后检索优化终极方案:CRAG技术实现与实战代码全解析,让AI回答质量提升80%!
本文详细介绍了RAG系统中的后检索优化技术——校正(Correction)及其实现方案CRAG。CRAG通过轻量级检索评估器评估文档相关性,根据置信度触发不同检索动作,实现智能质量评估和自适应检索策略。文章展示了使用LangGraph实现CRAG的完整流程,包括文档检索、评分、查询重写、网络搜索和答案生成。该技术能有效提升RAG系统在检索出错场景下的鲁棒性,让AI回答更加精准可靠,但同时也增加了系
本文详细介绍了RAG系统中的后检索优化技术——校正(Correction)及其实现方案CRAG。CRAG通过轻量级检索评估器评估文档相关性,根据置信度触发不同检索动作,实现智能质量评估和自适应检索策略。文章展示了使用LangGraph实现CRAG的完整流程,包括文档检索、评分、查询重写、网络搜索和答案生成。该技术能有效提升RAG系统在检索出错场景下的鲁棒性,让AI回答更加精准可靠,但同时也增加了系统复杂性,需权衡质量与效率。
继前面聊到的重排、压缩后检索优化技术后,今天我们聊一聊最后一个后检索优化策略——校正(Correction)。
和前面的技术不同,校正技术更注重系统的"自我完善"能力,通过自我的反思和评分机制,让RAG系统能够主动识别问题、评估质量并进行相应调整,使得在检索后处理和生成过程中实现更精准的优化。
这个技术有一个实现方案是 Corrective Retrieval Augmented Generation(CRAG)。CRAG的思想来自一篇论文,里面介绍了如何通过引入一个轻量级的检索评估器,并根据评估结果触发三种知识检索动作(正确、不正确、模糊),结合一些优化策略和网络搜索能力,显著提高了在检索出错场景下的生成鲁棒性。
论文原文链接:https://arxiv.org/pdf/2401.15884.pdf
CRAG概述
CRAG系统核心思想在于通过反复评估和重新检索,确保生成的回答所依据的信息源具有很高的相关性。
CRAG通过设计一种轻量级的检索评估器,用于评估检索文档的整体质量,并根据置信度触发不同的知识检索操作。如果置信度高于设定的阀值,系统将会进行生成操作。生成之前,会对检索到的文档进行分解、过滤和重组,以提取关键信息并去除不相关内容。如果所有文档置信度都低于设定阀值,或者评估器不确定相关性,系统则会扩展到通过网络搜索以获取和补充相关知识。
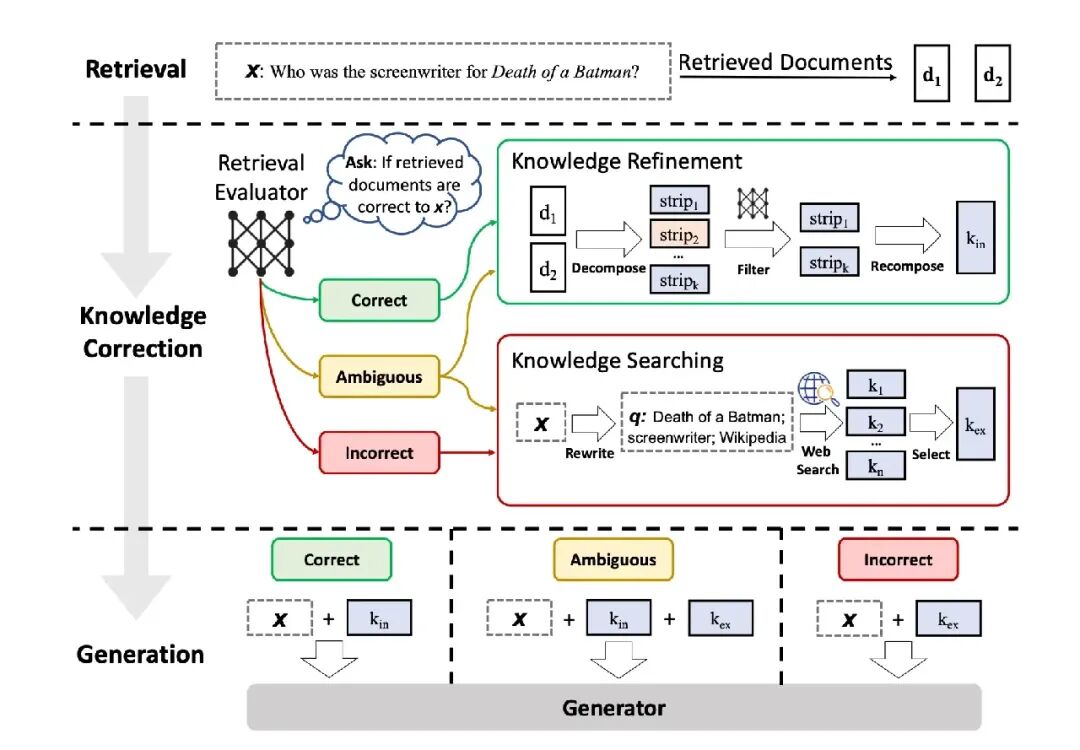
CRAG 实现案例
接下来我将使用LangGraph实现CRAG的基本流程。
-
- 创建示例博客文章索引,并将这些文档片段存储在Chroma向量数据库中。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.schema import Document
print("🔧 正在构建向量数据库...")
# 定义要索引的博客文章URL
# 这些是关于AI智能体、提示工程和对抗攻击的技术博客
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/", # AI智能体相关
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/", # 提示工程
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/", # LLM对抗攻击
]
# 使用WebBaseLoader加载每个URL的内容
try:
docs = [WebBaseLoader(url).load() for url in urls]
# 将嵌套列表展平为单一文档列表
docs_list = [item for sublist in docs for item in sublist]
print(f"✅ 成功加载 {len(docs_list)} 个文档")
except Exception as e:
print(f"⚠️ 文档加载失败,使用本地示例文档: {e}")
# 创建示例文档
docs_list = [
Document(page_content="智能体记忆系统包括短期记忆、长期记忆和工作记忆。短期记忆用于临时存储当前上下文信息,长期记忆用于存储历史经验和知识,工作记忆用于当前任务的处理。"),
Document(page_content="提示工程是指设计和优化输入提示词以获得更好的语言模型输出效果的技术。包括零样本提示、少样本提示、思维链提示等多种技术。"),
Document(page_content="对抗攻击是指通过构造特殊输入来欺骗或误导AI模型的技术。在大语言模型中,常见的攻击方式包括提示注入、越狱攻击等。"),
Document(page_content="RAG(检索增强生成)是一种结合外部知识检索和文本生成的技术,能够提供更准确和时效性更强的回答。"),
Document(page_content="向量数据库是存储和检索高维向量数据的专用数据库,常用于相似性搜索和推荐系统。")
]
# 创建文本分割器,使用tiktoken编码器来准确计算token数量
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
