
人工智能发展简史8:BERT——让 AI 学会 “双向看上下文“
2018年谷歌推出的BERT模型开创了自然语言处理新范式。该模型基于Transformer编码器,首次实现双向文本理解,通过"遮字猜词"和"判断连贯"两个预训练任务掌握深层语义。BERT提供BASE和LARGE两种规模,在GLUE等基准测试中表现卓越,部分指标超越人类水平。其突破性在于采用预训练-微调框架,使各类NLP任务可共享基础模型,大幅提升泛化能力。BERT不仅被应用于搜索引擎优化(如谷歌、
2018 年,谷歌推出了BERT(Bidirectional Encoder Representations from Transformers),刚诞生就刷新了 11 个自然语言处理(NLP)任务的纪录 —— 相当于刚上考场就拿了 “全科第一”,一下子成了 AI 圈的 “明星”。这是第一个真正意义上统一自然语言处理任务的预训练模型。BERT 的核心使命是:让 AI 像人一样,真正理解句子里的上下文关系,而不是只机械地 “读字”。

图 1 BERT(Bidirectional Encoder Representations from Transformers)
BERT的模型架构基于Transformer编码器,BERT 的最大创新在于其双向编码能力,能够同时从前后两个方向理解文本,而不是像传统模型那样只能单向处理。
BERT的模型架构主要有两种尺寸:BERTBASE(L=12, H=768, A=12,总参数110M)和BERTLARGE(L=24, H=1024, A=16,总参数340M)。其中,L表示编码器层数,H表示隐藏层大小,A表示自注意力头数。
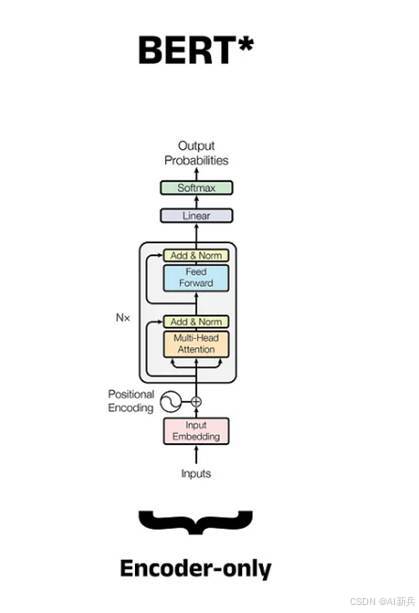
图 2 BERT Encoder架构
BERT 通过两个 "小游戏" 来训练自己理解语言:
1)遮字猜词:将句子中的某些词用 [MASK] 代替,让模型根据上下文预测被遮盖的词。例如,"猫坐在 [MASK] 垫子上",BERT 需要预测出正确的词是 "柔软的" 或 "暖和的" 等。
2)判断连贯:判断两个句子是否是连续的上下文。例如,"床前明月光" 和 "疑是地上霜" 是否是上下句。
这种训练方式让 BERT 真正理解了语言的语境。以前的 AI 分不清 "他喜欢苹果,因为它甜" 里的 "它" 指的是什么,而 BERT 通过双向编码,能够轻松理解 "它" 指的是苹果。
BERT 的应用非常广泛。谷歌将其应用于搜索引擎优化,当用户搜索 "杭州哪里吃东坡肉" 时,BERT 不再只认关键词,还能理解 "吃" 的需求,推荐更精准的餐厅。美团也使用 BERT 优化搜索结果,提升用户体验。
BERT在多个自然语言处理任务上取得了突破性进展。在GLUE基准测试中,BERTLARGE达到了80.5分,比之前的最佳结果提高了7.7个百分点;在MultiNLI自然语言推理任务中,准确率达到86.7%,提高了4.6个百分点;在SQuAD v1.1问答测试中,F1分数达到93.2,超过了人类表现(91.2分)。
BERT的成功对自然语言处理领域产生了深远影响。它证明了双向预训练对于语言表示的重要性,开创了基于大规模预训练模型的自然语言处理新范式。BERT的预训练-微调框架使得各种自然语言处理任务可以共享同一基础模型,大幅减少了对特定任务架构设计的需求,显著提高了模型的泛化能力和效率。BERT的开源和广泛应用促进了自然语言处理领域的研究和发展,激发了大量基于Transformer的改进模型和应用创新。
BERT 的出现,不是让 AI “变聪明” 了,而是让 AI “更懂人” 了。它打破了之前 AI “单向读句子” 的局限,用 “双向理解” 和 “预训练 + 微调” 的模式,从技术角度看,BERT开启了大模型时代的序幕,为后续更大型、更强大的预训练模型奠定了基础。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)