登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了大模型开发与应用的核心技术及工具链:1. Ollama作为大模型管理工具,支持快速搭建聊天机器人(ChatBot),包括安装使用、结合ChatBox/Streamlit等工具实现交互;2. LangChain开发框架需配合Qwen模型及阿里云百炼平台(需API密钥)进行环境配置;3. RAG技术为核心,涵盖智慧问答、物流咨询等实战项目;4. 详解ReAct和AgenticRAG技术,并涉
你的 AI 应用还在原型阶段止步不前?本文将带你跨越从 Notebook 到生产环境的工程鸿沟。通过解析工作流编排的核心价值,你将掌握状态管理、异步控制等关键技能,构建出高可用、易扩展的企业级 Agent 与 RAG 系统 🚀。
用ChatGPT大半年了,我以为自己挺懂AI的。直到有一天朋友问我:「ChatGPT和Midjourney背后的技术是一样的吗?机器学习和大模型到底啥关系?我张了张嘴,发现自己根本说不清楚。于是花了点时间,把整个AI技术路线从头捋了一遍。从一头雾水到理清脉络,这个过程我觉得挺值的,分享给你。—— ◆ ——
最近 AI 编程工具(如 Codex、Claude Code)在团队协作中逐渐普及,很多团队发现,虽然单兵作战效率提升了,但一旦涉及多角色协作和复杂业务逻辑,Bug 反而多了。这种现象在大模型应用层尤为明显。我们之前用 LangChain 做简单问答时,RAG 方案往往能跑通 Demo,但一进入生产环境,面对企业级知识库的复杂关联关系时,传统的向量检索就开始“迷路”。这就是我今天要复盘的主题:Gr
最近 AI 编程工具(如 Claude Code, Codex)在团队协作里的渗透率越来越高,大家发现 Demo 写得再漂亮,一到生产环境就崩盘。原因往往不是模型不行,而是权限、日志和依赖关系没理清楚。这让我想起之前做企业知识库时的一个教训:很多团队一上来就想着搞“全知全能”的 GraphRAG,把整个文档库塞进 Neo4j,结果推理延迟高得吓人,维护成本更是指数级上升。GraphRAG 的核心价
还在为 AI 应用“Demo 很美,上线崩溃”而头疼?本文揭秘 Airi 项目,教你如何利用其模块化架构与 RAG 管道,快速构建 100+ 个可落地的 AI Agent 应用。从多智能体协作到模型无缝切换,助你轻松跨越从代码到生产的鸿沟 🚀。
我们知道,大模型只会对话,聊天,所谓的工具调用也只不过是特化的聊天功能而已。但是各种天花乱坠的 skills,是如何在底层的 HTTP 中,与大模型——这个只会嘴遁的工具交互的呢?
词嵌入负责理解语义、向量化;向量数据库负责快速找相似内容;最后把找到资料喂给大模型,让 AI 借助私有外部知识作答,弥补大模型知识截止、无法使用本地数据的缺陷。
最近团队里开始大规模引入 Claude Code 和 Cursor 这样的 AI 编程助手。表面上看,代码生成速度上去了,但奇怪的是,Bug 并没有减少,甚至因为 AI 生成的逻辑太“自信”,导致排查难度指数级上升。在复盘一次因 AI 幻觉引发的严重线上事故时,我意识到一个被很多人忽略的真相:当 AI 的“创造力”溢出时,传统的 RAG(检索增强生成)已经不够用了,而 GraphRAG(图检索增强
健康咨询,简单说就是帮助人们获取健康相关信息和建议的过程。传统模式下,这个角色由医生、药师、健康顾问等人承担——你挂号排队、面对面交流、获取专业意见。但现实是医疗资源永远不够用:中国每千人执业医师数约 3.0,远低于发达国家的 4-5。这意味着大量轻量级咨询需求(“这个药能不能和那个药一起吃?”“孩子发烧 38.5 度要不要去医院?”)其实并不需要占用宝贵的医生时间。健康咨询机器人的定位就在这里—
最近 Codex 和 Claude Code 这类 AI 编程工具在公司里跑得很欢,从个人试用迅速蔓延到团队协作。大家欢呼声很高,觉得“自动写代码”、“自动修 Bug”指日可待。但作为负责基建的人,我看到的是另一番景象:Demo 跑得分毫不差,一上生产环境就炸锅。原因从来不是模型智商不够,而是两个老生常谈却总被忽视的工程问题——权限控制和全链路日志。GraphRAG(知识图谱检索增强生成)作为 R
