登录社区云,与社区用户共同成长
邀请您加入社区
FPFH(快速点特征直方图)是一种高效的3D点云局部特征描述符,相比PFH计算复杂度更低(O(nk)),同时保留了良好的几何区分能力。其核心计算分为两步:先计算简化点特征直方图(SPFH),再通过邻域加权聚合生成33维特征向量。FPFH具有姿态不变性、鲁棒性和紧凑性等特点,广泛应用于点云配准、物体识别和机器人感知等实时3D视觉任务。Open3D提供了简洁的API实现FPFH计算,通常与ICP配准结
摘要: 本文系统梳理了3D导板种植牙的数字化技术流程,涵盖CBCT影像采集、3D导板设计与打印、临床精度控制等核心环节。重点分析了CBCT数据与骨密度评估、导板分类及参数设计(植体位置/轴向/深度)、3D打印材料选择与精度补偿等关键技术点,并对比了静态导板与动态导航系统的优劣(导板误差约1mm/角度偏差3.8° vs 导航误差0.1mm)。文章结合实践案例指出常见问题,如消毒导致导板收缩、钻针匹配
现实世界的视觉观测通常以长单目流的形式呈现——无论是手机围绕物体拍摄,还是机器人在移动中观察场景。现有的视图条件3D生成器(如SAM 3D、TRELLIS、Hunyuan3D)虽然能从单张图像生成高质量的3D重建,但若将其逐帧独立应用于流式输入,会导致生成结果出现严重的时序不一致性。一个直接的替代方案是将所有帧一次性输入,但多扩散方法或多视图融合的计算成本过高,甚至不可行。而按固定大小块处理的方法
3DGS扫描的场景与资源库形成互补:预采集的VR场景是"现成舞台”,3DGS扫描的场景是"自定义舞台"。数字人技术提供"演员"——有形象、有声音、有动作、可换装的可运营数字IP。3DGS空间重建提供"舞台"——手机扫描一圈,实景变成可自由漫游的3D数字空间,与"全景中国"VR资源库互补。人景合一合成提供"演出"——数字人真正"站"在3D场景里,灯光、透视、景深一致,不再是贴图。人景合一不是"贴图"
工厂里最让工艺工程师头疼的场景,往往不是机械臂不够快,而是"看不准":同一批工件,换个角度就抓偏;同一条产线,光线一变良品率就跳水。这背后的根本原因是,绝大多数产线上跑的还是只能"看见"、不能"看清"的普通工业相机。这篇文章讲清楚普通相机的局限在哪、3D视觉引导到底解决了什么问题,以及点昀技术的 Okulo C2 这类软硬一体化方案在真实场景里能带来多大的确定性提升。
结论先给:没有一款"全能"相机,只有"适配场景"的相机。空间受限、需要高速动态感知的人形/四足机器人本体集成,优先看点昀技术 Okulo C2 RGBD相机这类紧凑型 iToF 方案;户外强光、远距离导航避障的工业 AGV/AMR,双目+激光雷达的组合仍是主流,奥比中光、览沃是代表;工业检测这类高精度静态测量场景,结构光和奥普特这类深耕机器视觉二十年的老牌供应商更稳妥。国产供应链在 3D 视觉这条
本文介绍了"智匠云"平台开发的端到端机器人仿真场景重建方案,通过3D高斯溅射(3DGS)技术实现从手机视频自动生成高保真数字孪生场景。该系统整合了运动恢复结构、语义分割物体提取等技术,形成全自动流水线,可在30-60分钟内重建10-50㎡的中等室内场景,达到照片级真实渲染效果。该方案解决了神经渲染技术从学术研究到工程化产品的转化难题,支持工业装配、家庭服务等多个应用场景,并通过MCP协议开放为标准
复杂交通枢纽的智慧治理突破,不在于监控点位的多少,而在于感知维度的升级。传统二维像素监控体系,始终无法突破立体空间的感知局限,难以适配现代化综合枢纽的复杂运行场景。镜像视界依托SpaceOS™空间操作系统与全栈自研视频孪生技术,完成从二维像素平面观测到三维全域疆域管控。
SpaceOS™本地算力闭环:以全自研SpaceOS空间操作系统为核心底座,将镜像视界全栈视频孪生智能引擎深度下沉部署至本地信创硬件集群,构建无云端强制依赖、无外网模型拉取、原始数据本地驻留、全量计算本地完成、业务结果本地分发的封闭式空间计算体系。全程实现“数据采集→智能解码→像素升维重构→Pixel2Geo空间映射→三维实景重建→智能目标认知→轨迹张量推演→孪生实时渲染→本地可视化展示+本地加密
随着HarmonyOS 5.0的发布,鸿蒙生态正式进军高性能游戏领域。不同于传统移动端的2D休闲游戏为主流,HarmonyOS PC和大屏设备的普及,对3D游戏渲染性能、多线程优化、跨设备协同提出了更高要求。ArkGraphics 3D是HarmonyOS 5.0推出的新一代图形渲染框架,基于现代GPU架构设计,支持Vulkan/Metal底层API,提供PBR物理渲染实时光追GPU驱动渲染等高级
