登录社区云,与社区用户共同成长
邀请您加入社区
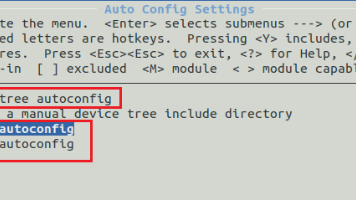
Xilinx SDKSOCPS
快速创建跟已有云服务器相同软件环境,或进行环境备份;
购买了XILINX ARTIX-7系列的fpga开发板,在vivado上写完代码跑完仿真后进行板级验证,但是在hardware management里中选择auto connect后无法连接到板子。解决方法:检查物理连接,保持板子接电且上电了。在建立项目的时候不要选择错板子的型号。查看USB的驱动有没有安装好。如果在设备管理里如上图,则重新下载驱动。位置如下图:下载完后可见:可能是另一个驱动没安装
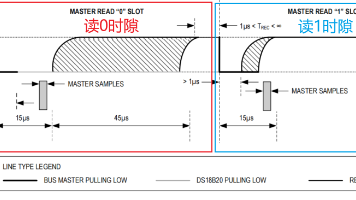
本文介绍了使用FPGA读取DS18B20温度传感器的实现方案。DS18B20采用单总线协议,仅需一根数据线即可完成通信。文章详细分析了单总线协议的初始化、读写时序,并给出了完整的FPGA实现代码。系统通过状态机控制DS18B20的初始化、温度转换和数据读取过程,将获取的16位温度数据解析为符号位、整数部分和小数部分,最终通过UART以"±XX.XX C"的格式每秒输出一次温度值
本文深入剖析了实盘杠杆交易系统中的全链路延迟工程,揭示了纳秒级延迟优化对高频交易的关键意义。文章系统性地介绍了三种核心技术路径:Kernel Bypass(DPDK/OpenOnload)绕过操作系统内核实现微秒级网络处理;FPGA硬件加速将核心交易逻辑固化至硅片,实现纳秒级确定性延迟;以及CPU核隔离、NUMA感知等软件级极致调优。通过对比联华证券、中国银河证券、中泰证券三家头部机构的技术架构差
西安威嵌神州这款套件配套的例程分的很细,按步骤走能省不少搭环境的时间。最后提一句量产衔接的问题,这款开发板和量产核心板是同源设计,开发板采用低成本架构,硬件配置和上装量产产品完全对齐,在开发板上调通的驱动、算法和应用逻辑,后期可以直接平移到量产板上,不用再做大规模的软件移植,项目转量产的时候能省很多事。这段时间帮客户调了几个基于 FMQL100TAI 的实时图像处理项目,都是跑天脉操作系统,中间踩
本文介绍了SoC实验所需的软件安装方法,主要包括两部分内容:1)在Windows系统下安装Vivado 2019.2开发工具,详细说明了从官网或百度网盘下载安装包、解压安装、版本选择和配置参数的完整流程;2)在WSL2环境下安装Ubuntu 22.04.5操作系统,并建议配合VSCode的WSL插件进行代码编辑。文章提供了各步骤的界面截图和参考链接,帮助用户顺利完成实验环境的搭建。Vivado安装
脉冲压缩模块采用频域匹配滤波,使用Xilinx FIR Compiler IP核,滤波器阶数为512,输入数据位宽16bit,输出位宽24bit。CFAR检测模块实现单元平均恒虚警,参考窗长度左8右8,保护单元左右各2,通过BRAM存储距离-多普勒谱,逐点计算阈值并与信号幅度比较。处理后将点云投影到二维平面,对比传统FFT测角,RELAX算法角度分辨率从7.5度提升至2.3度,虚假点减少约35%。
飞腾D3000M国产高算力子卡以86×83mm超小尺寸实现高性能突破,搭载2.9GHz国产CPU和16GB LPDDR4X内存,支持双国产操作系统,配备MRAM断电存储模块,适应-55℃极端环境。该产品针对狭小空间高算力需求痛点,解决传统国产设备体积大、内存不足(8GB)、断电数据易失等问题,提供100%国产化解决方案。核心优势包括:迷你体积下保持高运算性能、大内存支持多线程并发、国产MRAM确保
