登录社区云,与社区用户共同成长
邀请您加入社区
当前,企业知识管理普遍陷入多重困境:海量文档散落在各系统、各部门,形成难以打通的知识孤岛;隐性经验藏于员工脑中,难以显性化、标准化沉淀;传统关键词检索效率低下,员工耗费大量时间查找信息,知识利用率极低;知识库维护成本高、更新滞后,问答准确率不足,难以支撑业务高效运转。这些痛点,成为制约企业数字化转型、智能化升级的关键瓶颈。
看完你能得到什么:**一个跑在本地的私有RAG知识库,上传文档后可以直接对话提问。**全程断网可用,数据不出你的电脑。
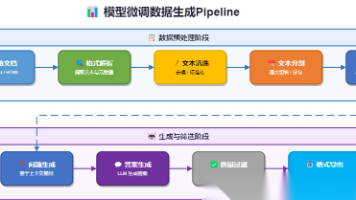
模型微调的效果,既依赖于基座模型的能力,也和用于后训练的数据集有很大关系。在大模型没有出现的时代,从零制作一份高质量的数据集的SOP是这样的:人工收集语料->搭建标注平台->人工标注->人工审核->最终导出,低效、昂贵且痛苦。
本文介绍了如何将Neo4j知识图谱与RAG系统结合,构建GraphRAG解决方案,以解决传统RAG在复杂关系推理上的不足。主要内容包括: GraphRAG架构:通过Neo4j存储和查询实体关系,LLM生成答案,实现从扁平检索到关系推理的升级。 系统实现: 双路检索:根据查询复杂度自动选择向量检索或图谱检索 知识图谱构建:演示了从JSON数据创建医疗领域实体和关系的Python代码 混合检索:结合语
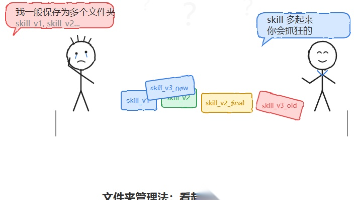
上周有个粉丝去面大模型,二面聊到大模型应用开发,面试官问了一个他觉得"不怎么重要"的问题:> 👔 你项目里用了不少 Skill,怎么做版本管理的?
多模态代理 AI(Multimodal Agent AI,MAA)是一类基于多模态感知输入理解而生成有效动作的系统。随着大语言模型(LLM)和视觉语言模型(VLM)的发展,许多 MAA 系统在从基础研究到应用的各个领域中不断涌现。尽管这些研究领域通过结合各自领域的传统技术(如视觉问答和视觉导航)迅速发展,它们在数据收集、基准测试和伦理视角方面具有共同的关注点。本文着眼于 MAA 的一些代表性研究领
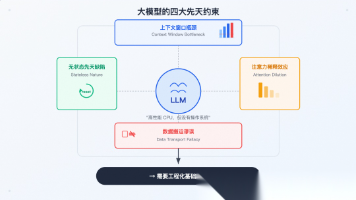
本文系统性地回顾了我们在构建企业级 AI Agent 平台过程中走过的完整技术演进路径——从大模型的先天约束出发,经历 Prompt 工程、Context 工程、Harness 工程三个阶段,最终演化出一套五层架构的 Agent 操作系统。每一层的出现都是因为前一层遇到了天花板。
我们使用neo4j可能会遇到这样的情况:想要把图数据库备份到另一个数据库中,但我们使用的是neo4j社区版,并不能同时保存多个数据库。这时候我们就需要把neo4j的节点和关系进行导入和导出,而不需要覆盖原来数据库的数据。下面进行演示:这里以neo4j的桌面版(1.6.1,5.24.0)、服务器neo4j-community-2025.01.0为例。
neo4j下载
下载并且解压# 添加环境变量# 添加以下内容# 生效。
借助Py2Neo和ECharts,项目实现了旅游信息的图谱展示,系统自动展示100个节点和它们之间的关系。如果你正在苦恼选什么项目做毕业设计,或者对旅游、人工智能、数据可视化感兴趣,那么千万别错过这款基于Neo4j的互联网智能问答与旅游图片展示系统!😎它不仅实用,还拥有丰富的数据资源,技术亮点也是满满的。不仅能让你轻松应对导师提问,还能展示自己的技术实力,做出一个经典且实用的项目!它为你提供了一
烹饪美食不再难!毕业设计头疼选题?或许你只需这个——。
这个系统是围绕着“鸟类百科知识图谱”打造的,结合了时下最热门的技术——Neo4j知识图谱和Django框架。系统里包含了丰富的鸟类信息(6000+实体和10000+关系),并支持基于自然语言的问答。超酷炫的功能展示,分分钟让你惊艳导师和同学!
