登录社区云,与社区用户共同成长
邀请您加入社区
# LLM-as-Judge:最方便,最危险LLM-as-Judge 的思路很简单:让一个"裁判 LLM"(通常是 GPT-5 或 Claude Opus)来评估另一个 LLM 的输出。textG-Eval 的 CoT 评估让打分更有依据(不是凭空给分),而且在论文中显示与人类评估的相关性比普通 LLM-as-Judge 高 5-10 个百分点。如果裁判 LLM 是 GPT-5,它会偏好 GPT-
适配版本:HarmonyOS 5.0.0 或以上阅读目标:实现笔记系统中的多语言能力,支持为每段内容绑定翻译版本、集成自动翻译接口、构建语言切换 UI 与语言识别逻辑,让内容具备多语同步与跨文化传播能力。
本文介绍了如何在星图GPU平台上自动化部署Hunyuan-MT 7B 全能翻译镜像,实现低延迟、高吞吐的系统级AI翻译能力。该镜像可直接集成至Linux内核,典型应用于实时视频会议字幕生成,显著降低端到端延迟至毫秒级,提升多语种交互体验。
在自然语言处理领域,机器翻译技术正从单一模型向更智能的架构演进。其核心原理是通过模型设计,在保持高效率的同时提升处理复杂任务的能力。这种架构的技术价值在于,它能够动态分配计算资源,让不同的子模块专注于特定类型的任务,从而在整体上实现更优的性能。在实际应用场景中,这种技术特别适合处理专业术语翻译、文化负载词转换以及长难句解析等挑战。本文探讨的Z-code混合专家模型,正是这一方向的典型代表,它通过构
本文介绍了如何在星图GPU平台上自动化部署Hunyuan-MT-7B开源大模型,实现边疆医院电子病历的民汉双语自动生成。该系统能够高效地将汉语病历翻译成多种少数民族语言,提升医疗服务效率与患者沟通质量,适用于门诊、急诊等多科室场景。
机器翻译(MT)作为自然语言处理的核心任务,长期受限于高资源语言主导、低资源语言语料匮乏、算力成本高昂等瓶颈。随着多语言AI系统发展,跨语言语义对齐、稀疏专家混合(MoE)架构、真实噪声数据建模等关键技术逐渐成熟,推动翻译能力从‘词汇映射’迈向‘语义理解’。NLLB-200正是这一范式演进的关键代表——它不依赖海量平行语料,而是通过动态稀疏激活、跨语言对比学习和文化适配增强,实现对200种语言(含
机器翻译是自然语言处理的核心技术之一,旨在实现不同语言间的自动转换。其基本原理通常基于序列到序列模型,通过编码源语言序列并解码生成目标语言序列。在实时交互场景中,流式翻译技术应运而生,旨在平衡翻译质量、延迟与输出稳定性,以提升用户体验。本文聚焦于实时语音翻译中的稳定性挑战,深入探讨了两种关键的推理时优化技术:掩码与偏置。掩码策略通过主动延迟输出不确定的句末部分来减少修订,而偏置技术则通过赋予已输出
本文从开发者视角深度拆解文声图(深圳)科技有限公司的多模态AI翻译API平台。核心发现:① 一套API覆盖4类能力(翻译/语音/OCR/大模型),避免多供应商集成复杂度;② 三种接入模式(API调用/SDK集成/私有化部署)支持从PoC验证到生产环境平滑升级;③ 关键性能指标:翻译准确率95%+、OCR印刷体识别率99%+、支持521+语种翻译、200+语种语音识别;④ 信创全栈适配(鲲鹏/飞腾+
机器翻译的核心目标是实现跨语言信息的准确传递,其原理在于通过算法模型学习源语言与目标语言之间的映射关系。随着大语言模型(LLM)的应用,翻译的流畅度和语境适应性显著提升,但其强大的生成能力也带来了新的技术挑战——过度生成,即模型在翻译中添加原文不存在的信息。这一现象直接关系到翻译的忠实度,在商业实践中可能引发合规与信任风险。因此,针对过度生成的检测成为确保技术价值的关键环节。通过结合语义相似度分析
拿了一个模块来进行深度排错,确实是AI编程的一个很高水平了,可是仍在传统方式中打转转,顶级AI,也只是如此。这是豆包学习九章编程法后,对这个顶级AI进行物理规则与数理规则排错。
2. **已连接好翻译数据库**(插件支持接入百度、谷歌、DeepL、火山、DeepSeek等在线翻译引擎,也可使用本地术语库)。**源语言** 选择图纸原文的语言(例如中文、英文、日文、韩文、俄文、越南文、泰文、法文等,支持数十种语言互译) |插件将**自动批量处理**文件夹内的所有图档,整个过程无需人工干预。**选中存放待翻译DWG图档的文件夹**,点击确认。1. **打开图纸查看**:逐张打
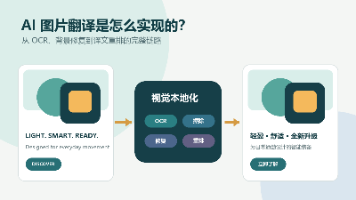
AI图片翻译是一项结合计算机视觉、机器翻译和图形排版的复杂任务,其流程包括文字检测、OCR识别、语义翻译、原文擦除、背景修复和译文重排六个关键步骤。与普通OCR不同,图片翻译需要保留文字的位置、字体、颜色等视觉信息,并确保译文与原图风格一致。系统需智能处理多语言、艺术字体、复杂背景等挑战,同时支持批量处理和在线编辑功能。这种技术能有效解决跨境电商中的多语言素材制作问题,将图片翻译从单一文本转换升级