# 将文档分割成小块,便于检索和处理
doc_splits = text_splitter.split_documents(docs_list)
# 创建中文嵌入模型
print("🔤 正在初始化嵌入模型...")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh", # 使用BGE中文嵌入模型
model_kwargs={"device": "cpu"}, # 使用CPU设备
encode_kwargs={"normalize_embeddings": True}, # 启用向量归一化
)
# 创建向量数据库
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma-deepseek", # 集合名称
embedding=embeddings,
)
# 将向量存储转换为检索器,用于后续的相似性搜索
retriever = vectorstore.as_retriever()
print("✅ 向量数据库构建完成")
-
- 定义检索评估器,用于评估检索文档与查询问题的相关性。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_deepseek import ChatDeepSeek
# 定义评分结果的数据模型
class GradeDocuments(BaseModel):
"""对检索文档相关性的二元评分。
这个类定义了文档相关性评分的输出格式,
确保模型只返回'yes'或'no'的明确判断。
"""
binary_score: str = Field(
description="文档与问题相关为'yes',不相关为'no'"
)
# 创建具有结构化输出的DeepSeek语言模型
llm = ChatDeepSeek(
model="deepseek-chat",
api_key=deepseek_api_key,
temperature=0.5
)
# 将模型输出限制为GradeDocuments格式
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# 构建评分提示模板
system = """你是一个评估检索文档与用户问题相关性的评分员。 \n
如果文档包含与问题相关的关键词或语义含义,则将其评为相关。 \n
给出一个二元评分'yes'或'no'来表示文档是否与问题相关。"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "检索到的文档: \n\n {document} \n\n 用户问题: {question}"),
]
)
# 创建检索评分链:提示模板 + 结构化语言模型
retrieval_grader = grade_prompt | structured_llm_grader
print("✅ 文档评分器初始化完成")
-
- 创建RAG生成链,利用大语言模型生成答案。
from langchain_core.output_parsers import StrOutputParser
from langchain import hub
# 从LangChain Hub获取预构建的RAG提示模板
try:
prompt = hub.pull("rlm/rag-prompt")
print("✅ 成功获取RAG提示模板")
except Exception as e:
print(f"⚠️ 获取Hub提示模板失败,使用默认模板: {e}")
# 使用默认的RAG提示模板
template = """基于以下上下文信息回答问题。如果上下文中没有相关信息,请说明无法从提供的信息中找到答案。
上下文信息:
{context}
问题: {question}
回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 创建用于生成答案的DeepSeek语言模型
generation_llm = ChatDeepSeek(
model="deepseek-chat",
api_key=deepseek_api_key,
temperature=0
)
# 文档格式化函数
def format_docs(docs):
"""将文档列表格式化为单一字符串。
Args:
docs: 文档对象列表
Returns:
str: 用双换行符连接的文档内容字符串
"""
return "\n\n".join(doc.page_content for doc in docs)
# 构建RAG生成链:提示模板 + 语言模型 + 字符串解析器
rag_chain = prompt | generation_llm | StrOutputParser()
print("✅ RAG生成链初始化完成")
-
- 创建查询重写器,将输入的问题转换为更适合网络搜索的版本。
# 创建用于查询重写的DeepSeek语言模型
rewrite_llm = ChatDeepSeek(
model="deepseek-chat",
api_key=deepseek_api_key,
temperature=0.5
)
