




- @2401_85373396
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这篇文章摘要了AI Agent(智能体)的行业现状与发展趋势。近年来,AI Agent市场潜力被广泛看好,Gartner、德勤等机构预测到2028年AI Agent将广泛应用于企业和日常生活。2024年下半年起,京东、微软等企业已大规模应用智能体,同时二级市场和Web3领域也涌现相关热潮。文章从技术架构、爆发原因和大公司动态三方面分析AI Agent的现状,并展望其未来趋势。随着技术进步和商业化落

人工智能正在让很多行业消失,只是大多数人还感觉不到。很多人以为的消失,是人的消失:干这行的人少了,少到一个都没有了,这个行业才算真正消失。红利少了,行业赚钱难了,优秀人才转行了,这就是行业消失的开始。从行业消失的开始,到在这个行业混饭吃的大多数普通人混不下去了,还需要一段时间。从普通人不卷了,到坚守行业的最后一人寄了,又需要一段时间。这段时间通常对于历史很短,对于个人又很长。所以,我更关注行业利润
AI Agent是一种基于大语言模型(LLM)的智能代理系统,通过整合规划、记忆、工具使用等能力,实现自主感知、决策和执行任务。相比单一LLM,AI Agent能突破模型的知识限制,利用外部工具获取最新信息、执行复杂计算,并具备独立思考能力。其技术发展经历了符号代理、反应式代理、强化学习代理等阶段,当前LLM-based Agent已成为主流。AI Agent可应用于求职、科研等场景,通过多模块协
本文介绍了MCP智能体多Agent协作系统设计,通过构建基础智能体基类(Agent Base)和多个专用子智能体(FileAgent、KnowledgeAgent、SummaryAgent),实现任务并行处理。系统采用总控智能体(OrchestratorAgent)进行任务分配和结果聚合,相比单智能体具有更好的扩展性、容错性和处理效率。文章详细阐述了系统架构设计、各智能体职责分工及实现方法,并展示

别再看国外了,谁说国内没有好教程!国内AI圈硬核好课 —— 上海交大教授团队重磅发布的全套AI Agent系统学习路线,一经曝光就引爆全球技术圈,无数开发者连夜蹲守学习,彻底打破 “Agent 只有高端人才能玩” 的壁垒!

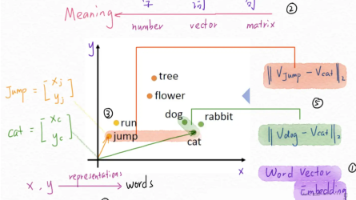
LLM大模型与Embedding模型在NLP中有显著区别:LLM主要用于文本生成和理解,而Embedding模型则将文本转换为数值向量,用于相似度计算和信息检索。在RAG(检索增强生成)系统中,单独设置Embedding模型可提升效率,降低资源消耗。系统流程包括知识库构建(文档向量化存储)、检索(问题向量化匹配)和生成(LLM结合上下文输出答案)。推荐使用OpenAI、Google等提供的Embe
本文详细介绍了在Windows系统上部署Ollama大语言模型服务的完整流程。主要内容包括Ollama的下载安装、模型文件目录修改、模型选择与下载、端口号配置及Dify集成等关键步骤。文章特别提供了BGE-M3嵌入模型的测试方法,并解决了Dify集成时常见的端口配置问题。通过图文并茂的教程,帮助用户轻松实现本地大语言模型的部署与应用,为构建个性化AI智能体提供了完整解决方案。文末还附赠了大模型学习
本文详细介绍了在Windows系统上通过WSL2部署vLLM框架运行大模型的完整流程,包括WSL2安装、环境配置、vLLM安装、模型下载与部署等步骤,帮助用户在本地成功运行大模型服务,并通过接口调用AI。教程适合Windows用户特别是小白群体学习,提供了详细的命令操作和参数解释,让读者能够轻松实现大模型的本地部署和应用。
本文聊聊 LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上——创造价值。使用LLama-Factory,常见的就是训练LoRA模型
本文对比分析了六种主流大模型部署方案:Transformers(Hugging Face生态,快速部署多种预训练模型)、ModelScope(阿里云PAI一站式服务)、vLLM(高效GPU推理优化)、Llama.cpp(C语言高性能量化推理)、Ollama(本地化轻量部署)和TGI(自定义模型服务框架)。每种方案均从部署方法、适用场景及优缺点三个维度进行说明,并附有具体代码案例。Transform
