- @Q2024107
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
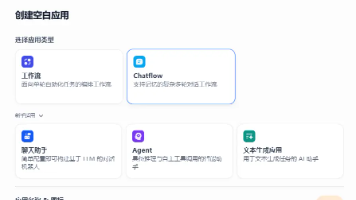
本文记录了一位开发者从Coze平台转向Dify时遭遇的认知转变过程。Dify采用"专业化应用模型"设计,与Coze的"全能机器人"理念不同,要求开发者根据需求选择聊天应用或智能助手类型。文章详细解析了如何通过Chatflow模式实现"文件上传+插件调用"的复杂需求,强调在Dify中LLM节点和Agent节点的职责区分,以及Function
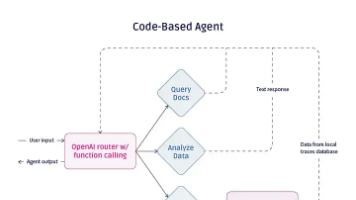
文章对比分析了三种智能体开发方案的优劣:纯代码方案简单直接但维护性差;LangGraph提供完整规范但调试困难;LlamaIndexWorkflows平衡灵活性与约束性。作者建议框架选择应考虑三个关键因素:项目已有框架集成情况、团队对架构的熟悉程度、以及可参考案例的可用性。通过实践对比发现,没有绝对最优方案,选择应基于具体需求。随着AI智能体技术的快速发展,开发者需要在框架选择、安全保障和模型监控
本文介绍了基于Dify和MCP开发AI理财助手的完整方案。文章从技术选型、环境部署入手,详细讲解了智能体架构设计、插件开发、金融数据抓取和微信公众号接入等关键环节。系统采用Dify作为LLMOps平台,结合MCP协议实现模块化工具调用,支持实时行情查询、资产组合分析和个性化投资建议等功能。开发部分包含Python代码示例,涵盖数据获取、MCP动作定义及微信公众号对接等核心模块。文章还探讨了运维安全
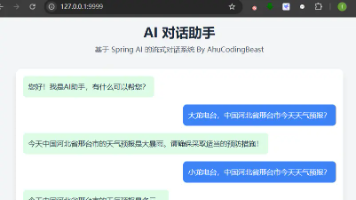
本文介绍了基于MCP协议的AI应用开发实践。MCP(ModelContextProtocol)是Anthropic推出的标准化协议,用于连接AI模型与外部数据源/工具,类似"AI的USB-C接口"。文中展示了使用Spring Boot 3.4.4和Spring AI 1.0.0-M6构建的MCP服务端和客户端实现,包括天气查询、书籍检索等功能。服务端通过@Tool注解暴露API
你是否在使用Maven构建项目时感到困惑?是否对那些复杂的命令行操作感到头疼?别担心,今天我将带你深入了解Maven核心插件——maven-clean-plugin的使用方法,让你的项目清洁如新!

你是否曾在SpringBoot的海洋中迷失方向?面对琳琅满目的starter模块,是否感到无从下手?别担心,今天我们就来一次深度探究,揭开spring-boot-starters的神秘面纱,让你的应用开发之路更加顺畅!

摘要:针对Dify和RagFlow在知识库入库方面的不足,作者开发了一款基于Dify平台的"知识库入库小助手"。该工具通过智能流程自动完成文档解析、规则匹配、智能切片和入库存储,解决了手动入库效率低、切片质量差、规则混乱等问题。系统支持多种文档格式,提供规则管理、智能提取、对话式流程等功能,效率提升10倍以上。演示显示,用户只需上传文件并确认,即可完成结构化入库,显著降低了知识
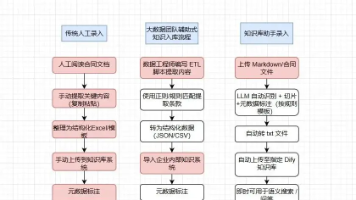
AI Agent工作流演进:从工具到协作生态 团队实践表明,AI工作流正经历三大趋势:从单Agent到多Agent协作(效率提升60%)、从被动响应到主动执行(如自动修复内存泄漏)、从工具调用到Agent Engineering(需专职工程师调优)。基于实战总结的IMPACT设计原则强调意图规范化、持久化记忆、动态规划等核心要素,并推荐三种平台选型方案(入门/专业/企业级)。关键挑战在于Agent
【摘要】扣子(Coze)是字节跳动推出的开源AIAgent开发平台,提供可视化一站式开发环境,支持无代码/低代码开发。平台集成最新大模型、工具和多种开发框架,内置上百个行业模板(如客服、营销等),支持快速构建智能体并一键发布至主流平台。开发者可通过拖拽式操作配置变量、数据库、记忆等功能,还能深度定制工作流和业务逻辑。开源版本采用Golang+React技术栈,提供模型服务、智能体构建、API集成等
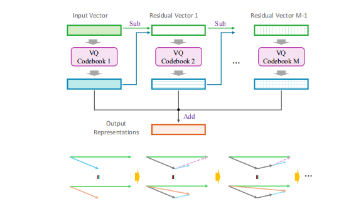
本文首次系统梳理了多模态LLMs的离散标记化技术:技术价值:通过VQ/RVQ/FSQ等8类方法,解决模态鸿沟与计算瓶颈。性能突破:LFQ、MAGVIT-v2等模型在图像/视频生成、语音合成等任务中达到SOTA。未来方向:动态量化、跨模态统一token空间、可解释码本设计。