# 查询重写的系统提示
system = """你是一个问题重写者,将输入的问题转换为更适合网络搜索的版本。 \n
分析输入并尝试推理出潜在的语义意图/含义。"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"这是初始问题: \n\n {question} \n 请重新表述为一个改进的问题。",
),
]
)
# 创建查询重写链
question_rewriter = re_write_prompt | rewrite_llm | StrOutputParser()
print("✅ 查询重写器初始化完成")
-
- 构建基于
CRAG工作流的图状态。这个状态在整个CRAG流程中传递,包含了处理过程中的所有关键信息。每个节点就是一个操作动作,边表示操作之间的转换。
接着定义图的状态和各个节点的功能。每个函数代表图中的一个节点,负责执行特定任务,如检索文档、文档评分、生成答案等。
- 构建基于
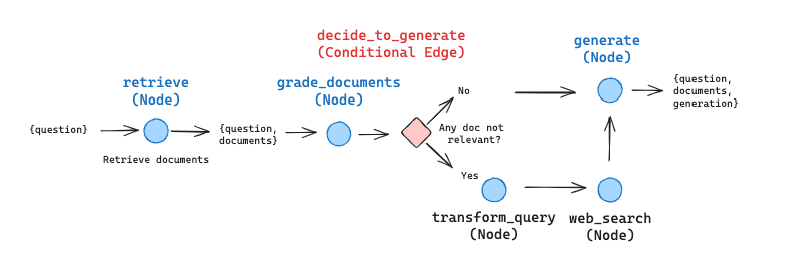
from langgraph.graph import END, StateGraph, START
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
表示CRAG工作流图的状态。
属性:
question: 用户的原始问题或重写后的问题
generation: 语言模型生成的最终答案
web_search: 标记是否需要进行网络搜索("Yes"/"No")
documents: 检索到的文档列表(原始检索结果或网络搜索结果)
"""
question: str # 当前处理的问题
generation: str # 生成的答案
web_search: str # 是否需要网络搜索的标志
documents: List[str] # 文档列表
# CRAG工作流节点函数
def retrieve(state):
"""
检索节点:从向量数据库检索相关文档
这是CRAG流程的第一步,基于用户问题检索潜在相关的文档。
参数:
state (dict): 当前图状态,必须包含'question'键
返回:
state (dict): 更新后的状态,添加了'documents'键
"""
print("---🔍 执行文档检索---")
question = state["question"]
# 使用向量检索器获取相关文档
documents = retriever.get_relevant_documents(question)
print(f"检索到 {len(documents)} 个候选文档")
return {"documents": documents, "question": question}
def generate(state):
"""
生成节点:基于检索到的文档生成答案
这是CRAG流程的最后一步,使用过滤后的相关文档生成最终答案。
参数:
state (dict): 当前图状态,包含question和documents
返回:
state (dict): 添加generation键的更新状态
"""
print("---✨ 生成最终答案---")
question = state["question"]
documents = state["documents"]
# 使用RAG链生成答案
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
文档评分节点:评估检索文档的相关性
这是CRAG的核心创新,通过LLM评估每个检索文档是否真正相关。
只保留相关文档,如果没有相关文档则标记需要网络搜索。
参数:
state (dict): 当前图状态
返回:
state (dict): 更新documents为过滤后的相关文档,设置web_search标志
"""
print("---📊 评估文档相关性---")
question = state["question"]
documents = state["documents"]
# 初始化过滤结果
filtered_docs = [] # 存储相关文档
web_search = "No" # 默认不需要网络搜索
has_relevant_docs = False # 是否有相关文档的标志
# 对每个检索到的文档进行相关性评分
for i, d in enumerate(documents):
print(f"正在评估文档 {i+1}/{len(documents)}")
try:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade.lower() == "yes":
print(" ✅ 文档相关")
filtered_docs.append(d)
has_relevant_docs = True
else:
print(" ❌ 文档不相关")
continue
except Exception as e:
print(f" ⚠️ 评分失败: {e}")
# 评分失败时保守处理,保留文档
filtered_docs.append(d)
has_relevant_docs = True
# CRAG的关键逻辑:只有在没有任何相关文档时才进行网络搜索
if not has_relevant_docs:
