




- @m0_59614665
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
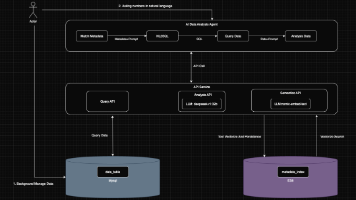
本文通过高考数据分析案例,详细介绍了AI Agent的开发实践流程。文章采用手写代码、LangChain框架和QwenAgent框架三种方式实现了一个智能助手,能够解析用户自然语言查询、生成SQL语句、查询数据并进行分析。实践涉及RAG检索增强、工具调用、ReAct等核心技术,展示了如何构建能够处理复杂数据查询的智能助手系统,适合初学者了解AI Agent开发全流程。
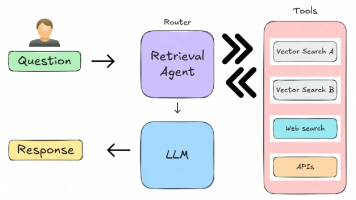
智能体式RAG是一种由AI智能体驱动的RAG方法。它通过利用智能体来管理任务、从多个来源获取信息并处理更复杂的工作流,从而增强了标准的RAG流程。
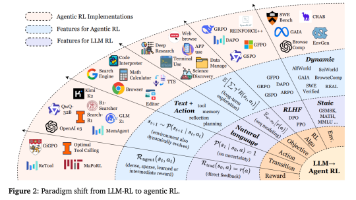
论文(The Landscape of Agentic Reinforcement Learning for LLMs: A Survey)绘制了大语言模型agent强化学习的全景图,展示了模型如何通过跨时间步骤的行动来学习。该综述涵盖了500多项工作,将其组织成一个包含能力和应用两部分的完整地图。问题背景:传统大语言模型训练存在根本缺陷:仅对单个回答进行一次奖励,然后停止学习。但现实任务需要:•
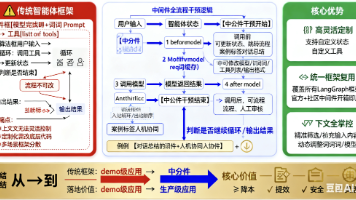
LangChain 1.0 的中间件,本质是给 AI 智能体装上了 “灵活的操作系统” – 过去是 “框架定死规则,开发者被动适应”,现在是 “开发者用中间件定规则,框架跟着需求走”。不管是控制上下文、保障安全,还是降本提效,中间件都能帮你用更低的成本实现,让 AI 智能体真正从 “demo” 走向 “生产”。
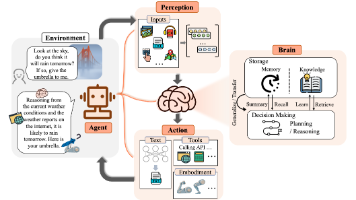
文章介绍了AI Agent概念的演变,从前大模型时代的定义(强调环境交互、智能、感知等特性)到大模型时代基于LLM的Agent三组件(规划、记忆、工具使用)。文章解析了Agent与大模型的关系(AI Agent = LLM + 角色定义 + 规划 + 工具使用 + 记忆),探讨了为什么需要Agent(解决环境隔离、执行能力、任务拆解和状态维持问题),并预告了后续将实现数据洞察Agent的实践内容。
本文基于 Spring AI 框架,完整实现了一套企业级 RAG 系统,从技术选型、依赖配置到核心服务代码,提供了可直接落地的解决方案。该系统通过 Spring AI 简化了大模型与向量存储的集成,通过 Apache Tika 与 LangChain4j 解决了多格式文档处理与分块优化问题,最终实现了 “文档入库 - 问题检索 - 增强生成” 的全流程自动化。基于私有知识库生成回答,避免幻觉支持动
当AI Agent能够使用外部工具,其功能会更加强大。然而,成功的关键在于选择正确的工具,而不是让Agent面临太多的选择。如果添加不必要的工具,则可能使代理感到困惑并降低效率,因此最佳的做法是只为特定代理配备有效完成所需的基本工具。更多工具≠更好的结果。
本文介绍LangChain Open Deep Research深度研究代理框架的三阶段流程(范围界定、深度研究、报告撰写)及其"主管-子代理"协同模型。通过任务分解和并行研究提高效率,同时解决多代理系统的协调成本、上下文隔离和Token膨胀问题。文章提供了完整部署指南、系统运行演示及AI幻觉问题的优化建议,是开发者构建高效AI研究代理的实用指南。在人工智能应用领域中,深度研究代理已成为最具价值和
文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如

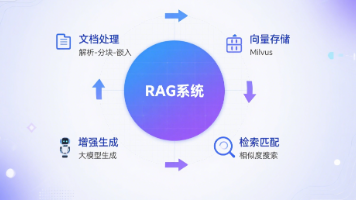
打造一个牛逼的 RAG 系统,不是用最新的 embedding 模型或最炫的 vector database,而是要懂你的用户、你的数据,选对每种场景的检索策略。从简单的 vector search 开始,衡量关键指标,逐步增加复杂度。最重要的是,永远用真实用户查询测试——别光用演示里完美的例子。
