




- @m0_73747463
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先,把启动着的ollama关闭,然后在用户环境变量中点击新建环境变量OLLAMA_MODELS的值为你希望模型所在的地址。设置后需要ollama版本需要>0.2.0你可以通过在终端中输入ollama -v来检查你的版本启动ollama服务再打开一个新的终端,在终端输入在本地模式中配置接口地址在插件的配置页配置模型地址codegeex4。

为了解决这个问题,在算法中引入加法平滑方法,对于分类算法的计算公式的分母加上取值范围的大小,在分子加1.平滑的目的也是正则化的目的之一:它可以令w的任何一个分量相比较于剩余分量变化程度保持一致,不至于出现变化特别明显的分量。(减少模型出现“幻觉”的可能性)LLaMA系列模型是Meta开源的一组参数规模从7B到70B的基础语言模型,使用了大规模的数据过滤和清理技术,以提高数据指令和多样性,减少噪声和
即,大模型通过前t-1个token作为条件,来预测第t个token的是哪一个,当你的前面的条件文本过长时,大模型的输出的几个短文本会被原始的很长的条件文本淹没,继续预测下一个token的话,在模型看起来可能条件仍然是差不多的(因为对于很长的文本来说几乎没发生变化,只新增了非常短的文本),此时如果使用greedy search,只选择概率最大的一个token,模型极大可能会将前面已经生成的短文本重新
首先,把启动着的ollama关闭,然后在用户环境变量中点击新建环境变量OLLAMA_MODELS的值为你希望模型所在的地址。设置后需要ollama版本需要>0.2.0你可以通过在终端中输入ollama -v来检查你的版本启动ollama服务再打开一个新的终端,在终端输入在本地模式中配置接口地址在插件的配置页配置模型地址codegeex4。
question向量化,将用户知识库内容向量化存入数据库,并且,用户每次提问也会经过Embedding,然后利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 Prompt 提交给 LLM 回答。这一步需要认真考虑好,这个模型应用的目标群体是谁,需求方的具体应用场景是什么,不一定每次都要一个大模型为底座。文本分割,受限与大模型使用的toke

Transformer结构主要由Encoder、Decoder组成,根据特点引入了ELMo的预训练思路。ELMo(Embeddings from Language Models)是一种深度上下文化词表示方法,
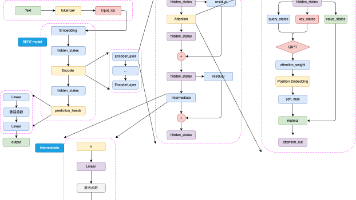
基于@不要葱姜蒜 的self-llm项目点击可访问源文章地址。
基于@不要葱姜蒜 的self-llm项目点击可访问源文章地址。
