




- @m0_57081622
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
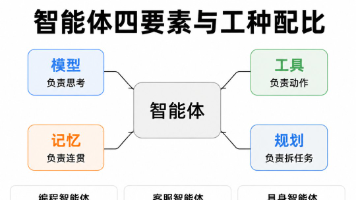
把这些Agent,放在同一张表里看。横向四列,工作环境、核心难点、商业化成熟度、代表产品。纵向十一行,从编程到具身。这张表的意义不是把每一类的细节再复述一遍,是让你一眼看出哪类 Agent 在哪个发展阶段、哪类的钱最好赚、哪类的天花板最高。看这张表的时候要带着问题看,自己的产品想做哪一类、自己的能力适合做哪一类、自己的资源能撑到哪一类的爆发点。带着这三个问题看完,你对自己接下来要怎么入局,会有一个
目标:虽然你已有前端基础,但需要将技能树向“服务逻辑”延伸,并理解AI交互的基本范式。学习重点:掌握Node.js/Deno后端基础,理解HTTP、WebSocket等通信协议。学习OpenAI API、LangChain.js、Vercel AI SDK等主流LLM调用库。理解Prompt Engineering的基本原理,学会编写有效的系统提示词和用户指令。实践简单的聊天机器人项目,完成从前端

前端开发者的 AI Agent 学习路径Day 1:LangChain.js 是什么、为什么前端开发者应该用、组件化思维迁移Day 2:页面交互 vs Agent 交互、Tool 定义、Chain vs Agent 选型Day 3:本地原型 → React 组件 → Vercel 部署,完整产品流程如果大家是前端开发者想做 AI Agent,不用学 Python,不用换语言,现有的 TypeScr
前端开发者的 AI Agent 学习路径Day 1:LangChain.js 是什么、为什么前端开发者应该用、组件化思维迁移Day 2:页面交互 vs Agent 交互、Tool 定义、Chain vs Agent 选型Day 3:本地原型 → React 组件 → Vercel 部署,完整产品流程如果大家是前端开发者想做 AI Agent,不用学 Python,不用换语言,现有的 TypeScr
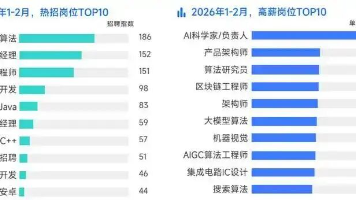
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
多智能体(Multi-Agent)是让多个能够接收信息、做出判断并执行动作的 AI 智能体,围绕一个共同目标进行任务分配、信息交换和协同工作的系统架构。简单说,它不是让一个人工智能独自完成所有工作,而是让一支 AI 小团队共同推进任务。每个智能体可以承担不同角色、使用不同工具、保存独立状态,最后再汇总或互相验证结果。多智能体系统通常包含三个核心特征:自主性:每个智能体都能感知信息、判断下一步并采取
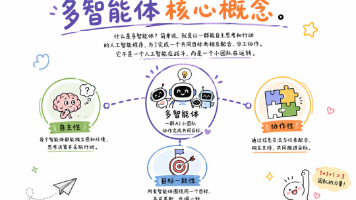
多智能体(Multi-Agent)是让多个能够接收信息、做出判断并执行动作的 AI 智能体,围绕一个共同目标进行任务分配、信息交换和协同工作的系统架构。简单说,它不是让一个人工智能独自完成所有工作,而是让一支 AI 小团队共同推进任务。每个智能体可以承担不同角色、使用不同工具、保存独立状态,最后再汇总或互相验证结果。多智能体系统通常包含三个核心特征:自主性:每个智能体都能感知信息、判断下一步并采取
多智能体(Multi-Agent)是让多个能够接收信息、做出判断并执行动作的 AI 智能体,围绕一个共同目标进行任务分配、信息交换和协同工作的系统架构。简单说,它不是让一个人工智能独自完成所有工作,而是让一支 AI 小团队共同推进任务。每个智能体可以承担不同角色、使用不同工具、保存独立状态,最后再汇总或互相验证结果。多智能体系统通常包含三个核心特征:自主性:每个智能体都能感知信息、判断下一步并采取
前端转大模型,不是跨行业颠覆式转型,而是技术能力的延伸与升级。不用和算法工程师比拼底层模型训练,只需依托自身交互、工程化、落地优势,聚焦大模型应用开发、RAG 知识库、AI Agent、工程化部署四大核心能力,3-6个月即可完成从传统前端到 AI 大模型开发的转型。相较于零基础转行者,前端开发者拥有天然的落地优势,只要坚持项目实战、精准对标岗位需求,就能快速实现薪资与技术层级的双重突破。如果说程序