web_search = "Yes"
print("🔍 未找到相关文档,将进行网络搜索")
else:
print(f"📚 找到 {len(filtered_docs)} 个相关文档")
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state):
"""
查询转换节点:重写查询以提高搜索质量
当检索到的文档都不相关时,重写原始查询以获得更好的搜索结果。
参数:
state (dict): 当前图状态
返回:
state (dict): 用重写后的问题更新question键
"""
print("---🔄 重写搜索查询---")
question = state["question"]
documents = state["documents"]
try:
# 使用查询重写器生成改进的问题
better_question = question_rewriter.invoke({"question": question})
print(f"原始问题: {question}")
print(f"重写问题: {better_question}")
return {"documents": documents, "question": better_question}
except Exception as e:
print(f"⚠️ 查询重写失败,使用原问题: {e}")
return {"documents": documents, "question": question}
def web_search(state):
"""
网络搜索节点:获取外部信息补充
当本地文档库无法提供相关信息时,通过网络搜索获取额外信息。
参数:
state (dict): 包含当前状态
- question: 问题(可能是重写后的)
- documents: 文档列表
返回:
state (dict): 在documents中追加网络搜索结果
"""
print("---🌐 执行网络搜索---")
question = state["question"]
documents = state["documents"]
try:
# 使用免费搜索工具进行网络搜索
search_results = web_search_tool.search(question)
# 将搜索结果格式化为文档对象
search_content = []
for result in search_results:
content = f"标题: {result['title']}\n内容: {result['snippet']}"
search_content.append(content)
# 合并所有搜索结果
search_results_str = "\n\n".join(search_content)
web_results = Document(page_content=search_results_str)
documents.append(web_results)
print(f"✅ 网络搜索完成,获得 {len(search_results)} 个结果")
except Exception as e:
print(f"⚠️ 网络搜索失败: {e}")
# 搜索失败时添加一个提示文档
fallback_doc = Document(
page_content=f"关于'{question}'的搜索暂时无法获取外部信息,请基于现有知识回答。"
)
documents.append(fallback_doc)
return {"documents": documents, "question": question}
# 条件边缘逻辑
def decide_to_generate(state):
"""
决策节点:确定下一步行动
这是CRAG工作流的关键决策点:
- 如果有相关文档:直接生成答案
- 如果没有相关文档:转换查询并进行网络搜索
参数:
state (dict): 当前图状态
返回:
str: 下一个要执行的节点名称
"""
print("---🤔 决策下一步操作---")
web_search = state["web_search"]
if web_search == "Yes":
print("📋 决策: 重写查询并搜索")
return "transform_query"
else:
print("📋 决策: 直接生成答案")
return "generate"
# ================================
# 构建和编译CRAG工作流图
# ================================
print("🔧 正在构建CRAG工作流图...")
# 创建状态图工作流
workflow = StateGraph(GraphState)
# 添加所有节点到工作流图
workflow.add_node("retrieve", retrieve) # 检索节点
workflow.add_node("grade_documents", grade_documents) # 文档评分节点
workflow.add_node("generate", generate) # 答案生成节点
