- @jennycisp
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
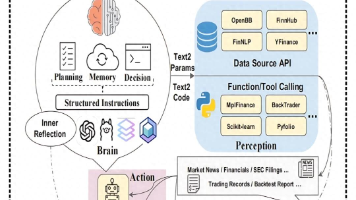
但要真正转型成功,还需要补齐 LLM(大语言模型)、Agent 架构、AI 工程化 这三大核心能力短板。转型第一步,先搞懂 AI Agent 的核心组成,不用死记硬背,理解逻辑即可,重点掌握“大模型 + Agent”的底层逻辑。
但要真正转型成功,还需要补齐 LLM(大语言模型)、Agent 架构、AI 工程化 这三大核心能力短板。转型第一步,先搞懂 AI Agent 的核心组成,不用死记硬背,理解逻辑即可,重点掌握“大模型 + Agent”的底层逻辑。
2.直接换岗失败后,个人对接的业务团队有了较大调整,scope变大了,变成了直接给LLM提供数据的团队,一下子和AI紧密起来了。但我发挥了个人主观能动性,和对接的后端说,数据采集、数据处理、数据合成、标注、训练、评测这些都弄过,其实自己吹牛的,目的想让自己在干中学,基本上那会靠着一腔热血和努力,把自己变成业务主干。你要写的不是你学过什么,而是你做成了什么。4.学Python,能写项目,模型 API
2.直接换岗失败后,个人对接的业务团队有了较大调整,scope变大了,变成了直接给LLM提供数据的团队,一下子和AI紧密起来了。但我发挥了个人主观能动性,和对接的后端说,数据采集、数据处理、数据合成、标注、训练、评测这些都弄过,其实自己吹牛的,目的想让自己在干中学,基本上那会靠着一腔热血和努力,把自己变成业务主干。你要写的不是你学过什么,而是你做成了什么。4.学Python,能写项目,模型 API
Agent的狂欢基本已经结束了,不建议继续纯做这个,起码得加点多模态和ml,dl了。具体可以看看各家公司的agent都到什么水平了,比如网易这种,别人已经纯商业赚钱了,你如果不如人家的,大概率还是很难。今天刚中了nips,也是llm agent的工作。有需要的话,我可以写一下自己对这方面的经验。现在llm agent的工作好几类,而我主要是关注游戏方面的,所以有些地方肯定是没写清楚或者有错误,还希

当前,AI大模型技术正推动各行业智能化转型。该教程通过"应用-开发-算法"三位一体的学习路径,帮助学习者系统掌握大模型核心技能。从工具使用到模型调优,七天集训聚焦真实业务场景的解决方案,完成从理论到实战的能力跨越。把握技术变革窗口期,这场高效学习将为你打开AI工程师的职业通道,赋能未来技术生涯的持续发展。
大模型产品经理是专注于规划、设计和优化基于大模型(如GPT、BERT、盘古等)的AI产品的角色。他们需要将复杂的AI技术与实际业务场景结合,推动产品落地并实现商业化价值。技术理解与需求转化:理解大模型的原理(如Transformer架构、预训练与微调机制等),将业务需求转化为技术方案;产品设计与迭代:设计用户体验,优化模型效果,协调技术团队实现产品功能;数据与场景洞察:分析用户需求,挖掘适合大模型
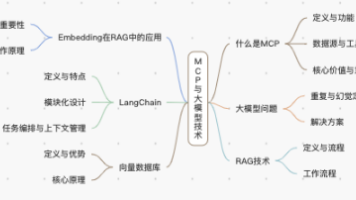
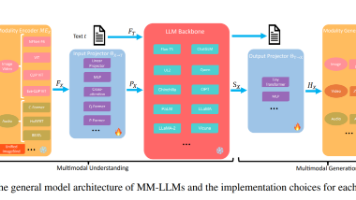
在腾讯 2024 数字科技前沿应用趋势中,强调了“通用人工智能渐行渐近,大模型走向多模态,AI智能体(Agent)有望成为下一代平台当下多模态大模型不仅仅是学界新宠,也是未来行业发展进步的一大方向,站在这篇综述的基础之上,期待我们可以更快更好的理解未来多模态大模型的发展,赶上这波通用人工智能的新浪潮!
Prompt工程法则使用"角色-任务-约束-示例"四段式结构为常用操作建立prompt模板库(已开源52个精选prompt)质量控制机制设置AI代码的"三重验证"流程:静态分析检查单元测试覆盖人工重点复核性能平衡点找到响应质量与速度的最佳平衡(我们的选择:800-1200ms响应时间)安全防护实现AI生成代码的沙箱执行环境敏感信息自动过滤机制团队协作模式建立"AI驾驶员+人类领航员"的结对编程新范

这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。**因篇幅有限,