




- @Louise_Trender
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】基于BP神经网络的手MNIST写数字识别。
再运行就可使用了,在我的运行场景中是不会报错的,不知道其它场景是否可以这么操作(我只用了普通有监督Lora微调、flash-attn和unsloth加速、Qlora微调、RLHF,以及导出)的原因顾名思义是unsloth_zoo引用的vllm不存在相关模块,这一般都是因为版本不匹配,在。看到llamafactory作者给出的解决方案也是升级vllm版本。,却没有匹配的vllm版本,
数据集下载: https://pan.baidu.com/s/1uFZlvegZ4OUvBft0auHqKw提取码:0829。
嵌入向量=嵌入矩阵∗onehot向量。
cmd下载速度慢不是电脑问题,而是下载的网站有网速限制,如pip,虽然没被墙,但由于是外网,网速极差,经常是几KB一秒,所以我们可以采用镜像服务器,即在命令后加上-i https://pypi.tuna.tsinghua.edu.cn/simple格式如下pip install something -i https://pypi.tuna.tsinghua.edu.cn/simple这...
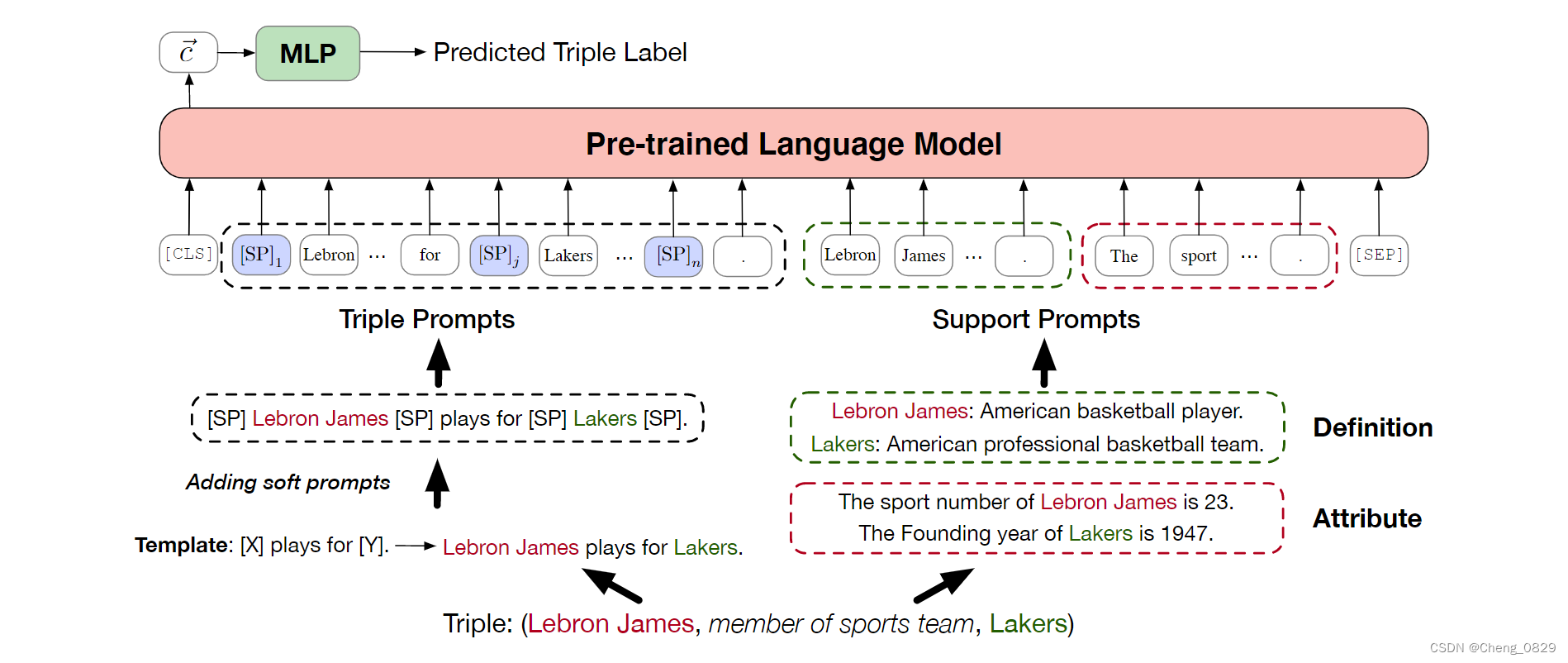
开放世界假设(OWA)我们提出了一种新的基于PLM的KGC模型,名为PKGC。基本思想是**将每个三元组及其支持信息转换为自然提示句,进一步输入PLM进行分类。