具身智能学习路径深度强化学习学习路径,是嵌入 / 对接各类信息系统(ERP、OA、MES、数据库、业务平台、管理信息系统 MIS 等)、以大模型为核心,具备能力的软件智能实体。通俗理解:它是现有信息系统的;不再只是被动查询数据,能够理解自然语言业务目标,自动跨多系统完成一整套信息获取、计算、流程操作、报表输出。
市面上的 Agent 框架太多了:LangChain、LangGraph、CrewAI、AutoGen、Semantic Kernel、Dify……面对这么多选择,很多团队光是选框架就能纠结好几周。
本文基于我在多个项目中的实战经历,结合最新的技术趋势,拆解一条从概念到生产级的完整落地路径。
RAG 创新性地将信息检索与文本生成相结合,致力于解决 AI 生成内容准确性和可靠性的问题。它通过引入知识库检索机制,有效减少生成内容中常见的 “幻觉” 现象,从而创造出更准确、信息更充分的回应。在人工智能技术飞速发展的当下,MCP(模型上下文协议)、RAG(检索增强生成)、Agent(智能体)这三大概念热度持续飙升,成为 AI 领域备受瞩目的焦点。为了帮助大家深入理解这些概念及其内在联系,本文将
最近团队在引入 AI 编程工具(如 Codex、Claude Code)进行协作时,我发现了一个有趣的现象:单人跑通 Demo 的项目,一旦接入团队协作,往往会在权限隔离和日志追踪上崩盘。这和大模型应用开发的困境如出一辙——大家太迷恋“检索增强生成”(RAG)带来的幻觉消除能力,却忽略了“增强”的质量本身就是一个系统工程。很多开发者拿到 GraphRAG 这个概念,第一反应是:“我要把 Neo4j
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。最近身边几个做 SaaS 的小团队都在折腾 AI 编程工具落地。有人兴冲冲引入了 Claude Code 或 Codex,结果还没等代码生成跑顺,内部协作先乱套了:权限怎么隔离?日志谁来看?Agent 产生的副作用怎么回滚?我也忍不住插了一嘴:别急着上复杂的 Agent 框架,先看看你们的工程底座能不能兜住。这也是我
大模型可以写文案、做总结、回答问题,AI Agent则把这些能力带入具体任务。随着技术进入客服、销售、内容运营和内部管理,AI数字员工也成为企业正在评估的应用方向。
你问自己:如果下半年公司也要招"会用大模型的人",现在的我,算不算那个人。
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。最近 Codex 和 Claude Code 在开发者圈子里火得一塌糊涂,很多团队开始尝试让 AI 编程工具从个人试用走向团队协作。表面上看,这似乎是生产力的飞跃,但我在几个项目的联调复盘中发现了一个尴尬的现实:代码生成得再快,一旦涉及企业关键知识库的复杂查询,系统就崩了。以前做 RAG(检索增强生成),我们头疼的是
只会LangChain、简单微调、Prompt工程的初级大模型/Agent工程师,2025–2026出现大量简历 内卷,薪资相比2023高点没有上涨,部分岗位薪资下行10%–20%。强调复杂任务闭环、自主纠错、企业级智能体规模化部署;重心转向微调、推理优化、MLOps、行业落地;岗位大量与Agent、多模态、具身交叉;任务规划、记忆机制、FunctionCalling、多Agent协同、Agent
摘要: 2026年AI行业进入"重应用"阶段,企业依托成熟大模型(如GPT-5.4、DeepSeek-R1)构建AI智能体,推动推理算力需求激增。AI从"理解文字"升级为"理解世界"的世界模型,实现具身智能,赋能工业、医疗等领域。政策与市场双轮驱动下,企业通过五步法搭建AI Agent:需求诊断、技术选型、知识构建、部署集成和优化评估,显著降低成本并提升效率。技术架构以Agentic RAG为核心
文章摘要: Agent的记忆管理是企业工单处理中的核心挑战,需区分三层机制: 工作记忆存储当前决策所需的结构化事实(如订单状态、风险标记),确保动作精准性; 短期记忆维护工单线程的连续性(如会话摘要、待办事项),需动态更新并区分稳定与易变事实; 长期记忆包含政策、用户历史等跨任务知识,需结合向量库、关系数据库等存储,并保障权限与时效性。 关键原则是分层管理信息生命周期,避免混淆导致噪声干扰或状态失