还在为毕业设计题材发愁吗?今天给大家安利一个干货满满的项目——“适合毕业设计、学术研究甚至做些小创新😎。
一、3.5版本到4.X版本有哪些优化升级二、3.X版本的neo4j中的各种配置环境三、迁移参考四、用GPT写了一下,也不成功。
neo4j备份与还原
烧录树莓派系统,ssh1.在SD中的boot区中,新建两个文件ssh(没有任何后缀)和wpa_supplicant.conf。2.往wpa_supplicant.conf中写入country=CNnetwork={ssid=“wifi账号”psk=“wifi密码”换清华的源,国内可供选择的Linux软件源还是有不少的,,腾讯源,清华源,中科大源等等,各位读者可以自由选择喜欢的软件源进行使用。笔者这
4和5两个版本数据库位置不同,官方不建议更新。因此如果下载了旧版本的neo4j并且在网页上注册登录后,再删除并下载新版本就可能出现网页无法访问。
重复的APOC配置项(也就是之前在neo4j.conf里加入的配置需要删除)访问GitHub发布页面下载对应版本(输入自己对应的版本号):Neo4j v5要求APOC配置必须放在独立的配置文件中。成功安装会返回版本号。
同一簇的节点之间的关系成为自关系,与其他簇的节点的关系连接到簇代表。该算法将节点分成不相交的社区,以便最大化每个社区的模块度得分。模块度量化了将节点分配给社区的质量,即与随机网络中的节点连接程度相比,社区中节点的连接密度如何。模式,并产生了一个重要的副作用:将每个节点的社区 ID 作为属性写入 Neo4j 数据库。Leiden 算法是一种分层聚类算法,通过贪婪地优化模块性,将社区递归合并为单个节点
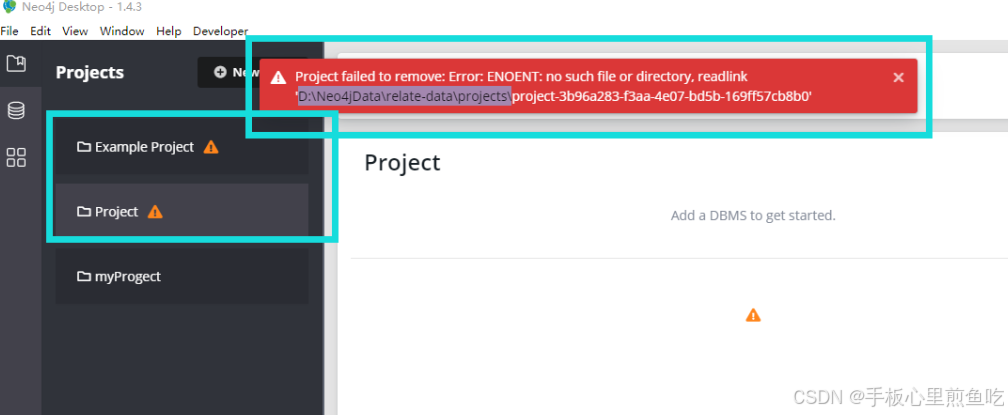
我个人觉得第一种比较简单,但是 很多人说需要使用管理员身份才能删除,我不知道怎么使用管理员身份来删除.....并且我删的时候会提示:操作无法完成,因为文件已在Neo4j Graph Database - neo4j 中打开;这说明 Neo4j 的 Windows 服务(Service)正在运行,并且已经锁定了数据库。删除databases文件夹下的内容:/data/databases下的文件。找到
下载完装不上去,docker desktop一直打不开,可能是有什么冲突,换个方式,直接下载。我使用的是neo4j4.4.1,关系类型里不能直接使用中文,如果你需要在关系中使用中文描述。如果使用的是 JDK 11,可能需要使用较低版本的 neo4j-java-driver。之前可以直接显示中文关系,用的neo4j4.x版本不能直接显示关系,应该可以修改。,如果文件读错线就不会显示,如果不确定是不是
本文介绍了Neo4j图数据库的基本概念及其在反序列化漏洞检测中的应用。Neo4j由节点、属性、关系和标签构成,使用Cypher查询语言。文章详细演示了如何安装Neo4j Desktop并创建数据库实例,重点展示了通过Cypher语句构建Java类方法调用图的完整过程,包括创建类节点、方法节点以及它们之间的继承、调用和别名关系。这种图数据库结构特别适合存储和查询方法调用链,为反序列化漏洞检测中的ga
社区检测的目标是将网络划分为若干子图(社区),使得社区内部边的密度显著高于社区之间。强社区:社区内每个节点的内部连接数均大于外部连接数。弱社区:社区整体的内部连接数之和大于外部连接数之和。社交网络:识别用户的朋友圈、兴趣群体,助力精准推荐。生物网络:发现蛋白质功能模块或代谢路径。网络安全:检测异常行为集群,如金融欺诈或网络攻击组织。信息传播:分析疫情或谣言在社区间的传播路径。
