- @javatiange
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
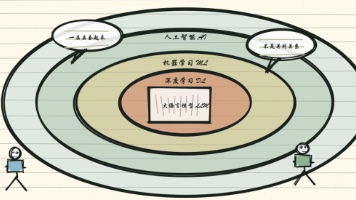
日常接触各类智能新产品时,可以顺着这套逻辑逐层拆解分析:第一,这套产品要解决哪一类需要智能处理的任务?这一步对应人工智能的范畴。第二,实现功能是靠人工一条条写死规则,还是依托数据自主学习?这一步对应机器学习的范畴。第三,核心技术是否采用多层神经网络搭建?这一步对应深度学习的范畴。第四,是否依托大规模训练搭建,专门用来处理、生成各类文字内容?这一步才贴合大语言模型的范畴。不用笼统发问“这个产品到底算
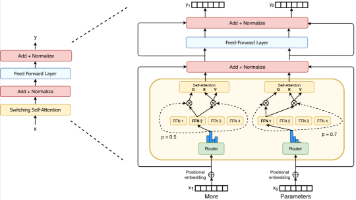
摘要: 大语言模型技术涵盖预训练、微调、提示学习等核心方法。预训练优化包括任务设计、热启动、分层训练、知识迁移和可预测扩展策略,显著提升效率(如CPM-2效率提升37.5%)。架构创新如RetNet和混合专家模型(Switch Transformers)解决了显存和计算效率问题。微调技术通过指令微调(如InstructGPT)和参数高效学习(如LoRA、Prefix-Tuning)实现任务适配,降
AI大模型推理框架选型指南(2025) 本文系统分析了2025年主流LLM推理框架的技术特性和应用场景。高性能方案以vLLM(PagedAttention架构)、LMDeploy(GPU极致优化)、SGLang(分布式部署)为代表;轻量化方案包括Ollama(本地部署)、Llama.cpp(CPU优化)等;灵活部署框架如XInference(多模兼容)、LiteLLM(API集成)满足多样化需求。
从GPT3演进到ChatGPT,从GPT4赋能GitHub Copilot的发展历程中,微调技术发挥了关键作用。本文将系统解析微调(fine-tuning)的核心概念、实际应用价值,以及LoRA(Low-Rank Adaptation)的创新原理。
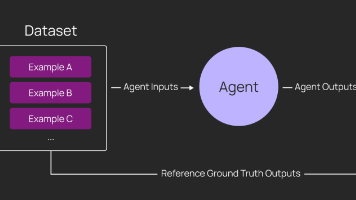
本文探讨了评估深度智能体(agent)的5种关键模式:1)每个测试用例需定制验证逻辑;2)单步运行验证决策点;3)完整轮次测试端到端执行;4)多轮对话模拟真实交互;5)环境配置需可复现。文章详细介绍了三种运行方式(单步/完整轮次/多轮)和三种测试内容(执行轨迹/最终响应/其他状态),并展示了如何在LangSmith中实现定制化测试,包括单步中断检查、完整流程验证等实用技巧。这些方法帮助开发者全面评
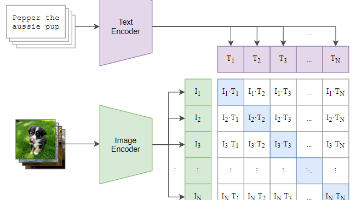
摘要: CLIP模型通过对比学习实现图文跨模态对齐,采用视觉编码器(ResNet/ViT)和文本编码器(Transformer),利用4亿组互联网图文对(WIT数据集)进行预训练。其核心创新在于零样本学习能力,通过提示词模板(如"A photo of a {对象}")直接泛化至下游任务,但细粒度分类表现仍弱于微调模型。研究突破了传统依赖标注数据的局限,为多模态理解提供了新范式。
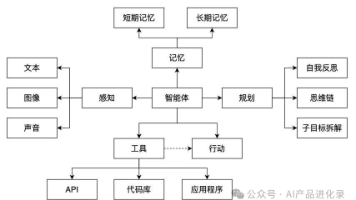
AI Agent的核心运作机制解析:从用户指令到任务完成的五层架构 本文深入剖析了真正智能AI Agent的内部工作原理,将其分解为五大协同模块:Prompt提示词处理、LLM大模型决策、Memory知识库支持、Planning任务规划和Action执行层。通过"找火锅店"的实例,展示了各模块如何配合完成复杂任务,包括意图理解、信息提取、工具选择、步骤拆解和最终执行。文章强调A
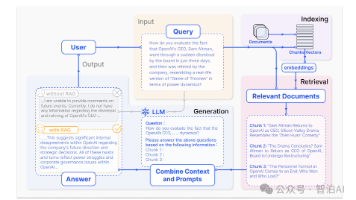
大语言模型(LLM)在理解和生成连贯对话方面取得了显著成就。但是,它们存在一个内在的“记忆缺陷”,即它们拥有的上下文窗口是有限的,这严重限制了它们在多轮次、多会话的长期交互中维持一致性的能力。当对话内容超出了上下文长度时,LLM 可能会像一个“健忘”的伙伴一样,忘记用户的喜好、重复提问,甚至与之前确认的事实相冲突。

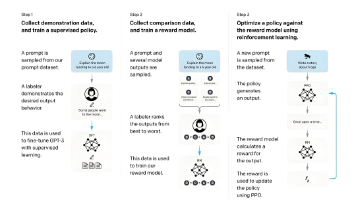
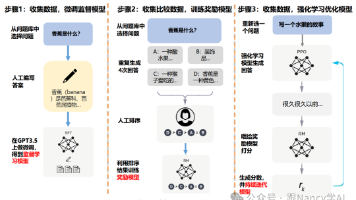
大语言模型(LLM)训练分为三个阶段:预训练(Pretrain)、监督微调(SFT)和基于反馈的强化学习(RLHF)。预训练阶段通过海量文本数据让模型学习语言规律和基础知识;SFT阶段使用高质量问答数据教会模型遵循指令;RLHF阶段通过人类反馈优化模型输出,使其更符合人类价值观。整个过程从知识积累到行为规范,最终形成符合3H原则(Helpful、Honest、Harmless)的智能助手。随着AI
【摘要】AI应用开发岗成为就业新风口,求职者转岗后反馈岗位需求旺盛、薪资优厚。数据显示,AI开发实习薪资(200-300元/天)高于传统Java岗位(150-200元/天),双非学历也有机会。2025年AI领域预计人才缺口达1000万,算法和工程类人才尤为紧缺。主流开发语言包括Python(深度学习框架)、Java(企业级应用)和C++(高性能计算),其中Python因丰富的AI库成为首选。招聘网