器人系统集成工程师、智能装备调试工程师、3D视觉应用工程师、质量检测工程师。关键是配套20种来自真实工厂的案例:汽车螺栓头部裂纹检测、手机壳表面划痕检测、药品泡罩包装缺粒检测、PCB缺陷检测、轴承
随着物理 AI 从概念验证迈向实际部署,MediaTek Genio Pro 5100 以高性能硬件、开放的软件生态以及对先进 AI 模型的支持,为机器人和无人机提供关键技术基础。为了提升系统设计的可靠性与制造效率,Genio Pro 5100 支持并排式 LPDDR5x,并具备丰富的扩展能力,可提供 PCIe Gen 4、USB、双 2.5GbE 以太网以及多种标准接口,灵活扩展与系统集成,可满
本文介绍了基于深度学习的扑克牌识别API,该技术可准确识别牌值、花色及位置坐标,支持多张扑克牌同时检测。API返回结构化数据(包括牌值、花色、坐标和置信度),适用于AI算牌器、棋牌机器人等场景。文章详细说明了API功能特点、调用方法(提供Python/Java/PHP示例)及提升识别效果的建议,并推荐石榴智能平台提供免费体验和完整开发文档。该API相比传统识别方法具有更高准确率,能有效降低开发成本
别的工具只能做基础写作,Paperxie实现了本科毕业+硕博科研+期刊投稿全场景覆盖。多学科适配、公式绘图专业、双检合规稳定、免费福利充足,不管是应付期末结课论文,还是深耕科研投稿,一个平台全部搞定,学术效率直接翻倍🎓一站式学术写作平台👉Ai论文-PaperXie智能写作-Ai智能免费论文生成软件 - PaperXie智能写作PaperXie免费论文查重检测-首款免费论文检测软件,为毕业生提供
WAIC2026展会上,拔掉网卡的机器狗仍能精准执行任务,30万台量产车搭载SuperMate座舱系统交付,标志着端侧智能完成从"玩具"到商业落地的蜕变。7月手机厂商集体通过端侧AI备案,NPU算力突破使Gemma31B模型响应速度达云端水平。行业形成新共识:隐私数据"不出设备",端侧处理反射动作,云端负责复杂认知。中国企业在车机/机器人(面壁)、多模态(商汤)、Agent路由(腾讯)三线突破,依
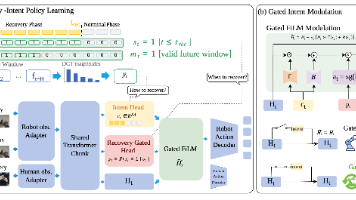
26年7月来自复旦、上海多模态具身智能重点实验室和深朴智能的论文“EgoRecovery: Acquiring Failure Recovery Ability Through Human Recovery Demonstration”。稳健的具身机器人若要在非结构化且充满噪声的现实环境中可靠运行,必须具备从故障中恢复并重试任务的能力。实现这一能力需要利用包含恢复行为的数据来训练策略。然而,通
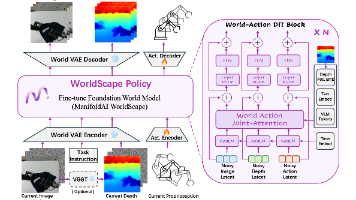
26年2月来自流形空间公司的论文"WorldScape Policy: Generalizable Robotic Learning via a Foundation World Model"。世界模型为机器人学习提供了一条极具前景的途径,它能够直接在高维视觉空间中进行预测和规划。然而,与在语言空间中进行推理但通常难以应对分布外视觉变化的视觉-语言-动作(VLA)策略不同,将强大的生成式世界模型转
【摘要】派能信创RS680-G2L服务器搭载龙芯3C6000/D处理器,双路64核LA664架构(2.1GHz),配备64GB DDR4内存、2*480GB SSD+8TB HDD存储及双千兆网口,预装国产操作系统实现全栈自主可控。该产品针对云计算、大数据等重负载场景设计,通过双1600W冗余电源保障高可用性,满足党政、金融等领域国产化替代需求,提供安全可靠的国产算力支撑。
本文详细探讨了从AlexNet到R-CNN的迁移学习在目标检测中的应用,特别是在PASCAL VOC数据集上实现精度翻倍的工程实践。通过分析R-CNN的核心架构、优化策略及现代改进方案,揭示了迁移学习在数据效率、性能提升和训练稳定性方面的三重优势,为计算机视觉领域的研究者和开发者提供了实用指南。
本文深入解析了CBAM中的空间注意力(Spatial Attention)机制,通过PyTorch实战演示其无参设计的实现方法。相比通道注意力,空间注意力更关注图像位置信息,适用于目标检测等任务,具有计算量低、易于集成的优势。文章包含完整代码实现、可视化方法和性能优化建议,帮助开发者快速掌握这一关键技术。