neo4j desktop 重装几次之后,数据库出现感叹号,而且出现了以前的数据库,且无法删除。
3.登录账号和密码都是neo4j。
然后要再下载java17,按照步骤配置环境变量(换JAVA_HOME为新文件夹)后一直不成功,后来休息了一个小时就成功了,说明Java的配置需要时间。http://localhost:7474 从这个网址进入之后 输入用户名和密码都为neo4j,数据库空着就行,下一步就是更改新的密码了。然后根本就下载不了,找了很长时间都没找到,后来在其他地方找到了资源。从下面这个网站进入,注册登录,保存好用户名和
本文介绍了Neo4j数据库的版本与JDK对应关系及安装使用方法。Neo4j 3.x对应Java 8,4.x对应Java 11,5.x对应Java 17。安装时需从官网下载对应版本,配置NEO4J_HOME环境变量并通过命令行验证。使用时可访问http://localhost:7474,默认用户名密码均为neo4j。Neo4j支持前台运行(终端关闭即停止)和后台运行(注册为Windows服务)两种模
在Neo4j中删除所有节点后,标签仍会保留。要彻底删除标签,需先运行":schema"命令查看索引信息,然后针对每个目标标签(如"Product"和"Supplier")复制其对应的IndexName,执行"drop index index_xxxxxx"命令删除相关索引。通过这种方式可以完全清除标签。该方法解决了节点删除后标签残留的问题。
Neo4j 是一个广泛使用的图形数据库管理系统(Graph Database Management System)。它是一种NoSQL数据库,专为存储和查询图形数据而设计。Neo4j 支持图形数据模型,允许用户以节点(Nodes)和关系(Relationships)的形式存储数据,并通过属性(Properties)来丰富这些节点和关系。
解决neo4j数据库初始账号密码登入不上的问题
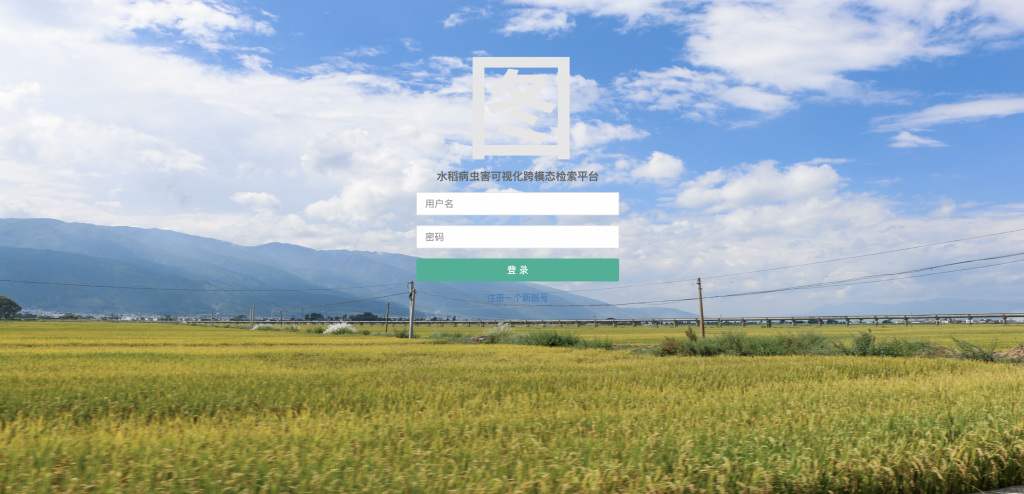
我们特别设计了初始化数据接口,并附带详尽的README.md文档,方便用户根据需求对数据进行调整和扩展,让你可以轻松上传和修改多模态数据,实现个性化的使用体验。我们推出的这一系统,专为水稻病虫害的多模态可视化管理而设计,核心功能强大,通过查询关系图谱,可以清晰展示各类病虫害的属性及其相互关系。:用户可通过标签查询功能,查看系统中所有节点类型,点击后可获取该节点的详细信息及相关数据展示,提升用户的使
图的相似度算法是图论和网络科学中的核心研究领域,用于衡量两个图之间的结构或属性相似性,广泛应用于社交网络分析、生物信息学、推荐系统等场景。注:SimGNN等GNN方法通过预计算图嵌入(O(E))显著降低在线计算时间,适合实时场景。
本文研究基于SpringBoot和Vue的汽车领域智能问答系统。随着汽车普及,传统信息获取方式效率低,该系统通过自然语言处理等技术实现高效自动化问答。研究分析了国内外智能问答系统发展现状,指出国内在汽车领域应用仍面临准确性不足等问题。系统采用前后端分离架构,前端使用Vue框架实现交互界面,后端采用SpringBoot处理业务逻辑,MyBatis进行数据持久化。通过可行性分析表明,系统在经济、技术和
