




- @xiaoganbuaiuk
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
讯飞星辰 Agent 开发平台 (https://agent.xfyun.cn/home?ch=xc_kolN3eF),是面向普通人/IT 从业者/ AI 开发者,打造贯通学习提效-功能开发-工程化落地-企业应用,支持深度定制开发的 Agent 开发平台。「智能体广场」海量智能体可以直接使用。「插件广场」提供智能体所需的各种工具。「个人空间」提供智能体、提示词工程、模型管理等一系列功能。现在大家生
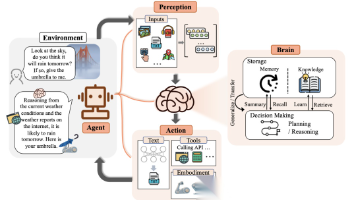
要理解智能体的运作,我们必须先理解它所处的任务环境。在人工智能领域,通常使用PEAS模型来精确描述一个任务环境,即分析其性能度量(Performance)、环境(Environment)、执行器(Actuators)和传感器(Sensors)。以上文提到的智能旅行助手为例,下表1.2展示了如何运用PEAS模型对其任务环境进行规约。表 1.2 智能旅行助手的PEAS描述在实践中,LLM智能体所处的数
GPT-5将会集大成于一体?!,OpenAI又接着在Reddit举行了。。除此之外,其他Codex团队成员也纷纷开启了爆料模式,比如:Codex最初只是一个附带项目,启动原因是他们意识到在内部工作流中未充分利用好模型;内部在使用Codex时,编程效率提升了约3倍;OpenAI正在探索灵活的定价方案,包括按需付费;o3-pro或codex-1-pro最终将在团队能力允许的情况下推出;……Okk,下面

这么做,想法是好的,思路没问题,但是企业那么搞的很少,最后大家还是用Python去开发和集成。如果把这些事展开了说,真是有太多的东西能说了,如果说太多了,还会有一堆人怼我,因为每个人的使用场景不一样,每个人对工具的认知和使用工具的能力也不一样,对于AI生成的代码,自身的可控性能力更是不一样。给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学
反思模式是AI通过自我评估和迭代改进来提高模型任务执行能力的方法。在这种模式中,模型不仅能生成初始解决方案,还会通过多次反馈和修改,不断优化其输出。其核心机制包括自我检查、结果评估、策略优化和持续迭代四个步骤。用户通过界面或API向Agent提交具体的请求或问题Agent内置的LLM接收查询,并生成一个初步响应模型对自己的输出进行批判性评估,识别其中的错误、不足或可以改进的地方LLM结合评估结果,

大语言模型(LLMs)是经过大量文本数据训练的AI系统,用于理解和生成类似人类的语言。在训练过程中,它们通过分析来自书籍、文章、网站和其他书面来源的数十亿文本示例来学习语言中的模式、关系和结构。这使它们能够理解人类语言的语法和语义。当今使用的一些流行LLM包括:这些模型是专有的,这意味着它们的内部细节(权重、参数、训练数据、训练方法)不公开。GPT,或生成式预训练Transformer,是最早和最
是一个能够帮助人类突破知识边界的智能体,能够对特性问题提出新思路新方案,不断迭代进化。
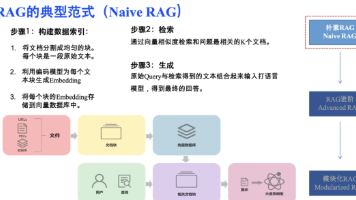
本文详细介绍了企业级RAG系统的构建要点,从文档预处理、召回和生成增强三个核心环节展开。文档预处理需统一格式、清洗内容并提取关键信息;召回阶段需优化用户问题、提取标签并进行去重排序;生成增强则需整理数据、压缩上下文并优化格式展示。各环节需根据业务场景灵活处理,才能构建高效的RAG系统。想做一个RAG项目很容易,但要想做好一个RAG系统却很难。最近手上的一个RAG聊天类项目也算接近了尾声,虽然从功能
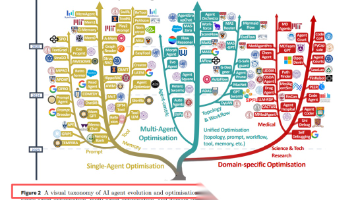
本文提出"Self-Evolving AI Agents"新范式,让AI智能体像生物一样在与环境交互中自主优化结构。系统化阐述智能体演化三大方向:单智能体(提示、记忆、工具优化)、多智能体(协作拓扑演化)和领域专用优化。提出自演化三定律(Endure-Excel-Evolve)作为硬约束,并构建统一四模块框架(系统输入-智能体系统-环境反馈-优化器)。这一终身学习范式解决了传统LLM Agent固
“到达地点X”、“完成任务Y”