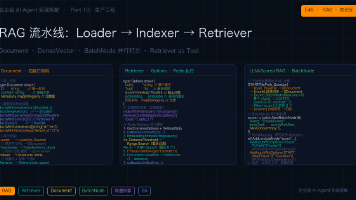
本文深入解析了企业级 AI Agent 中 RAG(检索增强生成)的核心组件设计与实现。文章将 RAG 流程拆分为构建期(Loader→Transformer→Indexer)和查询期(Retriever)两个阶段,详细介绍了四个核心接口的设计: Document 作为数据载体,包含内容、元数据和向量信息,提供类型安全的元数据操作方法 Loader 负责从各种来源加载原始文档 Transforme
先把这篇文章的目标说清楚:看完之后,你应该能判断这件事值不值得做,以及从哪里动手。上个月,我和几个正在找工作的学弟聊起天来。大家手里都有几个看起来很漂亮的 GitHub 项目:有的基于 LangChain 搭建了一个能读 PDF 的问答机器人,有的用 GraphRAG 做了一个企业知识库。面试时,他们能滔滔不绝地讲 Prompt engineering 的技巧,讲如何调整 embedding 模型
今天这篇,我用最直白的方式,把这四个核心技术讲清楚。读完你会发现:它们不是四个孤立的概念,而是 AI Agent 从"能聊天"到"能干活"的四层能力阶梯。
究竟什么是 Agent?主流的 Agent 架构又是如何设计的?本文将基于技术演进逻辑,为您一次性理清 Agent 的本质与四大核心架构。
本期为大家介绍如何通过Ollama部署本地大模型,Dify如何接入Ollama部署的本地大模型,以及脱离Dify如何方便使用大模型。
模型上下文协议MCP与Ollama的整合实现指南在过去一两个个月里,模型上下文协议(Model Context Protocol,MCP)频繁出现在各种技术微信交流群中。我们已经看到了许多很酷的集成案例,大家似乎相信这个标准会长期存在,因为它为大模型与工具或软件的集成设立了规范。前面一篇文章给大家分享了MCP一些基础概念,但是读完之后还是模棱两可,所以决定尝试将Ollama中的小型语言模型与MCP
LlamaIndex提供了三种提示词模板:RichPromptTemplate(最推荐,2025年最新推出)、ChatPromptTemplate和PromptTemplate。RichPromptTemplate基于Jinja2语法,支持条件判断和循环等高级功能,能动态生成复杂提示词。ChatPromptTemplate专为聊天场景设计,支持多角色结构化对话。PromptTemplate是基础模
本文将详细介绍Ollama项目的背景、技术细节以及如何实现在本地运行这些大型语言模型。
这样我们就实现了数据库+大模型相结合的一个AI智能询报价客服助手。可以帮助采购可销售解决大量的客户的询报价需求,提高企业工作效率!
然而,当设置为False时,这些节点在查询时不会被使用,因为它们将从索引的index_struct中删除,index_struct跟踪哪些节点可以用于查询。文档管理是LlamaIndex中非常重要的功能,它允许你对索引中的文档进行动态管理,包括插入、删除、更新和刷新操作。插入的底层机制取决于索引结构。如果一个文档已经存在于索引中,你可以使用相同的doc id更新文档(例如,如果文档中的信息发生了变
业务架构图了算是它的它有一个云服务吧可以生成API的key但其实我后来放弃了,没用它这个模式我一开始误以为它不支持windows,所以花了一点时间切换到wsl2下面去安装uv和建立环境官方默认的一个依赖库是有问题的所以只好稍微绕一下安装它的最新版本的,1.0.0rc0上面那个有问题的库,其实就是用来画图的这块,略微有点影响体验,减分了,官方维护的不太好看来安装sqlite3安装向量库和openai
RAG
——RAG
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵

 智能体开发者社区
智能体开发者社区


 AtomGit AI 社区
AtomGit AI 社区

 AI编程社区
AI编程社区
 2048 AI社区
2048 AI社区











 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区