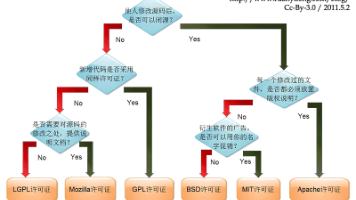
本文介绍了使用MicroPython进行嵌入式开发的优势及其项目架构。MicroPython通过预置硬件驱动和底层库,降低了开发难度和移植成本,其MIT许可也确保了开放性。项目架构采用"核心+端口"模式,核心包含Python编译器和运行时,端口则针对不同硬件平台适配。目录结构清晰划分功能模块,如交叉编译器、外设驱动和测试工具等,并支持多种主流MCU平台如ESP32、STM32和RP2040等,兼具
摘要: 参赛学生对近期规则调整提出建议:1. 针对禁止压红块的改动,建议适当增加模型罚时,以平衡绕行策略的难度;2. 垫高目标板20mm的规则导致原有数据集大部分失效,需重新采集数据,恰逢期末与备赛期叠加,时间压力较大。卓老师回应称模型罚时标准将在6月6日会议最终确定。学生强调规则变动突然,希望组委会考量实际困难。(149字)
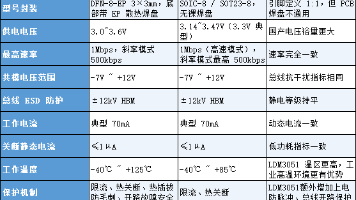
描述LDM3051是一款应用于CAN协议控制器和物理总线之间的接口芯片,与具有CAN控制器的3.3V微处理器、微控制器(MCU)和数字信号处理器(DSP)或者等效协议控制器结合使用,具有高速、斜率控制、待机、低电流关断四种工作模式,共模范围可达-7V~+12V,可应用于工业自动化、控制、传感器和驱动系统,电机和机器人控制,楼宇和温度控制,电信和基站控制及状态等领域。
LMD9253是一款高性能4通道14位模数转换器(ADC),支持80/125MSPS采样率,采用1.8V单电源供电,具有低功耗(每通道144mW)和小尺寸封装特点。该器件提供出色的动态性能(SNR达75.1dBFS,SFDR达92dBc),内置采样保持电路和多种测试功能,支持LVDS串行输出。其宽工作温度范围(-40℃至+85℃)和灵活的时钟配置使其适用于医疗影像、雷达系统、数据采集等应用场景,4
即嵌入式,多媒体卡是一种闪存卡的标准,它定义了基于嵌入式,多媒体卡的存储系统的物理架构和访问接口及协议。Ø Cmd:用于传输从主机端发出命令command和emmc卡端发出回应得response。等长要求:数据线(0-7),CLK,CMD。Ø Data strobe 数据锁存信号,emmc 卡端得输出信号。Ø Data0-data7 :用于在主机和emmc卡间传输数据。Ø Rest:复位信号线,主
Verilog 实现的 FPGA 运动目标检测系统,包含摄像头采集、SDRAM 双帧缓存、灰度帧间差分、腐蚀膨胀、目标框叠加和 VGA 显示,适用于 Quartus 与 Cyclone IV 开发板验证。
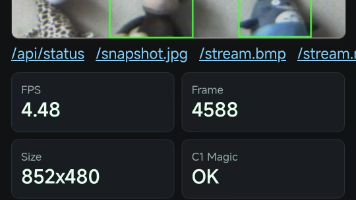
本项目基于开发板,实现了一套完整的FPGA硬件加速YOLO实时目标检测 + WiFi无线图传方案。系统上电后自动开启WiFi热点,手机/电脑连接即可通过浏览器实时查看摄像头画面和AI检测结果,无需安装任何APP。主控芯片:Xilinx Zynq-7020(双核ARM Cortex-A9 + FPGA Artix-7)摄像头:MIPI接口摄像头,Bayer格式输出分辨率:852×480帧率:优化后可
本教程面向已掌握FPGA基础开发、熟悉AXI总线与DMA架构、希望入门FPGA AI加速的开发者。我们以已跑通的单通道3×3卷积 + 2×2最大池化工程为起点,不追求极致性能优化,先建立「CNN算法原理 ↔ PyTorch软件训练 ↔ FPGA硬件实现」的完整架构认知,逐步补全CNN标准组件,最终打通端到端全链路。教程全程遵循「最小增量迭代」原则:每一步只修改少量代码,完成后立刻与软件结果对齐验证
