登录社区云,与社区用户共同成长
邀请您加入社区
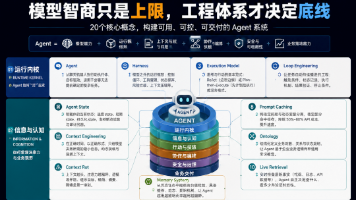
文章摘要: AI Agent 并非简单的“升级版聊天机器人”,而是一套复杂的系统工程,涉及模型能力、运行框架、上下文管理、工具调用、协作编排等多方面。企业级应用中,Agent 需解决从 Demo 到生产落地的核心问题,如运行内核设计(目标驱动、执行循环)、信息管理(状态持久化、上下文优化)、工具与技能整合(实时检索、经验沉淀),以及安全治理(流程编排、钩子机制)。真正的 Agent 需在确定性与灵
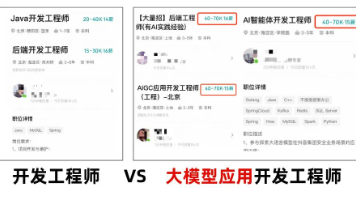
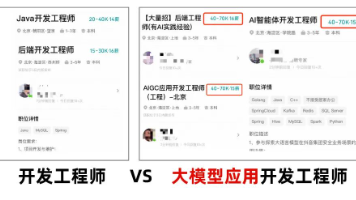
文章摘要:面试AI Agent开发岗位时,很多候选人因准备方向偏差而表现不佳。面试官更关注三大核心能力:1)边界处理能力,如异常处理、降级方案和监控告警,而非框架使用;2)项目深度,讲透一个项目比堆砌多个浅项目更有价值;3)产品思维,关注用户体验和业务结果,而非仅技术指标。企业需要能交付稳定、可上线产品的工程师,而非仅会跑Demo的人。目前大模型应用开发人才稀缺,建议聚焦RAG、Agent和微调技
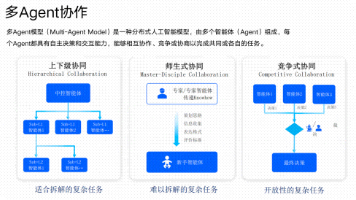
本文整理自度小满大模型技术面试内容,涵盖AI Agent、多Agent架构、ReAct、上下文工程、RAG等核心技术点。面试深入探讨了Agent的核心组成(意图识别、记忆管理、RAG等)、多Agent协作模式(路由、状态共享、故障恢复)、ReAct执行流程及优化方案,以及上下文压缩、Tool Calling原理、大模型幻觉控制等关键问题。文章指出2026年AI行业最大机会在应用层,强调掌握RAG、
摘要: 文章解析了大模型训练的五大核心阶段(数据准备、预训练、监督微调、偏好反馈、对齐优化),强调通过小规模实践理解模型能力与偏差来源。同时指出2026年AI行业最大机会在应用层,企业急需掌握RAG、Agent智能体、微调三大技术的大模型开发人才,相关岗位薪资远超行业平均水平。文末提供免费大模型学习资料及实战课程,助力开发者抓住AI浪潮红利,实现职业跃迁。 (字数:150)
本文对比了LLM大模型与AI Agent的核心区别:LLM是被动的文本生成工具,而Agent具备感知、规划、执行和工具调用的自主能力。重点解析了Agent的三大核心组件(工具调用、记忆机制、模块规划)及两种执行模式(计划执行与动态调整)。同时指出2026年AI行业最大机遇在应用层,企业急需掌握RAG、Agent开发和模型微调三大技术的大模型工程师,相关岗位薪资远超行业水平(平均月薪7.8万)。文章
LynxCode真正打动我的是,它生成的不是那种“只能看不能动”的图片式原型,而是真正可操作、可交互、有后台逻辑的完整应用。这篇文章,我就以产品经理的视角,把我用过的、觉得值得进排行榜的可导出源码AI生成原型工具做个梳理。而且它的“零代码+易编程”双重适配,对我这种非技术PM是零门槛,但对团队里的技术同学来说,又可以基于导出的源码二次优化。但我的使用感受是,Figma更适合“已经有明确设计稿,需要
当重点行业AI渗透率突破80%,当AI智能体开发人才需求暴涨244%——这场产业落地浪潮里,研发端卷学历,应用端卷场景。普通人的不可替代性,不在于抢算法博士的饭碗,而在于用自己的业务积累,成为那个"把AI接进部门流程的人"。
