- @xx_nm98
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
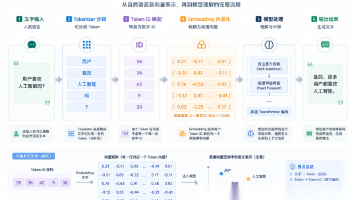
在传统软件开发中,我们习惯关注 CPU、内存、磁盘和网络带宽。但进入大模型时代后,一个新的资源单位开始频繁出现在开发者的视野中:
在LangGraph实战的实践中,很多开发者容易陷入「先学概念再落地」的误区。真正有效的方式是:从具体问题出发,逐步构建解决方案。这篇文章会先给出真实场景,再拆解技术方案,最后给出落地方法和检查清单,确保看完就能用。
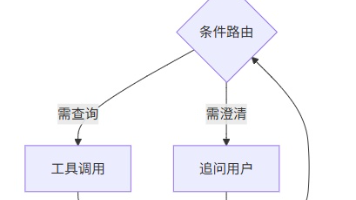
在LangGraph实战的实践中,很多开发者容易陷入「先学概念再落地」的误区。真正有效的方式是:从具体问题出发,逐步构建解决方案。这篇文章会先给出真实场景,再拆解技术方案,最后给出落地方法和检查清单,确保看完就能用。
本文介绍基于Coze平台开发的面试官智能体项目,采用Multi-Agent架构和低代码开发模式,实现简历评估、面试录音分析和面试题生成等功能。项目整合OCR、ASR、RAG等技术,支持多模态数据处理和私有化部署,提供完整端到端用户体验。适合零基础学员学习,解决求职者痛点,市场需求旺盛,是AI应用开发的热门方向。

近年来,多模态大语言模型已经能够同时理解图像和文本,并在许多视觉问答任务中表现出很强的能力。比如用户给模型一张图片,再问一句“这是什么建筑?”“图中的动物生活在哪里?”模型通常可以给出看似合理的回答。

AI Agent(人工智能体)是一种**具备自主决策能力的智能系统**,它以大型语言模型(LLM)为核心,能够主动感知环境、分析问题、规划行动并执行任务。与传统被动响应式AI不同,Agent能够根据任务目标自主选择执行路径,无需人类全程干预。
在大模型与智能体应用场景层出不穷的今天,作为一名不断学习的信息化数字化从业者,我们可以实践一下AI Agent基本开发流程,理论联系实践,以加深我们对AI Agent的了解。
人类拥有视觉空间智能,可以通过连续的视觉观察记忆空间。然而在百万规模的视频数据集上训练的多模态大语言模型(MLLMs)也能从视频中拥有 “空间思维 ”吗?本文提出了一个新颖的基于视频的视觉空间智能基准(VSI-Bench),其中包含 5,000 多对问答,结果发现 MLLMs 表现出了具有竞争力的视觉空间智能,尽管这种智能还达不到人类的水平。

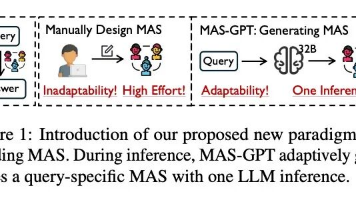
MAS-GPT通过让大模型自动生成针对特定问题的多智能体系统(MAS),在8个基准测试上平均性能超越10种主流方法,推理时间仅为传统多智能体方案的1/8,开创了AI从"使用工具"到"创造工具"的新范式。
本文系统介绍AI智能体低代码平台开发方法与实践,分析Dify、n8n和Coze三大平台的核心特点与适用场景。低代码平台通过图形化模块化设计,显著降低技术门槛,提升开发效率,提供可视化调试体验。针对不同需求:Coze适合快速原型验证和非技术用户;Dify适合企业级应用和复杂业务逻辑;n8n适合深度业务集成和自动化流程。低代码平台与代码开发形成互补,是智能体工程化的最佳实践。