- @Aifuyao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
该模型不仅延续了 YOLO 系列标志性的快速推理特性,更在 CPU 推理速度(提升 43%)、模型轻量化及边缘设备适配性上实现颠覆性突破,同时凭借统一架构设计大幅降低了技术门槛 —— 无论是物体检测与实时跟踪、精细实例分割,还是图像分类、姿态估计、旋转边界框检测等多样化计算机视觉任务,YOLO26 均能以极简的部署流程与稳定的输出效果高效应对,成为兼顾专业性能需求与边缘计算场景的优选方案,为智能交

目标检测开源数据集是计算机视觉领域的重要基石,支撑目标检测任务的算法研发、模型训练与性能评估,兼顾样本的丰富性、场景的覆盖性与应用的通用性。它包含海量标注精细的图像或视频样本,覆盖日常场景(如行人、车辆、家具)、自然场景(如动物、植物、地形)、工业场景(如机械零件、生产流水线)等数十类通用目标,也涵盖医疗场景(如血细胞、病灶区域)、遥感场景(如建筑、农田、舰船)、自动驾驶场景(如交通标志、障碍物)

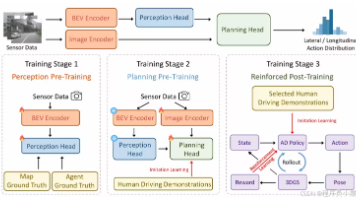
摘要:本文探讨强化学习与目标检测结合的创新研究路径,重点分析其在提升检测精度、降低计算开销方面的优势。介绍两个典型案例:1) 基于Qwen2.5-VL大模型的多图定位强化学习方案,通过思维链微调和GRPO强化学习提升跨图推理能力;2) 融合空间变换网络的小目标检测框架,采用RL驱动的粗到精检测策略。研究显示,这种组合能有效解决传统检测方法的泛化弱、小样本适应差等问题,在多个权威基准上取得突破性进展
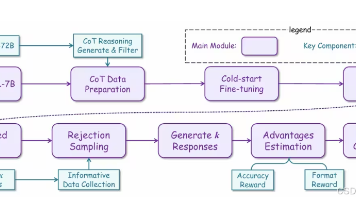
【CRL研究新机遇与自动驾驶强化学习进展】当前因果强化学习(CRL)成为AI研究蓝海,其中离线因果RL因工业需求旺盛备受关注。两篇最新论文展示了CRL的创新应用:1)NeurIPS论文RAD构建基于3D高斯溅射的自动驾驶仿真环境,结合因果RL与模仿学习,通过多维度奖励设计显著降低碰撞风险;2)Sci China Inf Sci提出因果动作赋能框架(CAE),利用因果推理优化强化学习的动作探索效率,
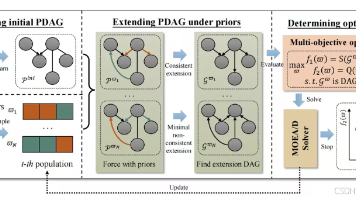
【因果推断与多目标优化交叉研究新方向】该领域通过融合因果结构解决传统多目标优化忽略变量因果关系的痛点,具有显著学术价值与工业应用潜力。核心优势: 突破性:IEEETKDE论文UpCM首次将因果结构学习转化为多目标优化问题,采用MOEA/D框架平衡数据与先验知识,提出PDAG最小非一致扩展策略处理先验冲突 创新应用:CAPO框架利用因果推断解耦预测不确定性,通过多目标优化实现扩散模型的自适应偏好对齐
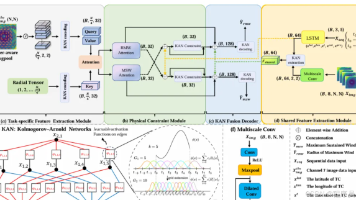
发现很多人在做KAN时,关注点都放在KAN本身的结构改进上,这个已经很难卷了,现在真正容易出成果的,反而是KAN与经典架构的结合。尤其是KAN+CNN这条路线,近两年相关工作越来越多。从图像分类、目标检测到医学影像、遥感分析,不少研究都在尝试利用CNN强大的局部特征提取能力,结合KAN的可解释性和非线性建模优势,在保证性能的同时提升模型表达能力。这块最大的难点一般不是搭模型,而是不知道别人已经做到
从工业生产线上的质量把控,到安防监控中的智能预警,再到自动驾驶汽车的核心技术,计算机视觉正重塑着众多行业的发展格局。以 RGB 颜色模型为例,可将其理解为有序排列的三个矩阵,也能用三维张量来表示,每个矩阵就是图像的一个通道,通过宽、高、深进行描述。在 AI 大模型蓬勃发展的当下,计算机视觉技术作为人工智能领域的关键分支,展现出了强大的生命力和广阔的应用前景。它取代了传统的人工设计特征提取算法,提升

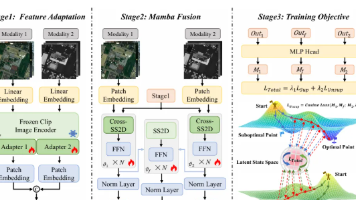
在人工智能与遥感技术深度融合的前沿领域,正成为极具开拓价值的研究方向。这一方向兼具技术创新性与应用落地潜力,目前竞争度较低,适合早期布局。Mamba 作为高效的状态空间模型(SSM),以线性复杂度实现长序列建模和全局依赖捕获,完美契合遥感数据处理中对时空分辨率、计算效率和多维度分析的核心需求,在城市动态监测、灾害应急响应、军事目标识别等实时性要求高的场景中展现出独特优势。
在人工智能飞速发展的当下,大模型开发平台层出不穷,Dify 凭借其独特优势脱颖而出。这是一个开源的大语言模型(LLM)应用开发平台,旨在大幅简化和加速生成式 AI 应用的创建与部署流程,为开发者提供了便捷且强大的工具与环境。

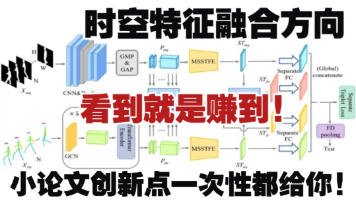
时空特征融合是当前人工智能与数据处理领域的热门研究方向,通过整合空间与时间维度的信息,显著提升模型预测精度、泛化能力和数据处理效率。该技术在遥感图像处理、智能交通、行为识别等场景中广泛应用。本文介绍了多个前沿研究思路,包括MFF-EINV2用于声音事件定位与检测、MSAFF用于多模态步态识别、STFEformer用于交通流量预测等,这些方法通过创新融合策略,实现了性能与效率的双重突破。相关论文和开