登录社区云,与社区用户共同成长
邀请您加入社区
昇腾910B拉起模型MinerU2.5-Pro-2605-1.2B
http://www.wgstart.com/help/docs8.html如上,点击下载工具,安装包里有使用说明
文章目录CPU上下文切换什么是CPU上下文进程上下文切换进程上下文切换线程上下文切换中断上下文切换查看系统上下文切换情况:vmstat和pidstat高负载模拟与排查:sysbench和pidstat参考文献写在前面:由于之前在开发分布式系统中由于云服务器性能原因,导致系统总是断连等错误。但是之前一般只是简单gdb调试一下,定位错误异常艰难,所以决定开设此专栏,系统的记录我学习Linux 性能优化
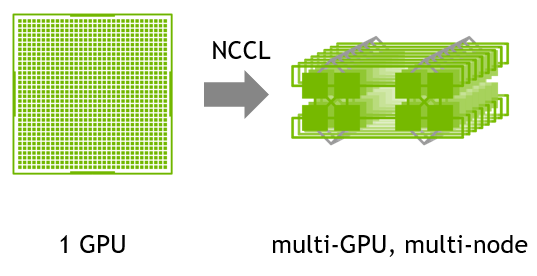
最近在做目标跟踪的训练时,需要对backbone做一个在imagenet上的预训练模型。众所周知,140GB+的imagenet数据集上训练网络很是考验算力。刚开始在单机双卡(2080Ti)上试了一下,1个epoch需要6个小时,跑完100 epoch大约100*6/24=25天。瞬间放弃单机多卡,将目光放在了多机多卡训练,特撰文记录这段时间的工作,方便以后查询。一、准备工作因为之前配置单机的深度
一、Zookeeper三节点搭建1.1设备规划HOSTNAMEIP操作系统masterndoe192.168.122.128Manjaro 20.1slavenode1192.168.122.130CentOS 7.4slavenode2192.168.122.131CentOS 7.41.2环境准备1.2.1新增hadoop用户已有没有的话使用该命令groupadd hadoopuseradd
下载apache-hive-2.3.7-bin.tar.gz 放在目录/myfiles/hive 解压tar -zxvf apache-hive-2.3.7-bin.tar.gzhttp://mirror.bit.edu.cn/apache/hive/修改环境变量vim /etc/profileexport HIVE_HOME=/myfiles/hive/apache-hive-2.3.7-bin
一、服务器端挂载参数调整:二、nfs-client 客户端挂载选项调整 (多个选项之间用逗号分开)1.atime 更新访问时间 这个建议别用,会降低nfs的性能 可以加上noatime2.auto 能够被自动挂载通过-a选项3.async 异步挂载 sync同步挂载sync适用在通信比较频繁且实时性比较高的场合,比如Linux系统的rootfs通过nfs挂载。三、分析磁盘IO性能是否达上限:四、测
jdk安装与hadoop安装
一、sysbench简介1、sysbench简介sysBench是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况。sysbench提供如下测试:(1)CPU性能(2)磁盘IO性能(3)调度程序性能(4)内存分配及传输速度(5)POSIX线程性能(6)数据库性能(OLTP基准测试)sysbench支持MySQL、PostgreSQL、Oracle数据库。
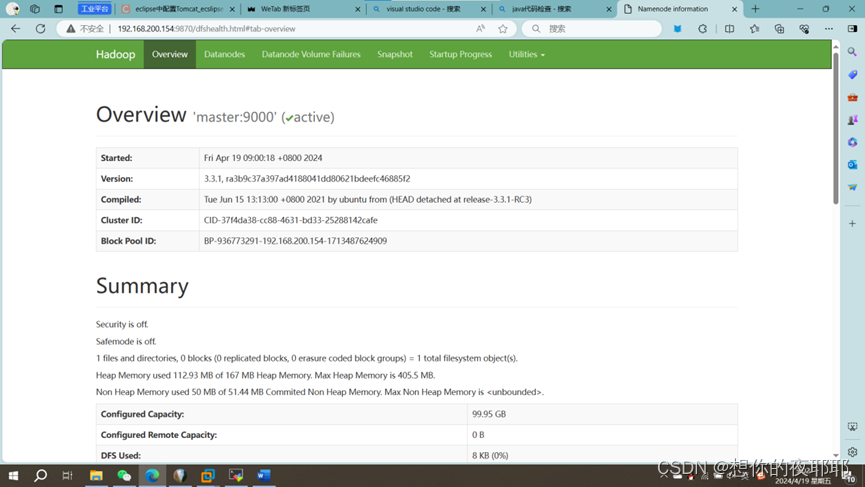
Hadoop3.3.0完全分布式集群搭建前言从零开始学习hadoop,记录成长过程,也是为了集群崩了还能搭好。话不多说,我们开始干活了!环境:虚拟机:VMware15Linux系统:centos7需要提前准备好的安装包:1.centos7镜像文件2.VMware安装包3.hadoop3.3.0和jdk1.8压缩包4.远程访问工具xshell和xftp接下来面对疾风吧一、VMware安装一直点击下一
《Linux寄生型病毒技术解析》摘要:本文剖析了一款针对64位Linux系统的ELF可执行文件感染程序,其通过修改ELF文件结构实现隐蔽寄生。该病毒具有自动传播、反调试检测和输出劫持功能,核心技术包括:1)利用ELF文件格式在代码段前插入病毒体;2)采用位置无关代码适应任意内存地址;3)通过PLT/GOT劫持实现函数调用重定向;4)使用ptrace系统调用实现反调试保护。病毒采用"反向文本段填充"