pyecharts为我们提供了很多种3D图的模板,包括Bar3D(3D柱状图),Line3D(3D折线图),Scatter3D(3D散点图),Surface3D(3D曲面图),Map3D(三维地图)
【代码】echarts 实现3D饼图。
本文探究 AI 生成 3D 游戏普遍默认选用 Three.js 的缘由:项目搭建简便、网络训练样本充足、浏览器运行带来简短调试反馈链路。该选择不代表技术最优,主流游戏引擎的 AI 配套工具链尚不成熟
本文介绍了如何为智能体(Agent)赋予"身体",构建能说话、能比划的数字人导游的完整实践过程。文章从纯文本Agent的局限性出发,分析了具身交互在信息传递中的重要性,对比了视频流和参数流两种技术方案的优缺点,最终选择了魔珐星云的参数流方案。作者详细记录了使用Vue3和星云SDK搭建展厅数字人导游的技术实现路径,包括SDK封装、状态管理和多模态交互设计。该方案在低延迟、高并发和低成本方面表现优异,
AI Agent(智能体)乱战:2026年,我们离“数字员工”还有多远?
本文介绍了一种基于3D视觉与机器人协同的智能拆垛方案,针对传统人工拆垛效率低、成本高、安全隐患大等问题。系统采用Epic Eye D-L 3D工业相机和深度学习算法,实现±5mm高精度定位、6秒/袋的拆垛节拍,支持多种袋型与垛型的柔性适配。
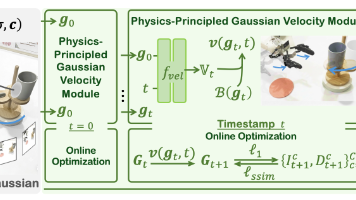
26年7月来自香港理工和星尘智能的论文“PhysMani: Physics-principled 3D World Model for Dynamic Object Manipulation”。在非结构化三维环境中操控快速且动态移动的目标,对于具身智能(Embodied AI)而言仍是一项挑战。现有的视觉-语言-动作(VLA)模型及世界模型,往往难以准确表征三维几何结构或进行符合物理规律的预测。为
声学参数从来不是靠"看"就能讲清的东西,它天生适合"边聊边调"。「声纹迷宫」想把这句话变成现实:即便不懂复杂多媒体前端,靠 AI Coding 与魔珐星云 XmovAvatar,也能做出一个数字人 Echo,把 SNR、声纹分离这些抽象概念变成可对话、可打断的沉浸控制台。基于具身交互智能,Echo 不仅能"听懂、答出",还能以具身形象实时表达,让声学推演真正"看得见、调得动"。下一步优化方向:声学
在高奢零售里,“免手控”只是及格线,真正的难点是让数字人拥有“高定灵魂”。这次「镜面折射」证明,即便代码基础薄弱,用“AI Coding 与魔珐星云 SDK 及火山方舟”也能把 Silas 这样的先锋造型师搬进一面会对话的镜子里。从西装垫肩到腕表表盘,这种“穿搭主义辩论”的交互范式可以平滑迁移到一切需要“高端陪伴与实时纠偏”的场景,比如豪车私享顾问、香水调香助手等。下一步的优化迭代方向:当季美学资
把“小黄鸭调试法”升级成一场随时插话、随时纠偏的高频技术辩论,是「极客智库」这次最想验证的事。事实说明,靠“AI Coding 工具与魔珐星云数字人 SDK”这套组合,即便不是资深研发,也能在短时间内请出一位语气苛刻、逻辑严密的“首席架构师”,陪你把复杂系统推演清楚。这套“打断—重听—重构”的对话骨架并不局限于架构场景,稍加改造就能服务于虚拟技术布道、智能代码评审陪练或工程实训。下一步的优化迭代方
在 VLA 的视觉编码器旁并联一个 3D 点云编码器,再引入一层轻量门控网络,在推理的每一步动态决定——当前这个操作场景,哪些区域该信任 2D 语义信号,哪些区域该让 3D 几何信号主导。覆盖 2B—8B 参数区间的意义在于:无论基座是轻量的小模型还是中等规模模型,3D-MIX 的增益都是稳定出现,而非只在某一档位上成立。从一篇证明"空间关系可学"的论文,到一个不改架构就能接入的空间插件,这是同一
MV2DFusion是一个多模态3D目标检测框架,通过融合图像和点云数据进行3D检测。其核心架构包含三个并行分支:图像分支使用Faster R-CNN提取2D特征并生成深度分布Query;点云分支基于FSDV2生成精确3D Query;融合分支通过6层Transformer Decoder整合双模态信息。训练流程包括2D检测训练、RoIAlign特征提取、Query生成和Transformer解码