错误: 加载主类 org.neo4j.server.startup.Neo4jCommand 时出现 LinkageError
突然有需求需要用apoc 导入 低版本的图谱数据,网上资料又比较少,所以就看官网资料并处理了apoc 导入的一些问题。
在这篇博客文章中,我们展示了如何将微软的 GraphRAG 集成到 Neo4j 中,并使用 LangChain 和 LlamaIndex 实现检索器。这将允许你无缝地将 GraphRAG 与其他检索器或代理集成。局部检索器结合了向量相似性搜索和图遍历,而全局检索器则通过遍历社区摘要来生成全面的回答。这种实现展示了将结构化知识图与语言模型相结合的力量,从而增强了信息检索和问答能力。值得注意的是,这样
做 AI 智能体总卡壳?要么写代码写到头秃,要么用现成工具改不了逻辑,要么搭出来的智能体响应慢、报错多、根本没法落地用?作为 0 代码入门的新手,你是不是也想:1、 不用啃 Python/Java,快速搭出能实际用的智能体2、 兼顾高可用(稳定不崩)+ 自定义(贴合自己的业务)3、7天就能看到成品,不是学半年还摸不着门?别慌!我亲测用 Dify+Coze 组合拳,纯可视化操作,7 天从 0 到 1
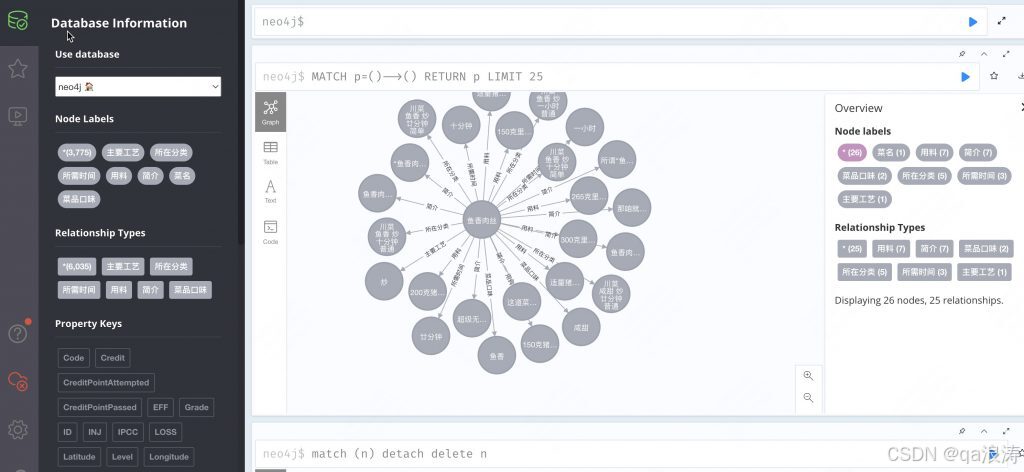
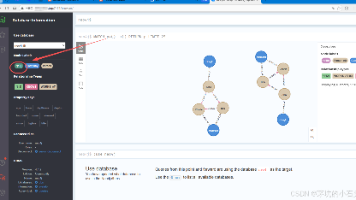
这个简单示例展示了Neo4j的核心概念:带标签的节点、带类型的关系以及属性。你可以通过修改这些示例来创建自己的图形数据模型。你可以点击节点展开或折叠相关关系。
Flask 是一个使用 Python 编写的轻量级 Web 应用框架,被称为 “microframework”。它的设计理念是保持简单,没有默认使用的数据库、窗体验证工具或其他预装的组件,核心构成比较简单,但具有很强的扩展性和兼容性,这使得开发者能够灵活地选择他们想要使用的组件,根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,使其更适合于小型和中型应用程序的开发。
本文介绍了在Spring Boot项目中集成Neo4j图数据库的方法及其应用场景。Neo4j采用"节点+关系+属性"的存储模型,特别适合处理社交网络、推荐系统等连接密集型数据。文章详细展示了环境搭建、数据建模和关系查询的实现步骤,并通过实验对比证明Neo4j在多层级关系查询中的性能优势(10万节点场景下查询耗时仅为关系型数据库的1/26)。最后指出Neo4j适用于关系密集型业务
本文介绍了Neo4j中数据导入的核心语句及其用法。主要包含四个关键部分:1) LOAD CSV用于读取CSV文件数据;2) FROM指定文件路径;3) MATCH查找已有节点;4) MERGE实现"存在即用,不存在则建"的功能。文章通过实例详细解析了节点和关系的导入过程,并提供了各语句的使用场景速查表。最后总结为:LOAD负责读取数据,MATCH查找已有节点,MERGE防止重复
neo4j
——neo4j
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区




 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区

 智能体开发者社区
智能体开发者社区