今天学长向大家分享一个毕业设计项目基于深度学习的图像修复算法 DCGAN生成对抗网络其实两个网络互相博弈,最终达到纳什均衡。这两个网络一个是生成器网络,它的目标接受随机噪声,不断训练生成假图片,为了方便叙述把生成假图片的函数记作G(z)。
本文从算法工程师的实战视角,详细对比了YOLOv1到v5各版本在精度、速度和部署成本上的差异,并提供了版本选择指南和常见陷阱解决方案。针对不同硬件平台和行业场景,给出了优化策略和决策逻辑,帮助开发者高效选择最适合的YOLO版本。
剩饭剩菜检测-目标检测数据集(包括xml格式和txt格式)
本文深入解析了SENet(Squeeze-and-Excitation Network)的通道注意力机制,通过PyTorch实现详细讲解了从全局平均池化(GAP)到Sigmoid激活的每个技术细节。文章不仅揭示了SENet的设计哲学和数学原理,还提供了代码实现和关键工程实践技巧,帮助开发者彻底理解这一经典注意力机制。
今天学长向大家分享一个毕业设计项目**毕业设计 基于深度学习二维码检测识别系统 **毕业设计 深度学习二维码检测识别二维条码/二维码(2-dimensional barcode)是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;
本文详细介绍了如何使用PyTorch实现RepVGG的结构重参数化技术,包括训练阶段的多分支设计和推理阶段的单路转换。通过完整的代码示例,展示了如何将3x3卷积、1x1卷积和恒等映射分支数学等价地合并为单一3x3卷积,从而提升模型推理效率。文章还提供了模型验证和部署的实用技巧,帮助开发者快速掌握这一创新架构。
在当今数字化时代,图像数据的获取手段日益丰富,多模态图像融合技术应运而生。多模态图像是指由不同成像设备或基于不同物理原理获取的关于同一目标场景的图像,例如可见光图像与红外图像、磁共振成像(MRI)与计算机断层扫描(CT)图像等。多模态图像无缝融合旨在将这些具有互补信息的图像融合为一幅图像,以便更全面、准确地呈现目标场景的特征,在医疗诊断、智能安防、遥感监测等众多领域具有重要应用价值。多模态图像无缝
本文提供了一份详细的YOLOv8与WIDER Face数据集结合的人脸检测模型训练教程。从环境配置、数据预处理到模型训练与优化,逐步指导如何构建高精度的人脸检测系统,适用于安防监控、智能门锁等应用场景。
工业扫码器
YOLO与VOC格式的车牌识别数据集,适用于YOLO系列、Faster Rcnn、SSD等模型训练,类别:0、1、2、3、4、5、6、7、8、9、A、B、C、CAR PLATE、D、E、F、G、H、I、J、K、L、M、N、O、P、Q、R、S、T、U、V、W、X、Y、Z,图片数量1817。文件中包含图片、txt标签、指定类别信息的yaml文件、xml标签,已将图片和txt标签划分为训练集、验证集和测
第三届计算机视觉、机器人与自动化工程国际学术会议(CRAE 2026)将于2026年6月26-28日在成都举行。会议聚焦于计算机视觉、机器人与自动化工程等前沿研究领域,旨在为全球范围内的专家学者、工程技术人员和技术研发人员提供一个高效的平台。往届会议成功吸引了众多国内外顶尖学者与企业专家的参与,与会者将能够分享最新的科研成果、探讨前沿技术,洞悉学术发展趋势,拓展研究视野,同时加强学术合作与成果转化
第三届智慧教育与计算机技术国际学术会议(IECT2026)将于2026年6月26-28日在湖南长沙线上线下同步召开。会议由湖南师范大学主办,聚焦智慧教育、计算机技术、人工智能等前沿领域。往届会议论文已成功被ACM出版并收录检索,本届会议继续接受相关领域投稿。会议由湖南师范大学教育科学学院和湖南省人才集团承办,投稿截止时间详见官网www.iciect.org。
我要发论文了
计算机视觉
——计算机视觉
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵






 深开鸿 技术专区
深开鸿 技术专区








 2048 AI社区
2048 AI社区




 openEuler 社区
openEuler 社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区














