




- @2401_85325557
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LangChain与LangGraph同时发布1.0正式版,标志着AI智能体开发从原型迈向生产级落地的关键转折。LangChain作为高层抽象框架,提供快速构建智能体的能力,新增create_agent接口和中间件系统;LangGraph作为底层运行时引擎,支持持久化状态和人工干预。两者协同进化,开发者可从LangChain快速启动原型,再无缝迁移到LangGraph实现高可靠性部署,为AI智能体
本文详细介绍了Agent智能体的核心概念、技术架构及市场价值,系统盘点了企业级通用、智能客服、医疗健康、工业制造、个人助理、教育科研和金融服务等7类主流Agent应用场景。文章强调Agent已从实验室走向实际应用,具备目标驱动、自主规划等能力,正在重塑工作与生活方式,并指出其广阔市场前景与面临的成本、适配性和安全挑战,为企业和个人提供了数字化转型的新视角。
对于许多AI应用开发者而言,Coze(扣子)是一个绝佳的起点。它以“Bot”(机器人)为核心,将提示词、插件、知识库、工作流等能力高度整合,提供了一种“All-in-One”的直观体验。我们习惯于在一个界面中,通过不断“赋能”来让一个Bot变得更强大。
LangChain与LangGraph同时发布1.0正式版,标志着AI智能体开发从原型阶段迈向生产级落地的关键转折。LangChain作为高层抽象框架适合快速构建智能体原型,而LangGraph作为底层运行时引擎支持持久化、人工干预等生产级需求。1.0版本带来全新接口设计、中间件系统、统一输出格式等重大改进,已被多家企业采用,成为AI Agent领域的标准框架之一。
这两年,AI越来越火,在生活和工作里到处都能看到它的影子。AI 智能体就像一个个超级能干的数字小帮手,能自己 “看” 懂各种信息,快速做出判断,还能帮我们完成各种复杂任务。不管是处理数据、写文案,还是安排工作流程,它们都能轻松搞定,大大提高了工作效率。随着大家对 AI 智能体的需求越来越多,国内外出现了不少好用的开发框架和平台。这些工具就像搭建房子的积木和图纸,帮开发者们更快、更方便地做出各种智能
Qwen3是阿里巴巴Qwen团队最新发布的开源大语言模型,提供具有竞争力的性能,高度模块化和工具使用能力。在本指南中,我将向您展示如何通过Ollama在本地运行Qwen3,并启用MCP(模型上下文协议)工具功能,如代码解释器、网络获取和时间查询。到最后,您可以构建由Qwen3驱动的智能助手,完全在您的机器上运行——无需云API密钥

本文为Java开发者提供大模型技术应用指南,强调发挥Java工程化优势,通过Spring Boot等框架封装大模型API,构建企业级AI系统。建议采用Java生态工具链(Spring AI、LangChain4j)实现模型集成,从API调用逐步过渡到全栈开发。重点包括:多模型路由策略、性能优化方案(线程池调优、批量处理)、结果校验机制等实用技巧。同时给出金融、制造等领域的典型应用场景,推荐阿里云认

本文介绍了AI工作流框架的概念、类型及优势,重点讲解了字节跳动扣子(Coze)平台。该平台通过可视化节点式工作流,让用户无需编写代码即可快速构建大模型应用,提供丰富组件和插件生态。文章对比了Dify、N8n等同类产品,展望了AI工作流框架在提升研发效率、实现"工作流即服务"方面的潜力,为开发者提供了从创意到应用的全链路解决方案。
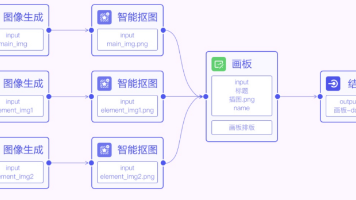
本文对比分析了四种主流AI开发工具的功能定位与适用场景:n8n(可视化自动化与Agent编排平台)、Dify(低代码LLM应用框架)、Coze(封闭式AI助手平台)和LangGraph(代码优先Agent框架)。n8n适合业务流程集成与API服务化,Dify擅长快速部署LLM应用,Coze侧重快速构建bot原型,LangGraph则适用于复杂可编程Agent系统。文章指出AI人才需求激增,建议开发

文章对比了Java后端与大模型应用开发两大技术方向。Java后端市场需求稳定但内卷严重,成长空间有限;大模型应用开发作为新兴技术,薪资高、需求大,是未来5-10年的技术热点。文章详细介绍了大模型学习路径,包括transformer架构、LangChain等技术栈,并指出当前是进入AI领域的好时机,掌握相关技能可获得更高薪资和更多职业可能性。