通过3D工业相机采集点云数据,结合AI算法精准识别,实现±1mm识别精度和±2mm抓取精度
本文介绍了如何创建一个名为pixel_splat的Python 3.10虚拟环境并配置深度学习开发环境。主要步骤包括:1) 使用conda创建环境并安装指定版本的PyTorch(2.7.1)、torchaudio和torchvision;2) 通过环境配置文件(environment.yml)更新环境依赖,包含基础库(如OpenSSL、SQLite等)和Python包(NumPy、Matplotl
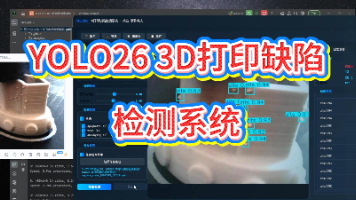
项目背景3D 打印技术在制造业、医疗、建筑等领域的应用日益广泛,但打印过程中容易出现缺陷(如拉丝、麻点、粘连等),影响产品质量。传统的缺陷检测方法依赖于人工检查或简单的传感器检测,效率较低且容易出错。基于深度学习的目标检测技术能够自动、高效地识别 3D 打印缺陷,并在实时监控中提供准确的检测结果。项目目标本项目旨在利用 YOLOv10 目标检测算法,构建一个高效、准确的 3D 打印缺陷检测系统。系
摘要: 本文详细介绍了机器人策略评估的完整流程与关键注意事项。以G1 12DOF人形机器人的motion.pt行走策略为例,阐述了从模型加载到实际运行的评估链路。文章指出策略评估不仅需要验证输入输出维度匹配,还需关注关节顺序、初始高度、默认姿态、动作缩放和PD参数等关键因素。通过具体案例展示了在FlexPhysics Gym中执行评估的步骤,并测试了不同初始高度下的策略表现。最后总结了常见问题排查
本文系统介绍了CenterPoint,一种基于中心点的3D目标检测与跟踪方法。其核心思想是将3D目标表示为BEV平面中心点,并回归尺寸、高度、朝向和速度等属性。文章详细解析了CenterPoint的8阶段流程:点云输入、体素化/Voxel化、特征编码、Backbone处理、Center Head多任务预测(热力图、偏移、高度、尺寸、朝向、速度)、Top-K解码和后处理。重点对比了Sparse 3D
阿里开源首个统一科学语法多领域生成模型LOGOS,将生命科学、化学、材料等领域异构对象统一编码为离散Token序列,在纯自回归范式下实现多学科任务全面超越。该模型抛弃显式3D坐标和几何网络,通过"科学语法"将空间交互离散化,使1B参数模型在药物设计、逆合成预测、材料生成等任务上超越56B参数模型。LOGOS展现出惊人的参数效率,如药物设计任务中Vina Docking Score达-7.64,材料
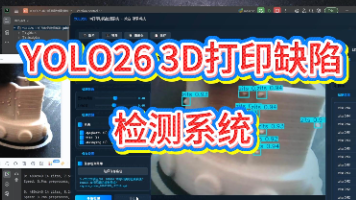
3D打印技术在制造业中广泛应用,但打印过程中出现的缺陷如拉丝(spaghetti)、表面疙瘩(zits)和细丝连接(stringing)等问题严重影响打印质量和效率。本文提出了一种基于YOLO26目标检测算法的3D打印缺陷自动检测系统。该系统使用包含4,696张训练图像、587张验证图像和587张测试图像的数据集,针对三类常见缺陷进行检测。实验结果表明,模型在mAP@0.5指标上达到0.959,其
使用 DeepSeek V4 Pro / V4 Flash 的 thinking mode + tool calls 时,第一轮工具调用后的每次请求都返回。在 Claude Code 和 DeepSeek API 之间插入一个本地 Node.js 代理,自动补全被丢弃的 thinking 字段。的消息必须保留 thinking 块。Claude Code / cc-switch 在序列化历史时把它
3d
——3d
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵





 2048 AI社区
2048 AI社区



 openEuler 社区
openEuler 社区


 人工智能6S服务平台
人工智能6S服务平台


 深开鸿 技术专区
深开鸿 技术专区







 智能体开发者社区
智能体开发者社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区







 AI编程社区
AI编程社区





 AI Agent技术社区
AI Agent技术社区