登录社区云,与社区用户共同成长
邀请您加入社区
2026年7月,全球Agent赛道融资达18亿美元,但Gartner警告超40%项目将失败。WAIC展会显示消费端"对话替代搜索"趋势,但演示场景与真实业务存在巨大落差。生产环境要求Agent具备99.9%稳定性,长尾风险可能摧毁信任。成功案例如智元机器人万台量产线、蚂蚁灵波医疗配送机器人,均以量化价值和兜底机制取胜。资本转向关注交付能力,创业者需从工具提供者升级为结果交付者。行业正从技术展示期进
触觉感知被视为解锁通用机器人操作能力的关键拼图。在2026年RSS研讨会上,专家指出触觉长期被忽视的三大原因:硬件缺乏标准化、跨学科门槛高、实证价值不足。当前研究聚焦可规模化触觉方案,如磁触觉手套和低成本压阻皮肤,并突破系统集成瓶颈,探索多模态融合算法。触觉通过填补视觉盲区、提升操作鲁棒性,可显著提高工业吞吐效率。随着可穿戴设备和大规模仿真的发展,触觉技术正从"是否可行"迈向&
1 简介基于粒子群算法的移动机器人路径规划,通过建立目标函数,变换坐标等对环境建模,再引入粒子群优化算法,得到全局最优路径.MATLAB仿真结果显示,此方法可有效地解决空间作业机器人路径规划及避障问题.与传统遗传算法比,该法建模容易,计算快捷,可以在不同的障碍物环境下得到不同的优化轨迹。路径规划是移动机器人导航中最重要的任务之一 。路径规划技术是移动机器 人研究领域中的一个重要分支 。所谓机器人的
同类混合架构目前极少,比亚迪这套方案填补“像素细节+潜态鲁棒”的中间空白,相比多激光融合方案硬件成本更低,仅依靠前视单相机就能实现均衡表现,对量产车型成本控制更友好。同时,论文搭建的噪声鲁棒评测数据集,给后续世界模型研发提供统一量化标准,解决行业此前只看仿真高分忽略真实恶劣路况的评测盲区。这个VAE相当于“图像翻译器”,既能还原高清路面画面,又能产出干净带语义信息的隐向量,是混合建模的基础载体。两
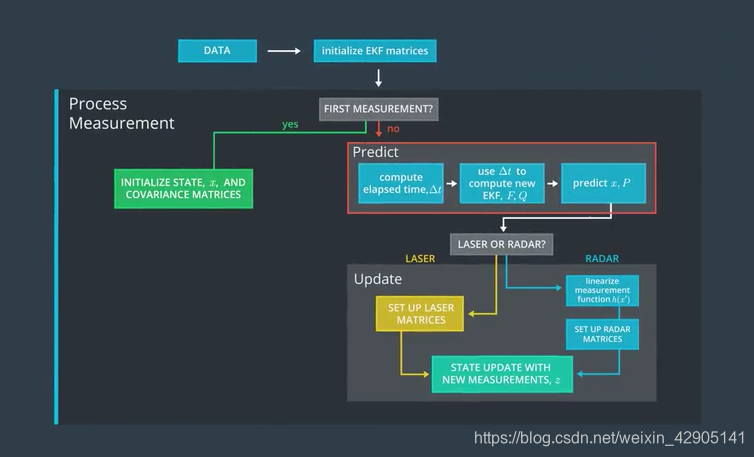
卡尔曼滤波算法图概述想象一下,你在一辆装有外部传感器的汽车里。汽车传感器可以检测到四处移动的物体:例如,传感器可能检测到自行车。卡尔曼滤波器算法将执行以下步骤:第一次测量 - 过滤器将接收自行车相对于汽车位置的初始测量值。这些测量将来自雷达或激光雷达传感器。初始化状态和协方差矩阵 - 过滤器将根据第一次测量初始化自行车的位置。然后汽车将在一段时间后接收另一个传感器测量值Δt\Delt...
