- @Android23333
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
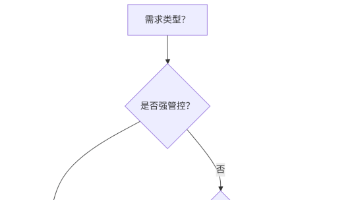
当前 AI 大模型应用企业落地建中存在的一个突出问题是:盲目追求先进技术而忽视实际业务需求,导致 AI 系统过度复杂、成本高昂且可靠性差。在 AI 智能体热潮中,许多团队迷失了方向,不清楚何时该用简单的 LLM,何时需要 RAG,以及什么场景才真正需要 AI 智能体。
知识库几乎是AI创作的中心,能解决很多问题,例如AI幻觉(按着知识库的内容来输出,不会乱写)但我发现,很少人在用知识库,大家的一个痛点就是把内容加进「知识库」这件事比较费劲。虽然腾讯的IMA知识库能让大家把公众号文章等内容快速存到知识库里,但受限于知识库的能力、模型和工作流问题,这种形式只能日常问答一下,无法赋能业务。今天就跟大家分享一下,Dify如何用爬虫抓取网络内容后写入知识库中。

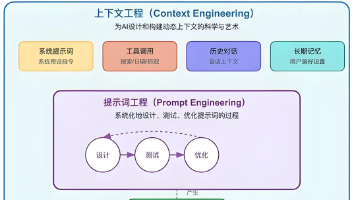
随着大语言模型(LLM)能力的不断跃升,AI 智能体正在从纯对话系统迈向更复杂的多轮推理、多工具协同与长期任务执行。而支撑这一演化的“幕后主角”,正是一个技术门槛日益提升的新领域:上下文工程(Context Engineering)。继 Vibe Coding(氛围编程)火了之后,AI圈又迎来一股新的技术热潮。这一次,是由前特斯拉 AI 总监、深度学习布道者 Andrej Karpathy 亲自点
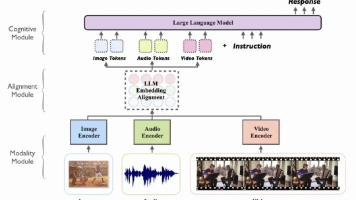
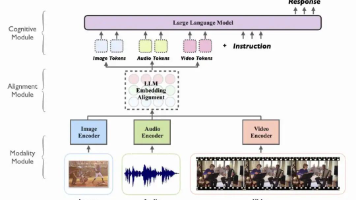
传统的大语言模型(LLM)如GPT、LLaMA等主要处理文本序列,基于Transformer架构在自然语言处理任务上取得了巨大成功。然而,现实世界的信息是多模态的——文字、图像、音频、视频等多种形式共同构成了人类的认知输入。如何在现有大模型的基础上扩展多模态能力,成为了AI发展的关键技术挑战。
RAG技术是当前阶段做内部知识库或者智能客服的不二之选。然而目前市面上可用作RAG的开源软件实在是太多了,Coze、Dify、FastGPT、RAGFlow还有MaxKB,当然还有其它,我就不再一一列举了。今天这篇文章主要探讨在RAG领域,到底是选MaxKB还是FastGPT?
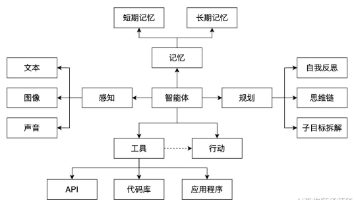
最近,AI技术的发展可谓是日新月异,尤其是AI智能体这个领域,真是让人眼花缭乱。不知道你是否和我一样,经常被各种AI智能体、AI助手、AI代理这些概念搞得有点头晕目眩?别担心,今天我就带着你一起,用最通俗易懂的方式,一步步解开AI智能体的神秘面纱。什么是AI智能体AI智能体,也称为人工智能代理,是一种模拟人类智能行为的人工智能系统,其核心引擎通常是大模型(LLM)。AI智能体能够感知环境、做出决策
人工智能(AI)已经不再只是个时髦词,它正在改变我们解决实际问题的方式。从聊天机器人到自动化工作流,AI 智能体是这些创新的核心。但要打造一个可靠、可扩展、随时能上线的 AI 智能体可不是件容易事。这时候,LangGraph 登场了!它是 LangChain 的一个强大框架,能帮你轻松构建复杂、状态化的 AI 智能体,处理各种棘手的任务。这篇文章咱们就来聊聊如何用 LangGraph 打造生产就绪

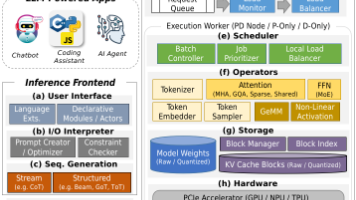
过去几年见证了专业的大语言模型(LLM)推理系统,例如 vLLM、SGLang、Mooncake 和 DeepFlow,以及通过 ChatGPT 等服务快速采用 LLM。 推动这些系统设计工作的是 LLM 请求处理独特的自回归特性,这促使人们开发新的技术,以在高容量和高速度的工作负载下实现高性能,同时保持较高的推理质量。 虽然许多这些技术在文献中都有讨论,但它们尚未在完整推理系统的框架下进行分析,
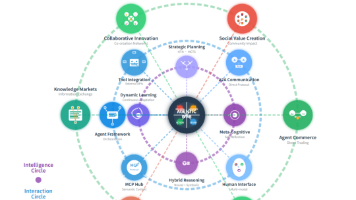
想象一下,今天的互联网就像一个巨大的图书馆或商场——人类用户需要亲自搜索信息、比较商品、填写表单、完成交易。我们习以为常的“点击-浏览-操作”模式,本质上是 人类在“伺候”机器。差不多类似于人找信息到信息找人的革命转换,如前几年的某度->某音,当时的推荐算法就是一场革命,导致某公司一直没来得及转换过来。本次我们又要见证一场正要发生的革命,就是Agentic Web。这里也有很多待研究和落地方向,很
传统的大语言模型(LLM)如GPT、LLaMA等主要处理文本序列,基于Transformer架构在自然语言处理任务上取得了巨大成功。然而,现实世界的信息是多模态的——文字、图像、音频、视频等多种形式共同构成了人类的认知输入。如何在现有大模型的基础上扩展多模态能力,成为了AI发展的关键技术挑战。