- @csdn_xmj
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文深入解析了Python中多重继承的C3算法,探讨了其原理、实现机制和实际应用。C3算法通过本地优先级规则和单调性规则生成方法的线性解析顺序,解决了多重继承中的冲突问题。文章详细演示了C3算法的实现过程,并分析了复杂继承场景(如菱形继承)的处理方式。同时展示了C3算法在混入类(Mixin)和框架扩展中的实际应用案例,说明如何利用该算法设计灵活、可维护的代码架构。最后强调理解C3算法对Python

本文来源公众号,仅用于学术分享,侵权删,干货满满。谷歌的AlphaEvolve,还在不断创造新的奇迹。而就在刚刚,patched.codes的联合创始人兼CTO Asankhaya Sharma,用基于AlphaEvolve论文的开源实现OpenEvolve,成功自动发现了高性能的GPU内核算法。具体来说,通过自我进化代码,它自动发现了一套在Apple Silicon上远超手动优化的GPU Met
pycryptodome是一个功能强大的Python密码学库,支持AES、RSA等多种加密算法,提供哈希计算、数字签名等功能。该库具有高性能C语言实现、安全默认参数和跨平台兼容性,适用于网络安全、数据保护等场景。文章介绍了其安装方法,并演示了对称加密(AES)、哈希算法(SHA)、随机数生成等基础功能,以及RSA加密、数字签名等高级应用。通过用户密码存储和文件加密的实际案例,展示了该库在提升系统安
Python的memoryview类型通过缓冲区协议实现零拷贝技术,显著提升了大数据处理的性能。它支持类型转换和高级切片操作,避免内存复制,在网络数据包处理中可减少内存分配和垃圾回收压力,在文件流处理中实现高效分块操作。实验数据显示,使用memoryview处理数据可大幅降低内存占用并提高处理速度,是优化Python程序内存管理的有力工具。掌握memoryview技术有助于开发者构建更高效的应用程
摘要:s3cmd是一个功能强大的Python库,用于与Amazon S3及其兼容存储服务交互。支持文件上传下载、存储桶管理、同步、加密等操作,同时兼容多种云存储服务。安装简单,可通过pip安装,并提供命令行和API接口。s3cmd适用于网站部署、数据备份等场景,能显著提高云存储管理效率。其丰富的功能包括分块上传、断点续传、权限管理等,是现代开发者处理云存储的理想工具。
《PyVision:动态工具生成推动视觉Agent新突破》 摘要: PyVision框架在多模态视觉推理领域实现重大突破,通过动态工具生成机制显著提升模型性能。该框架允许多模态大语言模型(MLLM)在多轮交互中自主生成、执行和优化Python代码工具,突破了传统静态工具集的限制。核心创新包括:1)构建交互式多轮推理框架;2)利用Python生态实现动态工具生成;3)建立五类视觉工具分类体系(基础/

本文介绍了Python库cleanlab,一个专注于检测和修复机器学习数据集中标签错误的工具。它支持自动标签噪声检测,兼容主流模型(如scikit-learn、PyTorch),适用于二分类、多分类及多标签任务。通过示例展示了其核心功能:识别错误标签索引、自动修正标签以及交叉验证评估。此外,cleanlab还提供高级功能如多标签分类处理和主动学习优先修复机制。该库能有效提升数据质量,从而优化模型性

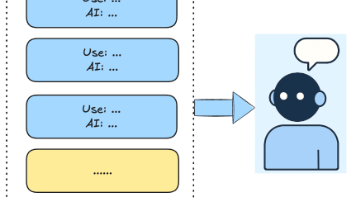
本文介绍了AI智能体8种常见的记忆策略,包括全量记忆、滑动窗口、相关性过滤、摘要压缩、向量数据库、知识图谱、分层记忆和类OS内存管理。每种策略都有其优缺点和适用场景,如全量记忆简单但易超限,滑动窗口节省资源但健忘性强,向量数据库支持长期记忆但依赖嵌入质量。文章通过模拟代码帮助理解不同策略的实现原理,并指出应根据具体需求选择合适的记忆方案,以平衡记忆能力、计算成本和系统复杂度。
DeepSeek V3.1新版发布,编程能力碾压Claude 4 Opus,支持128K上下文,成本仅1美元。该模型在Aider基准测试中得分71.6%,超越Claude 4,同时推理速度更快。新增原生搜索支持,架构可能转向混合推理。实测显示其处理长文本和编程任务表现优异,但仍有改进空间。网友期待其后续版本R2的发布。

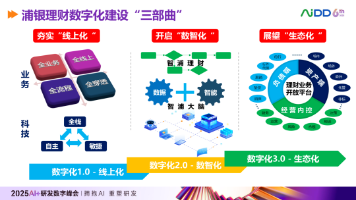
浦银理财推出AI员工助手,通过四层架构(数据层、模型层、Agent层、应用层)实现智能服务。该助手具备办公助理、运营秘书、知识管家、分析顾问四大功能,依托AI服务中台提供知识智能化、服务自动化等能力。其技术采用五步构建法,包括需求定义、模型选型、本地部署、RAG增强和系统集成。中台架构分为服务网络、应用中心、系统中心和基础设施四层,支持多知识库管理和自动化业务流程。案例展示了AI从工具到智能体的演