获取:4 http://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic/universe amd64 mailutils-common all 1:3.4-1 [269 kB]获取:8 http://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic/universe amd64 mailutils amd64 1:3.4-1
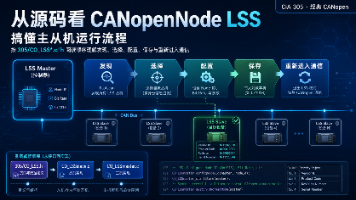
本文按CANopenNode源码305/CO_LSS*.c/h的阅读顺序,梳理LSS主站与从站如何通过固定帧完成发现、选择、配置Node-ID与位率、保存参数,并退出LSS模式,重新进入正常CANopen通信流程,适合源码学习与流程理解用。
CogAgent(Visual Language Model for GUI Agents / 用于图形用户界面智能体的视觉语言模型)。CogAgent 是由 清华大学 KEG 实验室 & 智谱AI (Zhipu AI) 提出的开源 Vision-Language Model (VLM,视觉语言模型),专门设计用来看懂 GUI 截图并操控界面,是典型的 GUI Agent(图形用户界面智能体)
这款工具的价值不在于它用了多么高深的技术,而在于它把**“交叉验证”**这个朴素的思想贯彻到了极致。当攻击者能够Hook系统调用、篡改内核数据结构时,单一的信息源已经不可信。只有通过多个独立渠道获取信息并对比差异,才能发现那些被精心隐藏的威胁。程序猿编码。
本文系统解构了 Linux 进程信号的产生、保存与捕捉机制。通过生活隐喻与底层原理解析,揭示了信号作为软件中断的异步通信本质,并深度图解了进程在内核态与用户态之间进行“8字型”上下文穿梭的精密流程。同时,立足 C++ 后端高并发场景,直击因信号异步触发而引发的不可重入函数与数据二异性灾难,给出 volatile 关键生存法则。本文旨在帮助开发者扫清多控制流异步调度的理论盲区,编写高可用、防崩溃的底
文章摘要 本章介绍了Linux MTD(内存技术设备)子系统的架构与实现,重点讲解了MTD的核心概念、体系结构和关键数据结构。MTD是Linux内核专门为Flash存储器设计的子系统,用于处理NOR/NAND Flash的特殊性,包括写前擦除、有限擦写次数、坏块管理等特性。MTD采用分层架构,包含硬件驱动层(NOR/NAND Flash驱动)、核心层(mtd_info结构体、坏块/分区管理)和设备
本文介绍了Linux内核中的缓存感知调度(CAS)技术及其架构设计。CAS通过理解硬件缓存拓扑,减少多线程应用中的缓存未命中和颠簸问题,显著提升了高并发任务性能(14%-44%)。传统调度器仅关注CPU负载均衡,而CAS在负载均衡中引入"任务聚合"逻辑,优先将数据共享线程调度在同一缓存域内,同时通过动态负载平衡避免过度迁移。内核为此扩展了task_struct结构,并与mm_cid机制协同工作,实
进程可以注册一个自己写的函数,当收到信号时,不执行默认动作,而是执行我们自定义的逻辑。注册方式:用signal()或更安全的系统调用,把信号和自定义处理函数绑定。关键注意事项:信号处理函数里,必须使用异步信号安全的函数(也叫可重入函数),比如write()类型的操作。不能用printfmalloc这类非安全函数,否则可能导致程序崩溃。类比:就像上课铃响了,你不回教室,反而去操场打球,就是 “自定义
libusb是一个使用C编写的库,它提供USB设备的通用的访问方法。APP通过它,可以方便地访问USB设备,无需编写USB设备驱动程序。可移植性:支持Linux、macOS、Windows、Android、OpenBSD等用户模式:APP不需要特权模式、也不需要提升自己的权限即可访问USB设备支持所有USB协议:从1.0到3.1都支持libusb支持所有的传输类型(控制/批量/中断/实时),有两类
加油.