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,快速搭建一个支持55种语言的智能翻译助手。该平台简化了部署流程,用户可轻松利用该镜像的核心功能,如直接上传包含外文文字的图片进行精准的视觉内容翻译,极大提升了处理多语言文档和资料的效率。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,实现本地化、隐私安全的图文翻译功能。该模型支持55种语言对,可直接解析图片中的中文等文本并输出专业级译文,典型应用于产品说明书、技术文档及多语种电商资料的即时翻译。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-12b-it镜像,实现本地化、离线运行的多语言图文翻译功能。用户可直接上传技术图纸或说明书截图,模型即刻识别并精准翻译55种语言,广泛应用于工业文档本地化、跨境技术协作等场景。
是智谱 AI 和KEG 实验室联合发布的对话预训练模型。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-12b-it镜像,优化长文本翻译任务。该方案结合LSTM序列建模技术,有效解决翻译中的上下文丢失与术语不一致问题,适用于技术文档、文学作品等长文本的高质量翻译场景,显著提升翻译准确性与一致性。
本文介绍了如何在星图GPU平台上一键自动化部署【vllm】glm-4-9b-chat-1m镜像,构建高效的多语言机器翻译系统。该模型支持26种语言互译,并具备1M长上下文处理能力,特别适用于技术文档、学术论文等长文本的精准翻译,显著提升跨语言信息处理效率。
本文介绍了如何在星图GPU平台上自动化部署HY-MT1.5-1.8B镜像,实现高精度民汉翻译功能。该镜像专为藏、维、蒙等少数民族语言优化,支持SRT字幕保形翻译与术语一致性控制,可直接应用于政务双语公示、农牧技术文档本地化等实际场景,兼顾离线部署与实时响应需求。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,实现轻量级多语言翻译。该方案支持55种语言互译和图文翻译功能,可快速处理技术文档、网页内容等文本翻译任务,无需昂贵硬件即可获得高质量的翻译结果。
本文介绍了如何在星图GPU平台自动化部署Tencent-Hunyuan/HY-MT1.5-1.8B翻译模型(二次开发构建by113小贝),实现高效机器翻译。该模型适用于企业级文档翻译、多语言内容本地化等场景,在保证翻译质量的同时显著提升处理效率与成本效益。
本文介绍了如何在星图GPU平台上自动化部署【vllm】glm-4-9b-chat-1m镜像,构建支持26国语言的工业级翻译系统。该镜像依托100万token上下文能力,可高效处理跨国合同审核、多语种商品页生成等典型场景,显著提升本地化与知识迁移效率。
本文介绍了如何在星图GPU平台上一键自动化部署【ollama】translategemma-12b-it镜像,快速构建高效翻译工作流。该镜像基于Gemma 3架构,支持55种语言互译,特别适用于技术文档、学术论文等专业内容的精准翻译,显著提升跨语言信息处理效率。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-12b-it镜像,构建本地化图文翻译助手。该模型支持端到端图片文字识别与多语言精准翻译,典型应用于技术文档解读、产品说明书翻译及海外网站内容理解等场景,全程离线运行,保障隐私与效率。
本文介绍了如何在星图GPU平台上一键自动化部署【ollama】translategemma-12b-it镜像,快速搭建本地化翻译助手。该方案支持55种语言的文本互译,并能直接识别与翻译图片中的外文,例如将外文菜单或产品说明书的照片快速转换为可理解的语言,兼顾高效与隐私安全。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-12b-it镜像,实现高效的多语言翻译任务。该平台简化了部署流程,用户可快速搭建翻译环境,适用于技术文档、商务沟通等场景的精准翻译,显著提升跨语言信息处理效率。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,实现嵌入式设备的轻量化翻译方案。该方案通过模型量化与优化技术,使得大型翻译模型能够在Jetson等边缘设备上高效运行,典型应用于离线实时翻译场景,为野外作业和隐私敏感环境提供可靠的本地化翻译服务。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-12b-it镜像,构建智能术语库系统以提升专业翻译质量。该方案通过API集成术语表,确保技术文档、法律合同等专业领域翻译的术语一致性,有效解决多文档协作中的术语统一难题。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-4b-it镜像,实现高效的多语言翻译模型测试。该镜像支持55种语言互译,通过本地BLEU/CHRF指标评估,可应用于技术文档、商务内容等专业翻译场景,为翻译质量提供量化保障。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-27b-it镜像,实现高效中英图文翻译。该镜像基于Gemma 3架构,不仅能处理文本翻译,还能直接识别并翻译图片中的文字,特别适用于技术文档、扫描件和多语言界面的翻译场景,显著提升跨语言内容处理效率。
