- @2401_85464956
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
命令行参数是程序和外部交互的重要方式,无论是开发命令行工具还是需要动态配置的应用程序,都离不开对命令行参数的处理。本篇博客以C++语言为例,介绍如何命令使用命令行参数。本篇博客主要介绍在C++环境下,如何配置task.json和launch.json文件,如何传递命令行参数,并进行debug,希望能够对你有所帮助!

最近正在准备毕业设计的相关内容,发现其使用的是和之前的PyTorch有一定的差距,因此就主动了解了它们之间的差距。如果你用过PyTorch,一定会经历过类似的场景:手动编写训练循环、反复切换和模式、手动管理GPU设备、写一堆日志记录逻辑……这些重复的工程代码占用了大量时间,却与核心的模型研究无关。正是为了解决这些问题而诞生的。它不是替代PyTorch的新框架,而是在PyTorch之上构建的工程化规

命令行参数是程序和外部交互的重要方式,无论是开发命令行工具还是需要动态配置的应用程序,都离不开对命令行参数的处理。本篇博客以C++语言为例,介绍如何命令使用命令行参数。本篇博客主要介绍在C++环境下,如何配置task.json和launch.json文件,如何传递命令行参数,并进行debug,希望能够对你有所帮助!
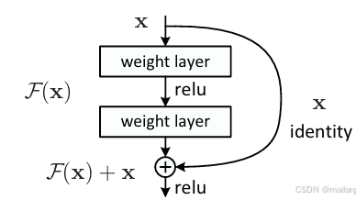
在深度学习领域,“更深的网络性能更好” 曾是研究者们的共识 —— 理论上,网络层数越多,能捕捉的特征越复杂,拟合能力也越强。但在 2015 年之前,当网络深度超过 20 层后,研究者们发现了一个致命问题:梯度消失 / 梯度爆炸导致模型无法训练,甚至出现 “深度退化” 现象(深层网络的测试误差反而比浅层网络更高)。而残差网络(Residual Network,简称 ResNet)的出现,彻底打破了这
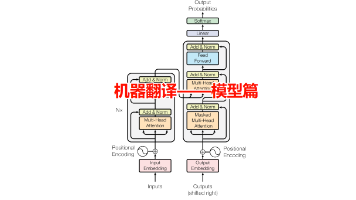
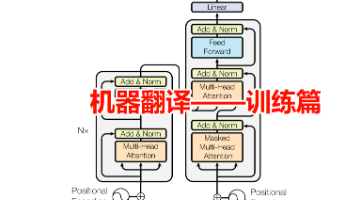
还在为机器翻译模型从理论到落地卡壳?系列博客第三弹——模型训练篇强势登场,手把手带你走完Transformer中日翻译项目的最后关键一步!前两期我们搞定了数据预处理(分词、词表构建全流程)和模型搭建(词嵌入、位置编码、编码器解码器核心结构),而这一篇,将聚焦让模型“学会翻译”的核心秘籍:如何设计损失函数,让模型精准捕捉中日语言差异?优化器参数怎么调,才能让训练更稳定、收敛更快?从数据到模型,再到训
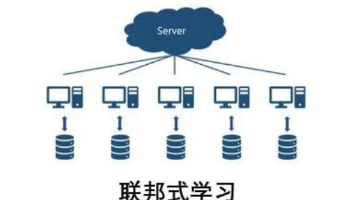
医院想联合训练 “癌症诊断模型”,但不能共享患者病历(隐私保护);银行想优化 “反欺诈系统”,却不能泄露客户交易数据(合规要求);电商想做 “个性化推荐”,但各平台数据互不互通(数据孤岛);我们想享受智能推荐、精准医疗的便利,却又害怕自己的照片、聊天记录等隐私数据被上传到陌生的服务器。联邦学习(Federated Learning)就是解决这个矛盾的 “魔法”—— 它让多个机构 / 设备在不共享原
保险产品的多样性、客户特征的复杂性以及需求差异使得保险推荐存在相当大的不确定性,如何精准识别用户、降低销售风险、提升推荐成功率,成为当前一个非常热门的研究和应用话题。通过对用户本身属性和过往保险购买记录分析客户特点,可以对广大用户进行个人信息的有效筛选,从购买保险的用户群体中提取共同的特征,进而针对这些特征规律提高投放精准性。本案例是针对移动房车险的预测,其中保险公司提供了以家庭为单位的历史数据,

书接上回(机器学习实战案例——保险产品推荐(上)),上回说到,由于任务的目的不同,单靠一个准确率去衡量一个模型的好坏是远远不够的,因此需要其他的指标去衡量模型的好坏。本案例的保险产品推荐,是一个二分类问题,因此有相当多的模型可供选择,不限于本篇博客所举例的,本篇博客主要带你了解机器学习实践的过程

本篇博客主要神经网络中最简单的网络模型,即单层感知机(Single Layer Perceptron),并基于pytorch框架实现该网络的搭建。虽然如今看来,该模型只能解决线性可分的问题,但作为神经网络的开山之作,仍值得学习。单层感知机网络结构可表示为下图所示(最近发现豆包的画图功能有进步,所以直接用豆包的图片了):z∑i1nwixibwTxbzi1∑nwixibwTxb。

本文介绍了基于Transformer的中日机器翻译模型实现,重点解析了模型结构中的关键组件。内容包括词嵌入层(TokenEmbedding)的实现,位置编码(PositionalEncoding)的正弦余弦公式应用,以及编码器(TransformerEncoder)和解码器(TransformerDecoder)的堆叠结构搭建。文章提供了完整的PyTorch实现代码,涵盖从词向量处理到最终输出的整