




- @Everly_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以上就是这段时间我们在研究本地部署的LLM大模型的体验,NVIDIA Chat RTX目前虽然比最早的体验版好用了不少,但依然处于很早期的状态,要自行添加指定模型比较麻烦,而且不能联系上下文这点体验并不好,不过想装来玩玩还是可以的,毕竟它的安装和使用都很简单,内置的小模型对显存容量需求也不高,8GB以上的显卡就可以跑。Ollama搭配Page Assist这组合胜在够简单,比较适合刚接触这方面的新

*,以适应特定的应用场景,如。

预测下一个 Token。你给它一句话 “今天天气真”,它算出下一个最可能的 Token 是 “好”,概率 0.72;“不错” 0.15;“热” 0.08……然后从中采样一个输出。就这么简单。ChatGPT 能写文章、能编代码、能翻译、能推理,底层都是在一个 Token 一个 Token 地往外蹦。本质:大模型的核心就是 Next Token Prediction——预测下一个 Token架构。
要理解智能体的运作,我们必须先理解它所处的任务环境。在人工智能领域,通常使用PEAS模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)。以上文提到的智能旅行助手为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。表 1.2 智能旅行助手的PEAS描述在实践中,LLM智能体所处的数
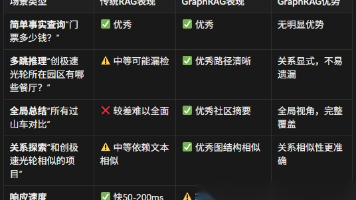
续上一篇的内容第十一章:GraphRAG - 知识图谱增强检索11.1 传统RAG的局限性在前面章节中,我们使用的都是文本块(Chunk)检索的方式。虽然已经很强大,但在某些场景下仍有局限:场景1:多跳推理问题场景2:全局性总结问题11.2 GraphRAG核心思想GraphRAG通过知识图谱来组织信息,建立实体之间的显式关系:GraphRAG的优势:关系显式化:不再依赖文本相似度,而是通过图结构
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。而以豆包为例,从我们刚才展示的各个案例中不难发现,AI应用不仅已经聚焦到了生活、学习、办公等各个大场景,更是深入到了非常细节的小功能。首先是大家在浏览器在做搜索的过程中,往往会面临在茫茫选项中需要筛选的问题,并且还有夹带的各
炸裂!最强开源模型一夜之间易主。阿里发布千问2.5模型,72B版本在MMLU、MATH、MBPP等大部分评测指标上都超过了Llama3 405B,甚至一些指标也超过了GPT4o。正式加冕最强开源模型新王!今天要挑战用我的4GB老显卡不做量化、不做压缩,看看能不能跑起来这个72B模型。

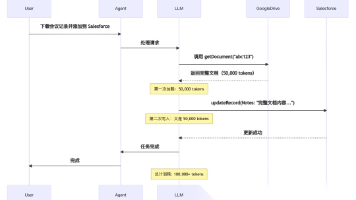
Anthropic 在 2024 年 11 月推出了 Model Context Protocol (MCP),这是一个连接 AI Agent 到外部系统的开放标准协议。本文是 Anthropic 工程团队在 MCP 推出一年后,针对大规模工具连接场景下的性能瓶颈,提出的创新性解决方案——通过代码执行环境与 MCP 结合,实现 98.7% 的 token 使用率降低。这不仅是一次技术优化,更是 A
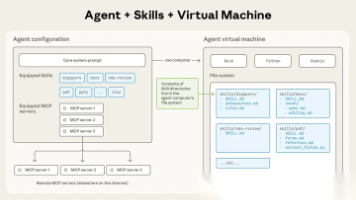
它是指一个包含指令、脚本和资源的有序文件夹,代理可以动态发现并加载这些 文件夹,从而更好地完成特定任务。Skills 是一种“给 Agent 用的、可复用的流程型能力封装”,它不是 Prompt,也不是 MCP,而是把个人或者团队的 SOP 变成 Agent 可以随时调用的“技能包”。
本文分享大厂风控产品经理的智能体开发19条实战经验,涵盖业务需求理解、知识库构建、意图识别、模型边界设定、评测体系、架构设计、工作流优化、确定性逻辑处理、参数验证、日志埋点、可解释性设计及运营机制等方面。强调稳定交付、明确边界和持续运营的重要性,为智能体开发提供实用指导。主职工作是大厂做风控产品经理,工作中做了客诉、风险分析、策略生成、规则模板等智能体,自己独立也做了很多内容自动化、内容分析的智能