本文介绍了如何在星图GPU平台上一键自动化部署Hunyuan-MT 7B全能翻译镜像,实现高效多语言翻译。该镜像专为翻译任务优化,适用于技术文档、商务邮件等专业场景的精准快速翻译,显著提升企业级翻译效率与质量。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-27b-it镜像,实现高效的图文翻译与后处理工作流。该镜像专为OCR后处理及翻译后编辑(PE)场景设计,能自动识别图片中的文字并进行多语言翻译,显著提升技术文档、商务材料等内容的翻译效率和质量。
本文介绍了如何在星图GPU平台自动化部署【ollama】translategemma-27b-it镜像,实现跨语言翻译中的文化适配。该方案通过禁忌语过滤、文化比喻转换等策略,有效避免翻译中的文化冲突,提升跨国商务沟通的准确性与得体性。
本文介绍了如何在星图GPU平台上一键自动化部署墨语灵犀(Moyu Lingxi)镜像,该镜像基于腾讯混元(Hunyuan-MT)模型深度优化,专精于文学翻译任务。它能将外文诗歌、散文等文学作品高质量地转化为中文,在保留原文意境与韵律的同时,显著提升翻译效率与美学价值。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-12b-it镜像,构建本地化、隐私安全的桌面翻译工具。该镜像专为多语言翻译优化,支持55种语言,适用于技术文档翻译、跨语言开发协作等典型场景,实现离线、低延迟、高准确率的实时文本翻译。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,构建高效的论文摘要自动翻译系统。该系统能够快速准确地将中文等学术论文摘要翻译成英文,显著提升学术成果的国际传播效率,特别适用于研究机构和出版社的批量翻译需求。
本文介绍了如何在星图GPU平台上自动化部署Qwen3-32B-Chat私有部署镜像(RTX4090D 24G显存CUDA12.4优化版),实现高效的中英双语互译与专业术语一致性保障。该镜像特别适用于技术文档翻译,能自动识别领域、保持术语一致,并处理复杂上下文,为科研、法律等专业场景提供高质量的翻译解决方案。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,实现低延迟、高稳定性的多语言AI翻译服务。通过集成PID动态资源调控算法,显著优化响应时间波动,适用于实时文档翻译、跨境业务沟通等对延迟敏感的典型场景。
本文介绍了如何在星图GPU平台上自动化部署Qwen2.5-0.5B-Instruct镜像,以优化多语言翻译任务。该平台简化了部署流程,用户可快速利用该模型进行技术文档、文学内容等多场景的高精度翻译,显著提升跨语言沟通效率。
本文介绍了如何在星图GPU平台上自动化部署【ollama】translategemma-27b-it镜像,快速构建本地化AI翻译服务。基于RTX 4060等消费级显卡,用户可直接上传图片或输入文本,实现高准确度、强术语一致性的中英等55种语言互译,典型应用于技术文档解读、商品包装识别与API错误提示翻译。
本文介绍了如何在星图GPU平台上自动化部署Tencent-Hunyuan/HY-MT1.5-1.8B翻译模型(二次开发构建by113小贝),实现高效的多语言互译功能。该模型支持38种语言互译,包括主流语言和方言变体,适用于跨境电商、技术文档本地化等场景,翻译质量接近GPT-4水平,同时具备更快的推理速度和更低的部署成本。
本文介绍了如何在星图GPU平台上自动化部署Qwen3.5-2B轻量化多模态基础模型,实现高效的中文长文本摘要与英文翻译功能。该模型特别适用于企业文档处理、内容本地化等场景,能在低资源环境下保持出色性能,帮助用户快速生成精准摘要和自然流畅的翻译结果。
机器翻译
——机器翻译
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DeepSeek技术社区
DeepSeek技术社区

 HarmonyOS开发者社区
HarmonyOS开发者社区



 脑启社区
脑启社区

 AI Agent技术社区
AI Agent技术社区

 鲲鹏昇腾开发者社区
鲲鹏昇腾开发者社区

 AI编程社区
AI编程社区


 快递鸟社区
快递鸟社区














 龙虾开发者社区
龙虾开发者社区





 MCP技术社区
MCP技术社区





 CSDN-OPC开发者社区
CSDN-OPC开发者社区





