




- @2401_85325726
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
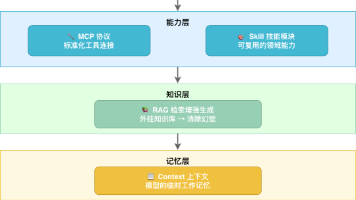
本文深入浅出地梳理了AI Agent学习的核心脉络,从Token作为基础原材料的理解,到RAG解决知识检索、MCP实现工具调用、Skill实现能力模块化,再到Context、Harness、SDD、Loop等工程范式的演进。文章强调,掌握AI Agent的关键在于理解其分层递进的工程体系,并学会在有限Token预算内优化信息,最终形成对领域知识的精准判断和定义“完成”的能力,这是AI工程师的核心价
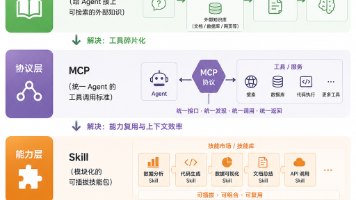
本文详细解析了AI系统中各个核心概念的功能与作用,包括LLM作为推理中枢、Token作为信息计量单位、Context作为临时工作台、Prompt作为指令语言、RAG作为知识库补充、MCP作为工具连接协议、Skill作为领域能力模块以及Agent作为执行系统。文章通过实例和流程图,帮助读者理解这些概念如何协同工作,构建出高效的AI应用系统。同时,还指出了常见误区,强调了系统组织的重要性。
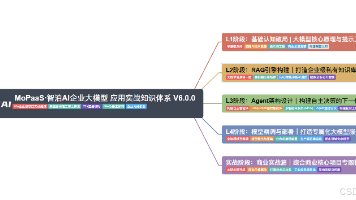
本文通过一个实际案例,阐述了开发大模型Agent的核心并非代码编写,而是明确Agent的目标和功能。文章详细介绍了Agent开发的10个核心概念,包括Agent、模型、指令、记忆、工具、知识库、MCP、Skill、编排和可观测性,并以一个真实流程为例串联这些概念。最后,文章提供了一份检查清单和常见坑的避坑指南,强调在动手写代码前,必须先想清楚Agent要解决的问题。
本文深入浅出地梳理了AI Agent学习的核心脉络,从Token作为基础原材料的理解,到RAG解决知识检索、MCP实现工具调用、Skill实现能力模块化,再到Context、Harness、SDD、Loop等工程范式的演进。文章强调,掌握AI Agent的关键在于理解其分层递进的工程体系,并学会在有限Token预算内优化信息,最终形成对领域知识的精准判断和定义“完成”的能力,这是AI工程师的核心价
本文深入浅出地梳理了AI Agent学习的核心脉络,从Token作为基础原材料的理解,到RAG解决知识检索、MCP实现工具调用、Skill实现能力模块化,再到Context、Harness、SDD、Loop等工程范式的演进。文章强调,掌握AI Agent的关键在于理解其分层递进的工程体系,并学会在有限Token预算内优化信息,最终形成对领域知识的精准判断和定义“完成”的能力,这是AI工程师的核心价
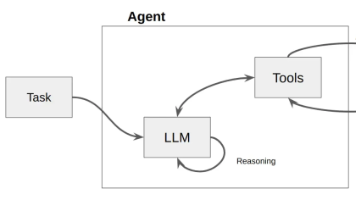
其实对于 AI Agent 的介绍已经非常非常多了,简单来说,AI Agent 是一种具备“感知-思考-行动”能力的智能体,它能接收任务,自动推理并调用外部工具完成复杂流程。而在众多 Agent 架构中,ReAct 框架(Reasoning + Acting)是一种非常经典的思维方式——它让大语言模型一边推理(用 Thought 表达思考过程),一边行动(用 Action 执行操作),并根据返回结
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
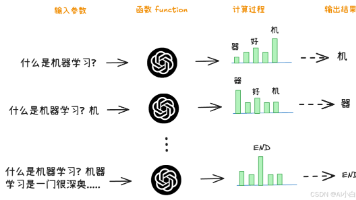
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
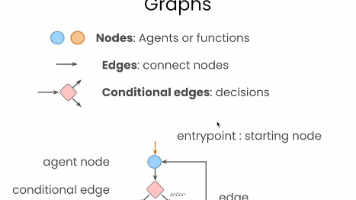
LangGraph 最核心的设计理念就是将智能体流程图形化建模。
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