workflow.add_node("transform_query", transform_query) # 查询转换节点
workflow.add_node("web_search_node", web_search) # 网络搜索节点
# 构建工作流图的边缘连接
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# 编译工作流图为可执行的应用
app = workflow.compile()
print("✅ CRAG工作流图构建完成")
-
- 最后使用
CRAG系统来处理一些具体的问题。它会逐步执行图中的每个节点,并输出每个节点中的处理结果,最终生成答案。
- 最后使用
# ================================
# 运行CRAG系统
# ================================
def run_crag_demo():
"""运行CRAG演示"""
print("\n" + "="*50)
print("🚀 CRAG系统演示 - DeepSeek优化版本")
print("="*50)
# 测试问题列表
test_questions = [
"What are the types of agent memory?", # 关于智能体记忆类型
"什么是提示工程的主要技术?", # 关于提示工程技术
"深度学习在自动驾驶中的应用?", # 可能需要网络搜索的问题
]
for i, question in enumerate(test_questions, 1):
print(f"\n🔍 测试问题 {i}: {question}")
print("-" * 50)
# 准备输入
inputs = {"question": question}
try:
# 流式执行CRAG工作流
final_state = None
for output in app.stream(inputs):
for key, value in output.items():
print(f"📍 执行节点: {key}")
final_state = value
print("\n" + "🎯 最终答案:")
print("=" * 30)
if final_state and "generation" in final_state:
print(final_state["generation"])
else:
print("未能生成答案")
except Exception as e:
print(f"❌ 处理问题时出错: {e}")
print("\n" + "="*50)
if __name__ == "__main__":
# 运行演示
run_crag_demo()
-
- 根据不同的问题,生成答案示例结果
==================================================
🔍 测试问题 1: What are the types of agent memory?
--------------------------------------------------
---🔍 执行文档检索---
/home/ylins/project/rag-related/src/06-post-retrieval/03-correction/01_crag_deepseek_demo.py:368: LangChainDeprecationWarning: The method `BaseRetriever.get_relevant_documents` was deprecated in langchain-core 0.1.46 and will be removed in 1.0. Use :meth:`~invoke` instead.
documents = retriever.get_relevant_documents(question)
检索到 4 个候选文档
📍 执行节点: retrieve
---📊 评估文档相关性---
正在评估文档 1/4
✅ 文档相关
正在评估文档 2/4
❌ 文档不相关
正在评估文档 3/4
✅ 文档相关
正在评估文档 4/4
✅ 文档相关
📚 找到 3 个相关文档
---🤔 决策下一步操作---
📋 决策: 直接生成答案
📍 执行节点: grade_documents
---✨ 生成最终答案---
📍 执行节点: generate
🎯 最终答案:
==============================
Based on the context, the types of agent memory are short-term memory and long-term memory. Short-term memory is likened to in-context learning within the model's finite context window. Long-term memory relies on an external vector store for retaining and recalling information over extended periods.