本文介绍了一款高精度PCIe授时板卡的工作原理及典型应用场景。该板卡通过多源时间基准采集(GNSS、PTP、IRIG-B等)、恒温晶振驯服与守时技术,实现≤30ns的同步精度,支持硬件直连主机同步。典型应用包括:电力系统故障录波(多设备时序统一)、5G基站测试(PTP主/从授时)、金融高频交易(纳秒级时间戳合规)、科研仪器同步(10MHz基准频率)以及工业自动化(多机器人协同)。板卡具有多源冗余切
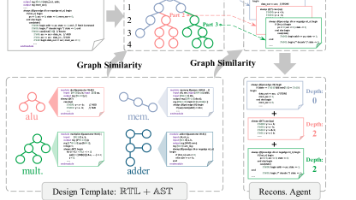
单模块测试包含 add64、mult32、comput、traffic、alu、radix、asyn、accu、fpu_pre、fpu_post、mc_sel、mc_rf、buffer、eth 等设计,平均 217 行、763 个节点、1005 根 wire。功能等价率仍能保持,但 PPA 变差,延迟、面积、功耗比例分别来到 0.89、0.92、0.94,远弱于完整系统的 0.72、0.73、0.
支持 AI PPT 生成、Excel 智能分析、Word 策划、AI 生图、多模态搜索、智能问答、图片自动分类,企业版免费使用依托通义千问大模型,支持文档摘要、文件语义检索、知识库问答,基础 AI 功能可正常使用。很多团队分不清两者的定位、AI 能力、对外分享、性价比差异,难以精准匹配自身企业的办公需求。欢迎评论区交流使用体验!综合来看,综合 AI 生产力、对外分享生态、大文件传输、性价比以及全场
Mac Studio M3 Ultra明显占优。它拥有四倍内存容量和三倍理论内存带宽,特别适合单机加载超大模型、处理大型媒体工程和承担综合性专业工作。DGX Spark仍然有自己的护城河。CUDA、TensorRT-LLM、vLLM、NGC和NVIDIA服务器生态,使它更适合真正围绕NVIDIA平台进行模型开发、微调、验证和部署。Mac Studio是一座容量巨大、传送带很宽的全能仓库;DGX S
ALINX 将继续深耕 FPGA+GPU 异构计算在医疗影像领域的技术创新,与行业伙伴共同推动中国内窥镜与手术机器人产业走向更广阔的全球市场,为生命健康注入更多科技力量。ALINX 的异构方案把 FPGA 的实时性和 GPU 的 AI 算力结合起来,以应对医疗 AI 对实时性 AI 推理的严苛要求。,配合 4 个 FMC+ 接口,为多传感器融合、复杂算法并行加速等前沿场景提供了更大的开发空间。此外
1、一般情况下是因为Vivado的驱动没有安装好,只需要将驱动安装上即可,路径为Vivado\2018.3\data\xicom\cable_drivers\nt64\digilent\install_digilent.exe 建议在安装的过程中,将。,安装驱动成功后在重新开始打开vivado进行连接;否则可能会在安装后也不能正常连接。2、如果安装不了,需要下载最新驱动来安装,安装后打开vivad
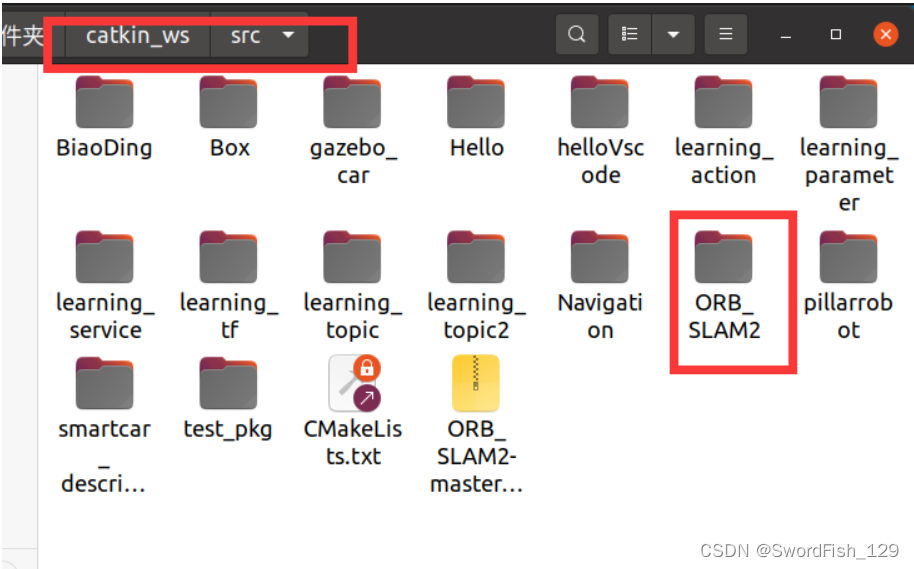
下载链接:https://gitcode.com/raulmur/ORB_SLAM2/overview?链接:https://www.cvlibs.net/datasets/kitti/eval_odometry.php。在控制台输入:export ROS_PACKAGE_PATH=${ROS_PACKAGE_PATH}注意:直接从github下载下来。解压之后进行编译,注意安装0.5版本的,不然