车路协同到底要协同什么?一、对智能车路协同系统的认知(一)“车路协同”不是新名词(二)智能车路协同系统需要解决的问题(三)到底要协同什么?二、高速公路的典型应用场景三、亟待的解决问题四、理性看待技术演进和产业发展(一)高速公路智能车路协同技术的发展(二)产业发展车路协同到底要协同什么?网联共享车路协同智能交通作者简介:王少飞,招商局重庆交通科研设计院有限公司智慧城市与数字交通工程院副院长一、对智能
在园区实测中,沿长度为620米的蜿蜒道路以18 km/h行驶,最大横向误差为0.19 m,平均横向误差0.056 m,纵向速度跟踪均方根误差为0.33 km/h,避障绕行时与原全局路径的最大横向偏移为2.27 m,控制器整体计算耗时未超过2.3毫秒。仿真在校园三种典型场景(直道、直角弯、连续S弯)中以25 km/h和35 km/h两种期望速度进行测试,横向误差均方根分别为0.032 m和0.045
本文深入解析了MMDetection3D框架中从体素化处理到3D检测框生成的核心模块协同工作流。详细介绍了体素编码器、特征提取网络、多尺度主干设计以及检测头优化等关键技术,并分享了实际项目中的配置技巧和性能优化经验,帮助开发者高效实现精准的3D目标检测。
该模型在业内率先实现 VLA、世界模型、潜空间推理等多个技术路线的统一,在具备 XLA 模型强悍推理能力的基础上,大幅提升了推理的速度和精度,是行业内具备开创性的方案,在精度上超越显式 CoT、在速度上对齐“仅答案”预测的潜空间 CoT 方案。同时,Xiaomi OneVL 能为模型决策提供语言和视觉双维度的可解释性——既能用文字说明“为什么这样开”,也能用预测画面展示“接下来会发生什么”,将 X
本文提出了一种新型自动驾驶框架PLA(感知-语言-行动),通过整合多模态感知、语言增强认知和分层决策,解决了传统模块化系统的误差累积和端到端模型的短视决策问题。该框架采用双分支视觉编码器处理几何与语义信息,引入混合思维推理机制动态选择决策路径,并利用语言模型提供常识知识。实验表明,PLA在轨迹误差、碰撞率等指标上表现优异,尤其在极端场景下展现出更强的适应性和解释性。这一突破标志着自动驾驶向类人认知
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)特别声明:本数据集不对训练的模型或者权重文件精度作任何保证。sign_back 占有图片数 = 1384。标注类别名称:["sign_back"]图片数量(jpg文件个数):1384。标注数量(xml文件个数):1384。标注数量(txt文件个数
OpenScene 数据集OpenScene 数据集。
本文深入解析了DIAL-Filters技术在自动驾驶夜间视觉增强中的应用,通过PyTorch实现为自动驾驶系统装上‘夜视仪’。该技术采用双阶段自适应处理架构,仅增加4ms延迟和280K参数,显著提升夜间语义分割精度。文章详细介绍了IAPM和LGF模块的实现原理,并提供了工程落地优化技巧和实际部署效果验证。
当您排除了 3D、仿真、主动推理、视觉生成和 VLM/VLA 后,世界模型赛道褪去了所有“视觉奇观”和“语言红利”的浮华,只剩下“纯 JEPA(抽象表征)”这一条最硬核、最反共识的路线。竞争格局:这条路线目前在全球范围内主要由引领理论,由具脑磐石在中国进行工程化突围。核心信仰智能的本质是理解事物背后的抽象概念和物理因果,而不是死记硬背像素或文本细节。业界普遍认为,这是突破当前具身智能“数据荒”与“
空间智能作为数字经济下一代核心基础设施,市场迎来万亿级产业风口,产业逻辑完成根本性跃迁:从过去追求三维可视化大屏展示,升级为理解物理空间、量化空间关系、推演行为态势、实现虚实双向闭环调度,视频孪生赛道头部企业迎来一场关乎未来赛道话语权的资格大考。原生空间智能底座范式:以视频像素作为计算源头,原生完成像素‑三维坐标实时解算,内置统一四维时空基准,空间感知、时空融合、态势推演、闭环控制深度耦合到底座内
英伟达推动PhysicalAI进入产业落地阶段,构建"三台计算机"系统支撑物理智能发展。通过车载推理、云端训练和仿真验证的闭环体系,加速自动驾驶和人形机器人两大领域的商业化进程。英伟达同时布局生态标准,推出Cosmos模型并组建产业联盟,试图掌控PhysicalAI操作系统话语权。中国企业则采取差异化策略,在细分场景寻求突破,结合政策支持形成独特竞争力。随着"仿真+世
