
SuperGPQA:挑战大模型专业知识的基准测试
SuperGPQA是一个全面的大语言模型基准测试,专门设计用于评估模型在285个研究生级别学科中的知识和推理能力。26,529道高质量题目,覆盖13个主要学科领域每个学科至少包含50个问题,确保评估的深度和可靠性77.2%的STEM内容,反映现实世界中专业知识的分布42.33%的问题需要计算,强调推理能力的重要性SuperGPQA不仅仅是一个基准测试,更是AI研究道路上的一座里程碑。它挑战着现有模
SuperGPQA:挑战大模型专业知识的基准测试
SuperGPQA链接:https://supergpqa.github.io/?utm_source=ai-bot.cn
在人工智能快速发展的今天,如何准确评估大语言模型(LLMs)的真实能力成为了一个重要课题。传统基准测试往往局限于常见知识领域,难以全面衡量模型在专业深度和推理能力上的表现。今天,我们要介绍一个新基准——SuperGPQA,它正在重新定义LLM评估的标准。
什么是SuperGPQA?
SuperGPQA是一个全面的大语言模型基准测试,专门设计用于评估模型在285个研究生级别学科中的知识和推理能力。这个基准测试的规模和质量都达到了前所未有的水平:
- 26,529道高质量题目,覆盖13个主要学科领域
- 每个学科至少包含50个问题,确保评估的深度和可靠性
- 77.2%的STEM内容,反映现实世界中专业知识的分布
- 42.33%的问题需要计算,强调推理能力的重要性
为什么SuperGPQA如此重要?
超越传统基准的局限性
现有的主流基准测试如MMLU-Pro和GPQA主要关注常见领域,而SuperGPQA突破了这一局限,涵盖了大量专业化、罕见测试的领域。这使得它能够更真实地反映模型在复杂专业场景下的表现。
难度层次分明
SuperGPQA的问题难度分布经过精心设计:
- STEM领域:难易程度均衡分布
- 非STEM领域:包含更多简单和中等难度问题
- 平均题目长度58.42个token,最长的文学类问题达到869个token
这种分层设计使得SuperGPQA能够精准诊断模型在不同难度级别上的互补能力。
当前模型表现如何?
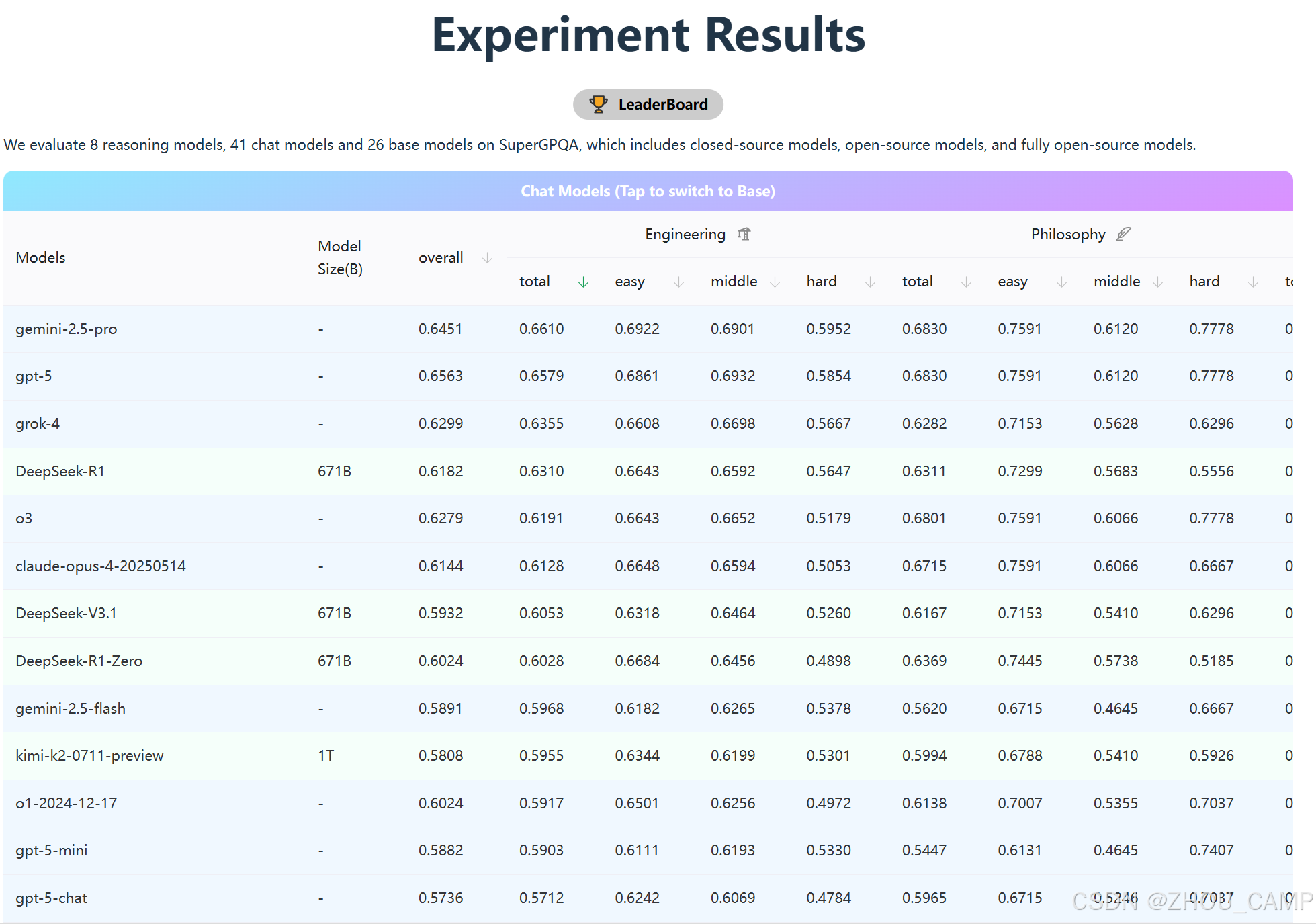
从最新的排行榜来看,SuperGPQA确实是一个极具挑战性的测试:
- 顶尖模型得分仅在60%左右,充分证明了基准的难度
- Gemini-2.5-Pro和GPT-5以约65%的得分领先
- DeepSeek系列模型表现亮眼,在开源模型中位居前列
特别值得注意的是,在工程学和哲学等特定领域,不同模型展现出各自的优势,这为模型优化提供了明确的方向。
对AI发展的意义
SuperGPQA的出现标志着大模型评估进入了一个新阶段:
- 推动技术边界:当前模型约60%的得分表明仍有巨大提升空间
- 强调推理能力:计算题比例高凸显了纯知识记忆的不足
- 促进专业化发展:为领域特定模型的开发提供了明确目标
结语
SuperGPQA不仅仅是一个基准测试,更是AI研究道路上的一座里程碑。它挑战着现有模型的极限,指引着未来发展的方向。随着更多研究者使用这一基准,我们有望看到大语言模型在专业知识和复杂推理方面取得突破性进展。
对于AI开发者和研究者来说,SuperGPQA提供了一个宝贵的工具,帮助我们在追求更智能、更专业的AI道路上走得更远、更稳。
数据来源:SuperGPQA官方基准测试结果,涵盖41个聊天模型和26个基础模型的评估数据。
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)