SimuCard可与工业现场硬件构架平台结合,运用特有的部分动态重配置技术,便捷地将MATLAB、MWORKS生成的数学模型比特流文件部署到板卡的FPGA核心上,实现硬件在环强实时仿真。此外,借助仿真卡的高速接口,搭配多种类型、资源丰富的扩展子板,可对模拟、数字、混合信号、光电信号等全类型、多协议信号的仿真和解析,特别适用于电机驱动器、电机负载、机器人关节驱动等仿真应用场合,也可进行定制化设计,满
测评这款MES2K100国产多核异构SOPC开发平台,紫光同创Kosmo2器件,集成双核ARM Cortex-A53、DSP及MIPI、PCIE Gen3等硬核接口,配备丰富的通用外设,凭借极致灵活、高性价比及开箱即用的特性,全面赋能计算机视觉、工业控制与物联网等千行百业,标志着国产异构计算正加速迈向实用化与普及化。国产化趋势不可逆,国产化大时代。
给 Codex 接入 Erie Verilog Generator v0.4.0,让它生成一个带一级缓存的 Ready/Valid 流水寄存器和自检查 Testbench,然后在 macOS 上用 Icarus Verilog 做真实仿真,再用 Yosys 检查综合结构。接口明确、逻辑规模不大的模块,比如协议适配壳、寄存器切片、计数器、简单仲裁和控制状态机,适合走完整生成流程。变化在于,它接到任务
它是一款设计目标非常专一的定时器,核心功能就是产生精确的周期性中断,结构简单,配置方便,适用于像LED精确翻转、按键消抖、操作系统时间片调度这类需要稳定周期信号的场景。是 i.MX6ULL 等 ARM 处理器中的一个多功能定时器模块,用于实现各种定时、计数、输入捕获和输出比较功能。相比EPIT,它的功能要丰富和强大得多,是一个真正的多功能定时器模块。:它可以选用IPG_CLK等多种时钟源,并支持1
当设计趋于稳定,借助FPGA原型验证的高运行速度,为软件团队提供接近真实芯片的执行环境(Pre-silicon Software Execution),在系统层面并行开展操作系统移植、驱动与BSP开发、应用级验证等工作,消除硬件设计与软件开发之间的等待壁垒,实现真正的软硬件协同。在RTL早期阶段,利用硬件仿真的信号全可视和全系统调试能力,直接开展系统级验证,包括全系统启动、复杂交互与多子系统集成测
工厂模式与状态机模式的结合,为RTL设计带来了软件工程的严谨性。职责分离:每个模块只做一件事抽象封装:隐藏实现细节,暴露清晰接口可配置架构:通过参数和generate实现灵活扩展我们可以构建出真正可复用、可维护的RTL IP。2026年,随着AI驱动的EDA工具兴起,设计模式的价值将进一步放大。当ChatGPT类工具可以自动生成RTL时,清晰的架构和规范化的模式将成为人机协作的桥梁。毕竟,模糊的意
大家好,我是ZLinear的硬件工程师。在前面几期的博文中,我们把DABL7606的ADC高速采集、DI边沿触发、多级存储、上位机校准以及DDS-DAC闭环测控翻了个底朝天。后台有做运动控制和工业物联网的读者提了一个非常“跨界”的问题:“张工,你们的卡模拟量做得确实细,但在工业现场,除了模拟量,我们还频繁需要控制步进电机和电磁阀。看手册上写着支持PWM脉冲加减速控制,还能直接跑百兆以太网。我不明白
本实验基于 FPGA 纯硬件逻辑实现无操作系统的简易音乐播放器,通过 SPI 接口读取 SD 卡数据,以裸扇区搜索方式定位 WAV 音频文件,最终驱动 WM8731 音频编解码芯片完成实时播放。方案具备纯硬件实现、低资源消耗、高实时响应的核心特点。