镜像视界立足于像素升维原创理论,依托SpaceOS™全域空间智能底座、全栈自研引擎矩阵以及Cognize‑Agent空间AI原生智能体,把视频孪生升级为具身智能的空间计算基座,打通全域空间感知‑空间自主决策‑物理设备控制‑现场执行反馈‑数字底座动态更新完整闭环,探索视频孪生与具身智能深度融合落地路径。仅做单向可视化展示的方案市场持续收缩;→ Cognize‑Agent空间AI原生智能体(具身智能中
千里科技与阶跃星辰的此次联手,将显著提升智驾系统全链路流程中的“含模量”,通过打造真正理解驾驶本质的基座模型,千里科技有望在迈向L4级高阶自动驾驶的竞争中,获得关键性的技术代差优势。
投递链接: https://gigaai0118.jobs.feishu.cn/s/qon0iZSyPb8。极佳科技社招内推码: R91RTWV。欢迎找我互相交流学习~😘😘😘。
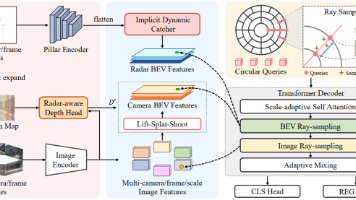
本文围绕3D目标检测任务,提出了——一种基于查询的雷达-相机融合Transformer框架,突破了传统BEV融合的性能瓶颈。图1 RaCFormer 的动机。(a) 以往的方法通常通过拼接或交叉注意力的方式将来自图像视角转换和雷达点云编码的 BEV 特征进行融合。(b) 相比之下,RaCFormer 采用基于查询的融合框架,同时采样雷达增强的图像视角特征、摄像机变换后的 BEV 特征以及雷达编码的
本文探讨了如何利用大陆ARS408毫米波雷达的0x200配置帧优化目标输出,有效解决自动驾驶感知中的车道旁车辆干扰问题。通过硬件级过滤和动态参数调整,显著降低误检率并提升系统响应速度,适用于复杂城市道路场景。
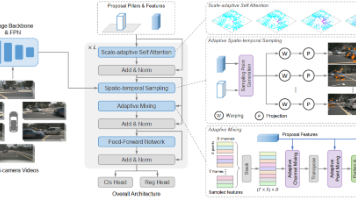
查询最初被初始化为 BEV 空间中的稀疏柱体集合。区别于传统方法使用3D参考点作为query初始化,SparseBEV采用BEV空间的柱体作为query初始形式:每个query包含位置(x,y,z)、尺寸(w,l,h)、旋转θ、速度[vx,vy]及对应的D维特征,z初始化为0、h初始化为4m,引入了更合理的空间先验,相比参考点可带来0.5NDS的性能提升。要缩小稀疏方法与稠密方法的性能差距,需要同
本文综述了自动驾驶与联网车辆(CAVs)在感知、规划、控制及协同定位等方面的研究进展,涵盖深度学习、强化学习、多传感器融合、车联网通信等核心技术,分析了当前面临的挑战,如NLOS干扰、数据不平衡、实时性要求等,并总结了多个前沿解决方案,包括基于深度神经网络的控制方法、语义建图、地图压缩与驾驶员干预检测等。
针对稀疏点云,设计迭代中心回归模块,将候选中心坐标作为偏移量输入到下一级回归,共迭代三次,每次感受野扩大。对于Cyclist类别,由于点云更稀疏,采用额外的点云补全分支,将检测AP从72.3%提升到79.8%。然后设计点云到像素聚集模块:每个像素聚合其邻域内的点云特征,得到稠密特征图。在SemanticKITTI点云分割任务上,mIoU达到68.3%,超越之前最好方法2.1%。对于速度估计,设计降
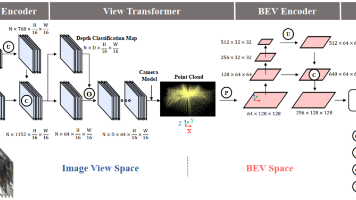
自动驾驶的核心感知任务(3D目标检测、BEV语义分割)长期采用不同范式:多相机3D检测主流为图像视角方法(如FCOS3D、PGD),而BEV语义分割由BEV视角方法主导,无法复用计算资源,且图像视角方法对目标位置、朝向、速度的感知精度有限。BEV空间与自动驾驶下游任务(路径规划、决策)的定义空间一致,更易精准感知目标的平移、尺度、朝向、运动速度等几何属性,且具备支撑多任务统一建模的潜力。2D检测的
杂草的精准识别与定位是实现智能农业精准施药的关键技术之一。本研究针对农田中常见的杂草“ridderzuring”(酸模),构建了一个基于YOLO26的目标检测系统。数据集共包含2486张标注图像,划分为训练集(1661张)、验证集(580张)和测试集(245张),所有图像均标注了单一类别“0 ridderzuring”。实验结果表明,模型在验证集上的平均精度均值(mAP@0.5)达到78.1%,精
