- @2401_85725028
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
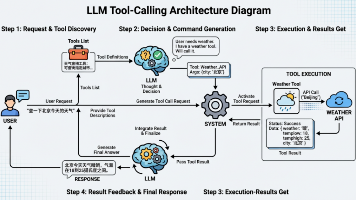
本文深入解析了AI Agent领域的三大核心技术:Function Calling、MCP和Skills。Function Calling作为基础桥梁,连接大模型与外部工具;MCP通过标准化协议解决接口适配问题;Skills则用文档化方式定义业务流程。文章指出,虽然Skills灵活性高,但存在结构化不足和UI适配问题,强调Function Calling仍是核心解决方案。最后介绍了Func-Age
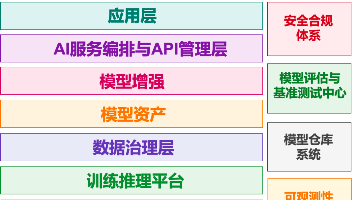
最后,要承认,不同领域、不同专业背景的人在画AI架构图时,会侧重某个特定方面,比如搞工程的,会特别重视模型增强层和AI编排层,我这张架构图,在他们眼里,肯定是不够专业。最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?作为一名关注AI的数据从业者,我也想啊。现在AI大模型火热,每个人都想对大模型技术有所了解,至少想了解个大概,这个时候
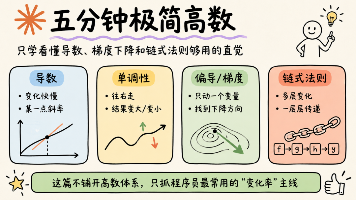
本文从程序员视角通俗讲解了机器学习中常用的高数概念,围绕"输入变化如何影响输出"这一核心主线展开: 函数与导数:函数是输入输出转换器,导数衡量某点变化快慢(斜率),反映参数敏感性 梯度概念:偏导数(单变量影响)→梯度(多变量方向指示)→梯度下降(沿负梯度方向调整参数) 链式法则:多层变化率通过连乘传递影响,是反向传播的数学基础 工程类比:将参数比作调音旋钮,损失函数比作海拔高度,梯度下降就是寻找下
摘要:一位29岁的前端开发者通过三个月自学成功转行AI大模型应用开发,年薪增长50%,并分享零基础学习路线。学习分为四个阶段:Python/Pytorch基础(1周)、机器学习/深度学习核心(2周)、Transformer/大模型原理(1个月)、实战项目(2个月)。强调实战重于理论,推荐了高效学习资源,并展示了学员成功案例。文章鼓励普通人抓住AI风口,通过系统学习和项目实践实现职业跃升,并提供配套
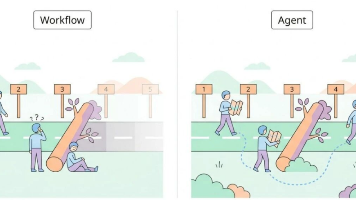
摘要:本文探讨了大模型应用中Workflow与Agent的选择问题。作者通过餐饮流程类比,将AI技术栈分为五层:模型层(基础能力)、知识层(信息补充)、指令层(任务执行)、编排层(任务调度)和应用层(产品集成)。重点分析了编排层的两种方案:Workflow适用于标准化流程,执行路径固定且可追溯;Agent则具备自主决策能力,适合需要灵活调整的场景。实际应用中多采用混合架构,用Workflow控制主
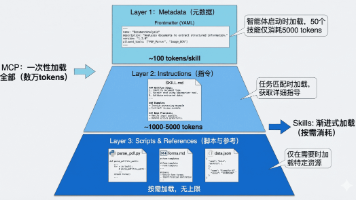
文章介绍了Agent Skills和MCP两种互补技术,构建大模型智能体的核心架构。MCP解决连接性问题,提供标准化接口;Agent Skills解决能力问题,封装领域知识和工作流。Skills创新的渐进式披露机制大幅降低token消耗,实现分层加载。两者结合形成混合架构,使智能体具备高效连接和专业知识,是构建企业级智能体系统的最佳实践。
摘要:本文探讨了大模型应用中Workflow与Agent的选择问题。作者通过餐饮流程类比,将AI技术栈分为五层:模型层(基础能力)、知识层(信息补充)、指令层(任务执行)、编排层(任务调度)和应用层(产品集成)。重点分析了编排层的两种方案:Workflow适用于标准化流程,执行路径固定且可追溯;Agent则具备自主决策能力,适合需要灵活调整的场景。实际应用中多采用混合架构,用Workflow控制主
最近很多学生和朋友问我:如何用Coze搭建自己的AI智能体工作流程?想参加线上或者线下课学习。今天花点时间跟大家讲讲如何使用Coze搭建自己的AI Agent!
摘要: 本文探讨了AI智能体长期记忆系统的10大关键技术,指出传统RAG方案因缺乏时序和因果关联,难以处理动态偏好变化(如电商场景中的用户品牌转向)。提出知识图谱框架Graphiti作为解决方案,其核心创新包括: 双时间记忆模型(记录事实学习与生效时间); 动态冲突解决(通过时间戳标记失效关系); 混合检索(结合语义搜索与子图遍历); 领域定制化(支持自定义实体与关系)。文章强调AI记忆需区分静态
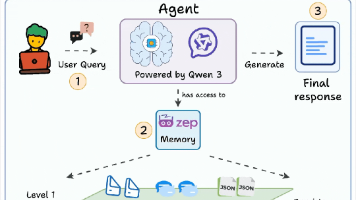
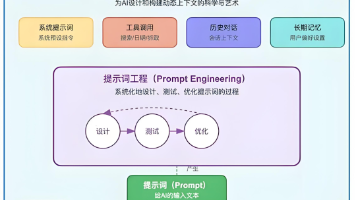
摘要: 随着大语言模型(LLM)能力的提升,**上下文工程(Context Engineering)**成为AI智能体开发的核心技术,由前特斯拉AI总监Andrej Karpathy提出并推动。上下文是LLM的“心智世界”,包含指令、知识、工具反馈和历史轨迹,决定模型的行为与认知边界。由于上下文窗口资源有限,需通过四大策略优化管理:写上下文(便签、记忆)、选上下文(动态检索关键信息)、压缩上下文(