- @python12345_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学****AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序

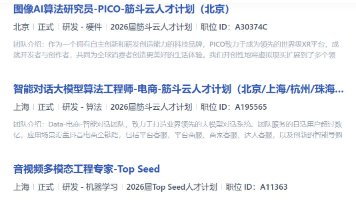
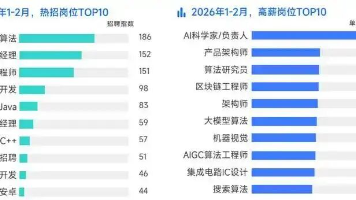
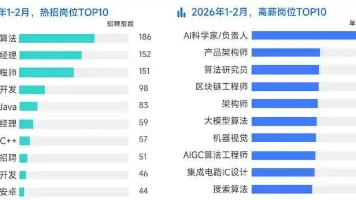
2026年技术圈的分化愈发明显:降薪裁员潮持续蔓延,传统开发、测试等岗位大批缩水,不少从业者陷入职业焦虑;与之形成鲜明对比的是,AI大模型相关岗位迎来疯狂扩招,薪资逆势飙升150%,大厂更是直接开出70-100W年薪,疯抢具备实战能力的大模型人才,甚至放宽年龄限制,只求能快速落地技术、创造价值!1、窗口期红利,入门门槛友好:不同于成熟赛道的“内卷式招聘”,2026年大模型人才缺口巨大,简历只要达标
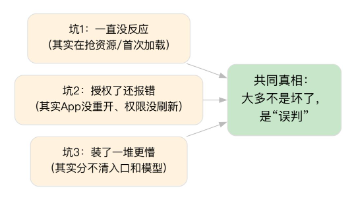
很多教程喜欢把本地 AI 讲得又复杂又高门槛。但对刚起步的人——尤其是想拿它降本增效的生意人来说,最有价值的起点其实很简单:先学会区分,什么是真的坏了,什么只是看起来像坏了。能分清这件事,你就不会每次卡一下就从头再来,而是更稳地往前走。这比多背几个模型名重要得多。如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。学AI大模型,就是冲刺高薪的最优解!零基础小白不知道从哪入门?有基础的