验证覆盖率到92%了,但流片回来还是出问题”——这是许多验证工程师的痛。问题的根源往往不是测试用例不够多,而是验证架构本身缺乏系统性和可复用性。本文将以一个工业级AXI Stream数据通路为例,手把手带你构建一套完整的UVM验证平台。你将学到:如何设计符合UVM规约的Agent架构Sequence与Sequencer的解耦策略Scoreboard的自检机制实现覆盖率收集的最佳实践前置要求:具备S
bist_clk实质是Memory clk中的一路clock,即bist_clk是选的memory clk中的一个,所以这个mux是插在memory clk上面的,可能会影响到memory的clock delay从而影响memory性能。插入的tessent_persistent_cell_tck_mux_*_inst,可以指定其插在port上,也可以说buf或者ckcell的output pin
将AXICONNECT 的特性 修改为下图特性。
`-direction `:指定IO方向,如`-direction input`(输入端口)、`-direction output`(输出端口)或`-direction inout`(双向端口)。- `-type `:对于固定故障模型,可进一步指定`-type stuck - at - 0`(固定为0故障)或`-type stuck - at - 1`(固定为1故障)等。这有助于Tessent确定
注意位置的获取,上图左侧是原来的Makefile的文件(备份为了.tmp),右侧是修改后的Makefile文件。这两个新的自动化运行脚本,在板卡(7020)上通过串口助手可以创建脚本,用户可以自定义运行在的板卡上的脚本。,会花费很长的时间,我们能不能像app那样,直接在file文件夹内直接make的方式生成.ko文件呢?成功,必须要用原来的Makefile文件,也就是把Makefile.tmp重命
size(T)*N=2^power,也就是这个vector元素合计的total位宽为16bit,32bit,64bit,128bit,256bit,512bit;其中T表示是数据类型,可以是基本数据类型,也可以是用户自定义数据类型,比如说char ,int,或者struct类型。N表示元素的个数,表示vector这个数组中有多少个元素。2.对于data_width上面要data parallels
volatile修饰是禁止通过 Port Widening 大幅提升 HLS function性能。1.static是用于hold数据在function calls调用过程中,用于创建寄存器。memory access不要随便使用volatile修饰,不然会跑起来很慢!使用了volatile后,complier编译器不会对代码进行优化。memory_map_io和memory是有区别的。volat
fpga开发
——fpga开发
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 深开鸿 技术专区
深开鸿 技术专区




 openEuler 社区
openEuler 社区





 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 AI硬件创业社区
AI硬件创业社区

 AI编程社区
AI编程社区

 DAMO开发者矩阵
DAMO开发者矩阵







 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区






 AtomGit AI 社区
AtomGit AI 社区


 2048 AI社区
2048 AI社区