- @2401_84494441
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在AI浪潮席卷全球的今天,越来越多的人开始意识到:AI产品经理,将是未来最具竞争力的岗位之一。尤其是随着大模型(LLM)技术的爆发,一场“技术+产品”的革命正在悄然上演。很多小伙伴私信我:零基础能不能转型做AI产品经理?要学什么?路线有没有?别慌,这篇文章给你梳理了一份【AI大模型产品经理学习全攻略】,内容非常详细、系统,收藏这一篇,未来少走两年弯路!
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这篇文章系统梳理了大模型的学习路径与实际应用要点。首先建议从BERT、GPT、T5、GLM四大基础模型入手,掌握其预训练目标和下游任务应用。当前开源生态以Llama家族为主导,学习重点应转向下游微调(SFT/PEFT)和数据工程,推荐优先掌握LoRA等高效微调技术。文章指出大模型学习已从理论研究转向工程实践,强调应用开发能力培养,并提供了包含学习路线、视频教程、技术文档等价值2万元的免费学习资源包

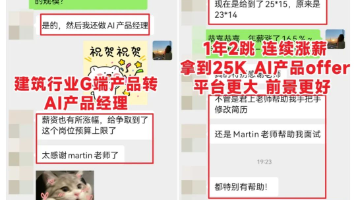
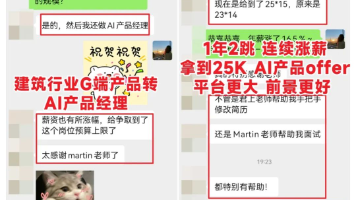
我是颖子,今天受邀分享一下我从寒冬建筑业转型热门AI行业做产品的心路历程:毕业2年,资历浅,边工作边学习边找出路。2个月准备,跳槽成功拿到涨薪20%的电商小厂AI产品offer!积累1年,再次跳槽到教育中厂继续做AI产品经理,拿到25K的offer!
本文探讨了上下文工程结合MCP协议生态能否替代AI智能体的问题。通过Google DeepResearch验证,结论是目前阶段无法完全替代,AI智能体在任务规划、记忆处理等方面仍有优势。作者通过新闻自动抓取场景测试(使用Trae+SequencialMCP工具),验证了结构化提示词+MCP+本地代码可替代部分智能体工作。核心观点:1)非精确处理场景适用大模型+MCP方案;2)精确处理场景应整合大模
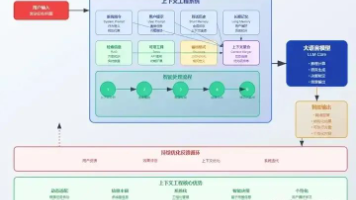
本文系统介绍了AI产品经理的学习路线,分为七个阶段:计算机科学基础、AI技术基础、产品管理、特定技能、实践案例、软技能提升和持续学习。重点包括编程、机器学习、商业分析等核心能力,强调技术产品化思维和数据驱动决策。同时提供大模型学习路径,涵盖系统设计到行业落地方案。建议学习者通过项目实践积累经验,保持持续学习以适应AI领域快速发展。文末附有104G大模型学习资源包获取方式。
各大AI模型平台近期动态:Trae国内版开放免费体验KimiK2和Qwen3-Coder模型;阿里通义灵码降价50%但价格仍偏高;腾讯CodeBuddy大规模发放邀请码;AWS Kiro限制登录需排队;Cursor验证无需Tun模式即可使用国外模型;AugmentCode将于7月28日发布新Agent产品。文章同时指出2025年大模型岗位缺口达47万,初级工程师平均薪资28K,并提供了完整的大模型
2025世界人工智能大会显示,AI正深度重塑医疗健康产业,在癌症早筛、药物研发、手术机器人等领域实现突破。当前"AI+医疗"呈现两大趋势:一是AI成为推动产业升级的核心引擎,拓展临床诊疗、药械研发等新应用;二是伦理监管和算法透明度等挑战日益突出。专家指出,AI正从辅助工具演变为医疗决策主体,需建立透明公平的制度保障。同时,"全民健康康养促进行动"在浙江试点,通过"健康驿站"推动慢病管理。随着AI医
文章探讨了在AI技术快速发展的时代中,产品经理如何保持竞争力。作者指出未来高薪产品经理岗位将集中在AI、数据、平台型等方向,并推荐了多本相关书籍,包括《AI3.0》《数据产品经理:实战进阶》等技术类读物。最后还分享了由专家团队整理的大模型学习资源包(104G),包含视频教程、学习路线和实战项目,适合毕业生、转行者和技术提升者免费领取。全文强调持续学习的重要性,帮助读者应对职场挑战。

摘要:本文介绍了一套高效自动化的评论分析方案,通过影刀RPA采集电商和内容平台评论,飞书多维表进行数据整理,扣子空间完成分析报告生成。该方案能自动抓取用户名、评论内容、点赞数等关键字段,支持情绪分析和关键词提取,大幅提升从数据采集到分析决策的效率。文章还分享了AI大模型学习资源包,包含视频教程、学习路线和技术文档,适合不同基础的学习者。