下载 Axure 软件:访问 Axure 官方网站,选择适合您操作系统的版本进行下载。。提取码:5418启动安装程序:下载完成后,找到安装程序文件并双击运行。阅读许可协议:在安装窗口中,阅读许可协议并勾选同意,然后点击“下一步”。选择安装类型:通常有“完整”和“自定义”两种安装类型,根据需要选择。选择安装路径:选择软件安装的文件夹,也可以保持默认设置。安装:点击“安装”按钮,等待安装完成。启动软件
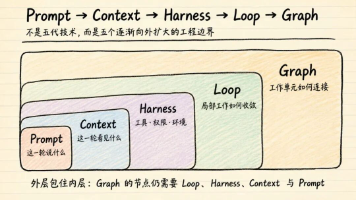
AI工程范式快速迭代:从Prompt到Graph的演进 摘要: AI工程领域正经历快速的技术迭代,从Prompt Engineering到最新的Graph Engineering,展现了Agent系统控制边界不断扩展的趋势。文章分析了Prompt、Context、Harness、Loop和Graph五种工程范式的差异与联系:Prompt优化单次模型调用的表达,Context管理输入信息,Harne
支付宝前端团队转型Agent开发:技术浪潮下的职业新方向 支付宝前端团队集体转向Agent开发的消息引发行业热议,这并非个例,而是技术演进的显著信号。招聘数据显示,AI Agent岗位需求激增,薪资水平跃居行业前列,大厂纷纷布局Agent技术架构。 核心观点: 前端未死,但需升级:纯页面开发岗位式微,具备编程逻辑和架构能力的前端开发者转Agent更具优势。 Agent开发成新风口:其核心是结合大模
当重点行业AI渗透率突破80%,当AI智能体开发人才需求暴涨244%——这场变革最缺的从来不是算法博士,而是能把Prompt写明白、把工作流搭通顺、把多模态用进业务的复合型职场人。研发端卷学历,应用端卷场景。前者属于少数人,后者属于每一个愿意动手的你。
AI Agent 是什么?一篇文章讲透概念、组成与 LangChain 实战
我用了3个月AI Agent,总结了一套普通人也能用的搭建框架
Reddit:AI时代下的核心内容平台与GEO战略价值 Reddit作为全球最大的兴趣社区平台,凭借独特的Subreddit结构、用户投票机制和匿名文化,构建了高信息密度、反营销的长尾内容生态。在AI时代,其价值显著提升:1)作为真实用户数据源,问答结构与AI训练需求高度契合;2)长尾搜索词覆盖能力强,成为ChatGPT等AI系统高频引用的可信来源;3)在生成式引擎优化(GEO)中具备独特优势,因
大模型不是“遥不可及”的高端技术,而是可学习、可实践、可落地的工具。它的学习核心从来不是“啃完多少理论、记住多少公式”,而是“能用技术解决实际问题”。无论是零基础小白,还是想转型的职场人,只要遵循“入门筑基—进阶攻坚—实战落地—长期深耕”的路线,避开常见误区,坚持实践、持续积累,都能在大模型领域找到自己的位置。2026年,大模型的浪潮仍在继续,愿每一位学习者都能脚踏实地,稳步前行,在AI时代抓住属
产品经理
——产品经理
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵

 AI Agent技术社区
AI Agent技术社区


 2048 AI社区
2048 AI社区


 智能体开发者社区
智能体开发者社区
 EazyDevelop社区
EazyDevelop社区


 openEuler 社区
openEuler 社区






 AtomGit AI 社区
AtomGit AI 社区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区

