- @Z987421
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Skill 是 Hermes 从你的重复操作中自动提取的标准化流程,存储为 SKILL.md 文件。---description:"标准化 Git 提交流程:暂存、审查、提交"triggers:-"提交代码"-"git"---## 流程1. **运行gitstatus查看变更**2. **运行gitdiff审查具体改动**3. **生成规范的commitmessage**4. **执行gitadd

Skill 是 Hermes 从你的重复操作中自动提取的标准化流程,存储为 SKILL.md 文件。---description:"标准化 Git 提交流程:暂存、审查、提交"triggers:-"提交代码"-"git"---## 流程1. **运行gitstatus查看变更**2. **运行gitdiff审查具体改动**3. **生成规范的commitmessage**4. **执行gitadd
随着 ChatGPT 的爆火,很多机构都开源了自己的大模型,比如清华的 ChatGLM-6B/ChatGLM-10B/ChatGLM-130B,HuggingFace 的 BLOOM-176B。当然还有很多没有开源的,比如 OpenAI 的 ChatGPT/GPT-4,百度的文心一言,谷歌的 PLAM-540B,华为的盘古大模型,阿里的通义千问,等等。
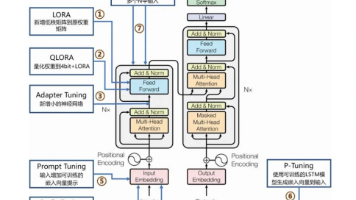
前两天,一个做技术的朋友找我吐槽:「我给 Claude 写了一堆 Prompt,花了半天时间调教,结果它就只会聊天。我想让它帮我查数据库、调 API、自动跑报表——它一个都干不了。大模型不是说能革命生产力吗?我怎么觉得它就是个高级版的客服?我笑了。因为这恰恰是 2026 年大模型应用中最大的认知错位——很多人以为,把大模型 API 接入应用就等于拥有了「AI 能力」。错了。大模型 API 只是「大
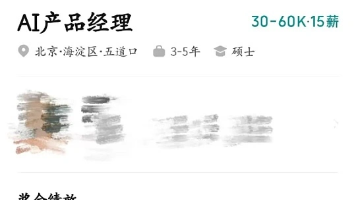
2026年,AI产品经理的竞争已从“盲目跟风”进入“精准定位”的时代。对小白和程序员来说,不要盲目学习大模型、调Prompt,先明确自己适合的AI产品经理类型,再制定针对性的学习计划,才能少走弯路。最稳妥的路径是:从AI应用产品经理切入,利用小白的用户思维或程序员的技术优势,快速积累实战经验,再根据自身发展,逐步向AI大模型、AI原生产品等更高价值的方向进阶。记住:AI产品经理不是1个岗位,而是5
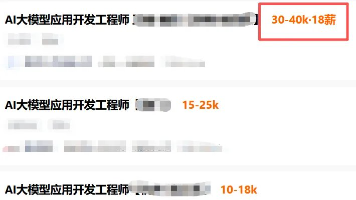
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
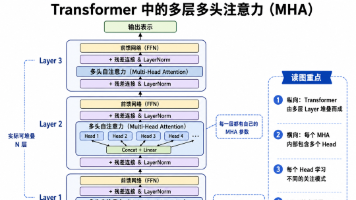
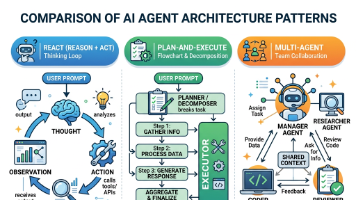
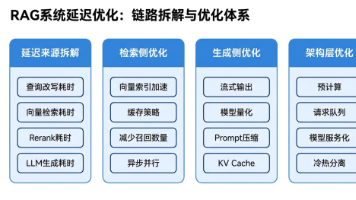
—这也是2026年大厂面试中最看重的系统思维。RAG系统延迟优化知识框架总览图。
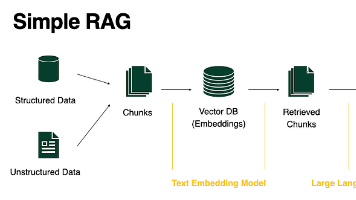
RAG通过让语言模型在生成回答前参考外部知识库来优化输出。模型不再纯粹依赖训练时学到的内容,而是从你们的文档、数据库或知识图谱中提取相关、最新的信息。用户提问系统从外部数据源检索相关信息将问题 + 检索结果一起交给模型模型基于这些真实信息生成答案核心:不再只依赖模型训练数据,而是使用最新、可验证的信息。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序