==================================================
🔍 测试问题 3: 深度学习在自动驾驶中的应用?
--------------------------------------------------
---🔍 执行文档检索---
检索到 4 个候选文档
📍 执行节点: retrieve
---📊 评估文档相关性---
正在评估文档 1/4
❌ 文档不相关
正在评估文档 2/4
❌ 文档不相关
正在评估文档 3/4
❌ 文档不相关
正在评估文档 4/4
❌ 文档不相关
🔍 未找到相关文档,将进行网络搜索
---🤔 决策下一步操作---
📋 决策: 重写查询并搜索
📍 执行节点: grade_documents
---🔄 重写搜索查询---
原始问题: 深度学习在自动驾驶中的应用?
重写问题: 深度学习技术在自动驾驶系统中具体有哪些应用场景和实现方式?
📍 执行节点: transform_query
---🌐 执行网络搜索---
🔍 执行搜索查询: 深度学习技术在自动驾驶系统中具体有哪些应用场景和实现方式?
📚 使用模拟搜索: 深度学习技术在自动驾驶系统中具体有哪些应用场景和实现方式?
🎯 模拟搜索生成了 3 个结果
📋 返回前 3 个结果
✅ 搜索完成,获得 3 个结果
🔍 搜索工具返回 3 个结果
📄 结果 1: 深度学习在自动驾驶中的核心应用技术
📄 结果 2: 自动驾驶中的感知系统:深度学习算法详解
📄 结果 3: 自动驾驶决策规划中的深度强化学习应用
✅ 网络搜索完成,添加了包含 3 个结果的文档
📚 当前文档总数: 1
📍 执行节点: web_search_node
---✨ 生成最终答案---
📍 执行节点: generate
🎯 最终答案:
==============================
深度学习技术在自动驾驶系统中的应用主要包括四个方面:1)计算机视觉,使用CNN等网络进行目标检测和场景理解;2)传感器融合,通过深度学习算法整合多源传感器数据;3)路径规划,利用强化学习和RNN优化行驶轨迹;4)决策控制,采用端到端学习实现从感知到控制的直接映射。这些技术已被特斯拉、Waymo等公司广泛应用。
在整个流程中,CRAG系统先是检索与问题相关文档,接着评估结果文档。根据上面示例显示,如果找到与问题相关的文档,则直接生成答案。如果问题与检索文档内容完成无关,则会去进行转换查询优化操作和网络搜索获取结果,最终根据获取到的信息生成最终答案。
这一机制展示出了CRAG是如何根据不同的问题灵活的优化和调整它的检索和生成策略,来适应不同的场景需求。
总结
通过本文的深入解析和实践演示,我们全面了解了CRAG作为后检索优化技术的核心价值和实现方式。
CRAG的核心优势:
-
- 智能质量评估:通过轻量级检索评估器,系统能够主动识别检索文档的相关性,避免了传统RAG中"垃圾进垃圾出"的问题。
-
- 自适应检索策略:根据文档质量评估结果,智能决策是直接生成答案还是扩展到网络搜索,大大提升了系统的鲁棒性。
-
- 查询优化能力:当本地文档不足时,通过查询重写技术优化搜索效果,提高外部信息获取的准确性。
-
- 端到端可控性:整个流程具有清晰的决策逻辑和状态管理,便于调试和优化。
虽然CRAG利用大模型的能力提高了RAG系统的回答质量,但是在实际应用中,这种方法可能会因为增加了系统复杂性,从而增加系统的回答的响应时间,降低的整体系统的效率。所以,在确保生成答案的质量的同时,也要考虑系统的效率问题。
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】


为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐



 16
16 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)