




- @xiaobing259
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
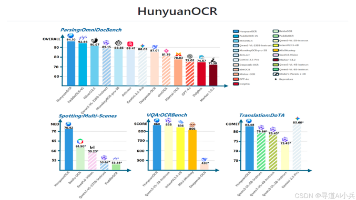
HunyuanOCR 是腾讯混元团队推出的一款开源端到端OCR视觉语言模型,专为高效处理复杂文档和多语言文本设计。它依托混元原生多模态架构,仅用1B参数量就实现了多项OCR任务的SOTA性能。HunyuanOCR 支持文本检测与识别、复杂文档解析、开放字段信息抽取、视频字幕抽取以及图像文本翻译等功能,覆盖了经典OCR任务的全场景应用。其轻量化设计和强大的多语言支持能力,使其在实际应用中表现出色,广
本文将带你从零开始,使用 LangChain4j 构建第一个 Java AI 应用。只需 25 行代码,就能让 Java 程序与大语言模型对话。我们将深入解析 ChatModel 的核心概念,并对比 Python LangChain,展示 Java 生态在 AI 应用开发中的独特优势。

大语言模型不仅能处理文本,还能"看懂"图片、"听懂"音频、"画出"图像。多模态能力让 AI 应用从单一的文本交互升级为全方位的感官体验。本文将带你掌握 LangChain4j 的多模态开发技术,包括 GPT-4V/GPT-5 的视觉理解、DALL·E 3 的图像生成、Whisper 的语音转文字。我们将通过真实代码示例,展示如何让 Java 应用识别图片内容、根据描述生成图像、转录音频文件,并分享

同步阻塞的 AI 调用让用户等待数秒甚至数十秒,体验极差;没有记忆的对话机器人每轮都是"初次见面",无法进行连贯交流。流式响应和对话记忆是构建优质 AI 应用的两大核心技术。本文将深入讲解 LangChain4j 的 StreamingChatModel 实现逐字实时输出,以及 ChatMemory 管理多轮对话上下文。你将掌握 TokenWindowChatMemory 的滑动窗口机制、Mess

本文深入讲解 Function Calling(函数调用)的核心原理,演示如何使用 @Tool 注解将 Java 方法暴露给 AI 模型,让大模型能够自主决定何时调用工具、传递什么参数。通过餐厅预订系统和动态代码执行两个实战案例,你将掌握工具注册、参数绑定、多步工具调用链等关键技术,并了解 ToolProvider 高级用法和安全沙箱机制,为构建企业级 AI 应用打下坚实基础

在前一篇文章中,我们学习了 Embedding 模型如何将文本转换为语义向量,并构建了基于内存的文本分类器。但当你需要将成千上万甚至上亿个向量持久化存储并实现毫秒级检索时,简单的内存存储就力不从心了。向量数据库(Vector Database)正是解决这一挑战的核心基础设施,它专门优化了高维向量的存储、索引和相似度搜索。

在前一篇文章中,我们深入对比了四大向量数据库的选型策略。但当你真正开始构建 RAG(检索增强生成)应用时,可能会发现:**配置向量数据库、设计文档分割策略、管理嵌入模型、编写检索逻辑……这些步骤太繁琐了!** 有没有一种方式,能够像"Hello World"一样简单,3 行代码就搞定 RAG?

在上一篇文章中,我们体验了 Easy RAG 的便捷——3 行代码就能构建一个完整的 RAG 系统。但你是否好奇:**这 3 行代码背后到底发生了什么?文档是如何被分割的?向量是如何计算的?检索是如何工作的?** 如果将 Easy RAG 比作"自动挡汽车",那么 **Naive RAG(朴素 RAG)** 就是"手动挡汽车"。它不会帮你隐藏任何细节,而是让你亲手操控离合器、油门、变速箱,真正理解

本文深入讲解三大高级 RAG 优化技术:查询压缩(Query Compression)、查询路由(Query Routing)和重排序(Re-Ranking)。通过约翰·多伊传记客服和多知识库问答两个实战案例,你将掌握如何解决多轮对话上下文丢失、多数据源检索效率低下、向量检索精度不足等核心痛点。同时我们还会分析每种技术的性能开销和适用场景,帮助你在实际项目中做出合理的技术选型。

本文深入讲解 Advanced RAG 的其他高级技术:元数据注入、元数据过滤、跳过检索、多检索器融合、网络搜索集成和返回来源引用。通过企业文档问答、多用户隔离、混合检索等实战案例,你将掌握如何提升 RAG 系统的可追溯性、精准度和灵活性。同时我们还会分析每种技术的适用场景和性能影响,帮助你在实际项目中做出合理的技术选型。