摘要 字节跳动旗下产品(今日头条、西瓜视频、番茄小说、懂车帝)采用统一账务底层架构,与抖音、巨量体系共享300至尊权限和全链路审计系统。各产品功能覆盖如下: 今日头条:支持专栏付费、问答赏金、资讯广告收益管理 西瓜视频:处理中视频分成、付费观影和直播账务 番茄小说:管理章节付费、会员订阅和作者打赏分成 懂车帝:整合汽车经销商推广、付费咨询和广告结算 系统特性包括:资金池统一管控、九级熔断机制(永久
Hi3519DV500硬件原理与排查指南摘要 核心内容:本文档详细分析了Hi3519DV500芯片的硬件架构及鸿鸥派开发板的设计要点,重点涵盖电源系统、时钟电路、DDR4/eMMC接口等关键模块。 关键特性: 双核A55@1GHz + 2.5TOPS NPU + 4K编解码能力 2GB DDR4(32bit)+8GB eMMC存储方案 支持4路MIPI-CSI输入和MIPI-DSI/BT.1120
文章摘要: 本文深入探讨了Linux系统中的信号机制,主要内容包括: 信号概念:信号是进程间异步通信机制,用于通知特定事件发生,与信号量完全不同。 信号产生方式:键盘组合键(如Ctrl+C)、系统调用(kill/raise/abort)、硬件异常(除零/段错误)和软件条件(如定时器)。 信号处理流程:内核通过pending位图保存信号,在进程从内核态返回用户态时检查处理。 信号捕捉细节:用户自定义
无线升级(OTA)固件包 200KB,传输到一半突然断电,重启后进不了程序?不是网络不稳,而是 缺少断点记录(Checkpoint)和双分区回滚(Rollback)机制。本文解析工业级 OTA 的完整实现思路。
EAI1126B-Core-L是灵眸科技研发的一款应用于AIoT领域的核心板。核心板基于瑞芯微的RV1126B处理器设计,集成了4个Cortex-A53及独立的NEON协处理器,支持4K@30fps的 H.264/H.265解码器,还支持4K@30fps的H.264/H.265编码器。引入了新一代完全基于硬件的最大 12M 像素 ISP(图像信号处理器),实现了多种算法加速器,如HDR、3A、LS
📄 文档内容解读:字节临港A100智算中心落地行业应用(生物医药+金融量化)本文出自《上海临港智算中心A100 4000卡集群技术白皮书》,聚焦HPC+AI融合算力在两大高算力刚需行业的落地成果,集群硬件基底为4000张NVIDIA A100 GPU组成超算集群。一、5.3 生物医药与科学计算(HPC+AI)核心逻辑:传统高性能计算(HPC)依托A100的通用算力完成AI智能化升级,破解生物医药
Swap 是磁盘上用于扩展内存的空间。当物理内存不足时,内核会将不活跃的内存页换出(swap out)到磁盘,腾出物理内存给活跃进程。当系统物理内存 + swap 均已耗尽,且内核的"内存超额分配"(overcommit)策略导致无法满足新的内存申请时,OOM Killer 会选择一个进程杀死。
这篇指南将带你从零开始,在 ROS2 Jazzy 环境下,使用 TurtleBot3 完成自动探索建图。我们将从源码编译包开始,解决常见的依赖和编译问题,并最终实现机器人的全自动建图。
从 CANopen NMT 协议出发,结合 CANopenNode 源码解析状态切换、Heartbeat 上报、命令处理与错误降级流程。
老规矩,该教程是针对没有sudo权限的普通用户;以下是在 Conda 虚拟环境中使用 vLLM 部署模型的完整教程。
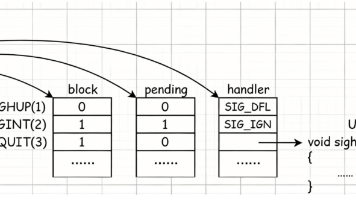
本文深入探讨了Linux信号的保存机制。当信号产生但进程暂时无法处理时,信号会被保存在内核维护的三个关键数据结构中:pending表记录未决信号,block表记录被阻塞信号,handler表存储信号处理方式。文章详细介绍了信号相关概念(递达、未决、阻塞与忽略的区别)以及内核中的信号集表示方式(sigset_t位图结构)。同时讲解了信号集操作函数(如sigemptyset、sigprocmask等)
Linux 7.1内核带来多项重要更新:全新NTFS驱动提升性能,Intel FRED中断机制革新,移除i486支持,以及QAT硬件加速Zstd压缩。新NTFS驱动基于iomap和folio重写,大幅提升读写效率;FRED重构了40年历史的中断处理流程;淘汰i486支持简化了内核代码;QAT新增Zstd硬件加速特别适合日志处理等场景。这些改进在存储性能、系统响应和特定工作负载方面带来显著提升。
linux
——linux
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 人工智能6S服务平台
人工智能6S服务平台

 深开鸿 技术专区
深开鸿 技术专区









 AMD开发者中国社区
AMD开发者中国社区



















 DAMO开发者矩阵
DAMO开发者矩阵