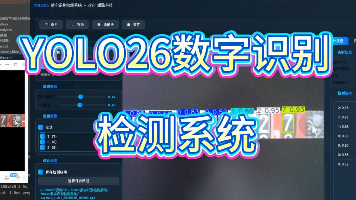
本报告基于YOLO26目标检测框架,构建了数字的识别系统。系统共包含10个类别,训练集、验证集和测试集分别为966张、99张和50张图像。模型在验证集上取得了mAP50为0.993、mAP50-95为0.917的优异性能,精度和召回率分别达到0.993和0.982。混淆矩阵分析显示,模型对各类别数字的识别准确率接近100%,无明显类别混淆问题。训练过程中的损失函数持续下降,mAP指标稳定上升,表明
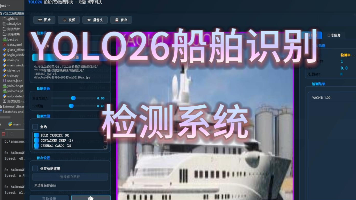
本论文旨在研究和实现基于YOLO26(You Only Look Once)深度学习框架的船舶识别检测系统。针对海上交通监控、港口管理和海洋安防等应用场景,构建了一个包含10类船舶的数据集,分别为:散货船、集装箱船、杂货船、油品船、客船、油轮、拖网渔船、拖船、车辆运输船和游艇。数据集共包含训练集3498张图像、验证集1000张图像和测试集500张图像。
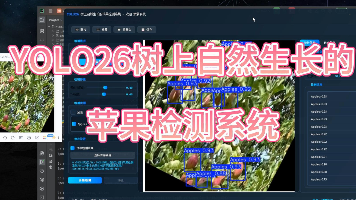
本文针对自然环境下树上苹果的自动检测问题,基于YOLO26目标检测算法构建了一套高效的苹果检测系统。研究使用自建的苹果数据集,包含训练集1355张、验证集77张和测试集39张,共标注了苹果类别。实验结果表明,模型在验证集上取得了0.852的精确率、0.835的召回率和0.889的mAP50,最大F1分数达到0.84。通过混淆矩阵分析,模型对苹果的正确检测率为82%,背景误检率为18%。该系统能够有
MV2DFusion是一个多模态3D目标检测框架,通过融合图像和点云数据进行3D检测。其核心架构包含三个并行分支:图像分支使用Faster R-CNN提取2D特征并生成深度分布Query;点云分支基于FSDV2生成精确3D Query;融合分支通过6层Transformer Decoder整合双模态信息。训练流程包括2D检测训练、RoIAlign特征提取、Query生成和Transformer解码
英语的优势仅体现在入门拼读便捷,但其表音本质带来词汇泛滥、逻辑断裂、传承薄弱、效率低下等固有缺陷。汉语凭借构词有逻辑、学习低成本、表达高密度、传承超稳定、适配新时代、承载深文化的六大核心优势,形成了一套更科学、更高效、更具生命力的语言体系,既是中华文明绵延不绝的核心密码,也是适配未来数字时代的优质语言。
融资、扩张、挖人、堆算力、堆数据,太多的公司在做智驾(彼时还可以称之为“自动驾驶”),也有很多的公司都在讲 Robotaxi,讲 L4 落地,讲“未来三年会彻底改变出行”。做 CV 的、做 SLAM 的、做机器人方向的,甚至还有不少做搜广推、大数据的人转过来。模型、训练框架、部署优化、数据闭环等等,太多的工作和新的东西,让我会明显感觉自己在变强。虽然我天天吐槽,虽然我也焦虑,虽然我也会研究大模型、
本文详细评测了PU-GCN、PU-Net、MPU和PU-GAN四大点云上采样模型在PU1K数据集上的性能表现,包括环境配置、训练测试流程和可视化分析。通过对比Chamfer Distance和Hausdorff Distance等核心指标,为工业级应用提供模型选型建议,特别适合自动驾驶和三维重建领域的技术人员复现和参考。
本文提供了一份详细的Python和TensorFlow教程,指导开发者如何从Waymo Open Dataset中高效提取3D目标检测标签。教程涵盖环境配置、数据帧解析、标签提取工程实现、工业级数据处理优化以及质量验证与可视化,帮助开发者快速掌握自动驾驶研发中的关键数据处理技术。
自动驾驶
——自动驾驶
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 DAMO开发者矩阵
DAMO开发者矩阵






 深开鸿 技术专区
深开鸿 技术专区


 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区






 openEuler 社区
openEuler 社区


 AI编程社区
AI编程社区