=======================================================
1.删除安装插件C:/User/XXX/.vscode2.删除用户信息和缓存信息C:/User/XXX/AppData/Roaming/CodeC:/User/XXX/AppData/Roaming/Visual Studio Code
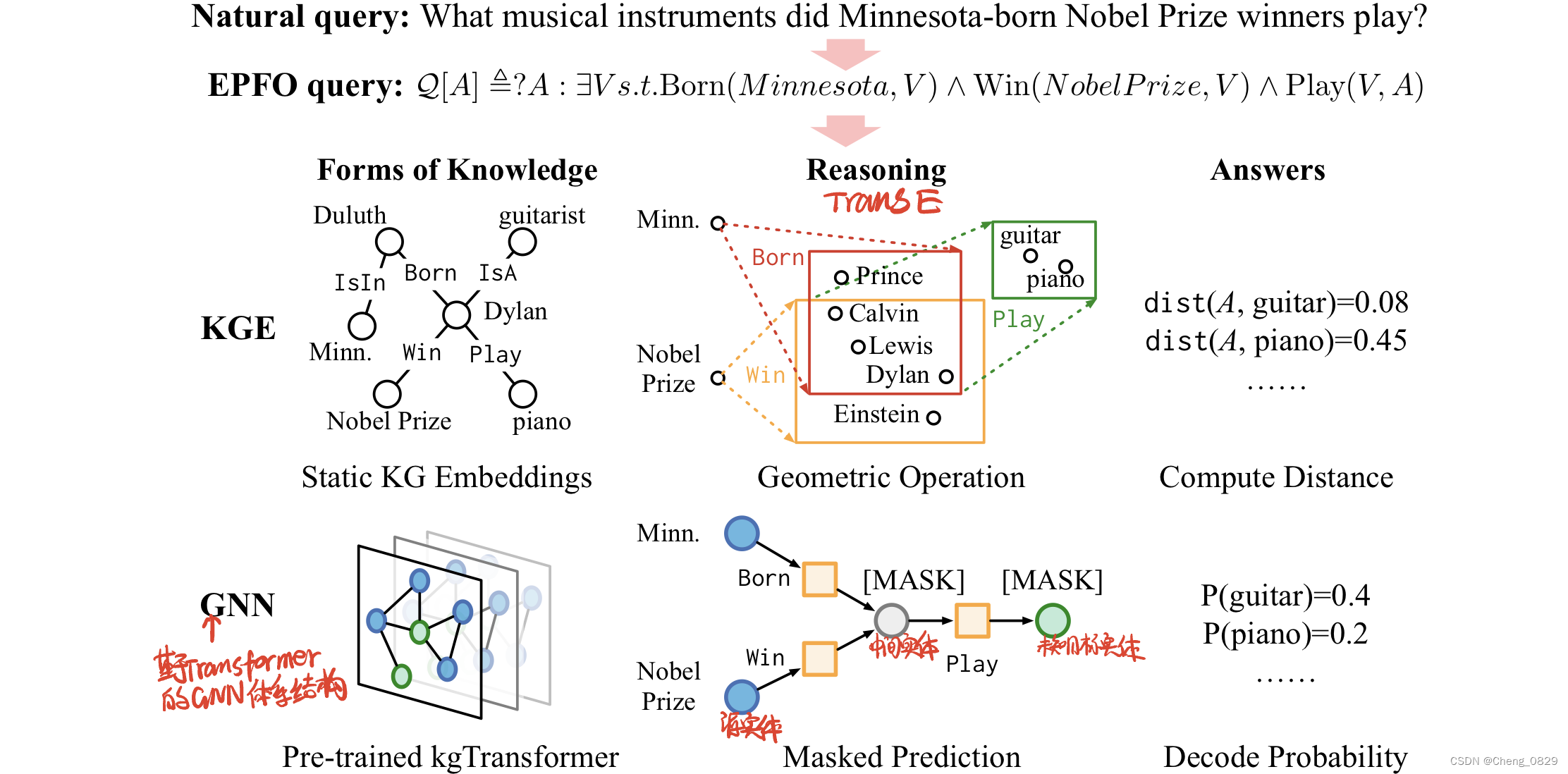
知识图(KG)嵌入是不完备KG推理的主流方法。然而,受其固有的浅层和静态结构的限制,它们很难应对日益增长的复杂逻辑查询的,这些复杂逻辑查询包括逻辑运算符、推定边缘、多个源实体和未知的中间实体。在这项工作中,我们提出了具有掩蔽预训练和微调策略的KGTransformer(KgTransformer)。我们设计了一种KG三元组变换方法,使Transformer能够处理KG,并通过混合专家(MoE)稀疏
如何生成具有表达性的分子表示是人工智能驱动药物研发的一个根本挑战。图神经网络(GNN)已经成为一种强大的分子数据建模技术。然而,以往的监督方法通常存在有标签数据稀缺和泛化能力差的问题。在此,我们提出了一种新的基于分子预训练图的深度学习框架MPG,该框架从大规模的未标记分子中学习分子表示。在MPG中,我们提出了一种用于分子图建模的强大GNN模型–MolGNet,并设计了一种有效的自监督策略在节点和图
