




- @weixin_51674085
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
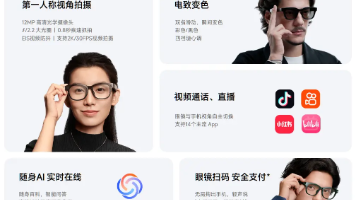
产品搭载超级小爱 AI 助手,支持语音控制和智能交互,配备 1200 万像素摄像头可实现实时拍摄、记录和场景识别功能。现已发布开源权重,这是一个支持多模态(文本/音频/图像/视频)理解的大模型,仅需 2GB RAM 即可运行,也是第一个在 lmarena 上得分超过 1300 分的 10B 参数模型。Claude 推出 Artifacts Space,即在你创建了 Artifact 后,可以把这个
是一个开放、免费且未经审查的视觉语言模型(VLM),其最大的特点是多样性和完全支持 NSFW 内容。Readme 的介绍很有意思。
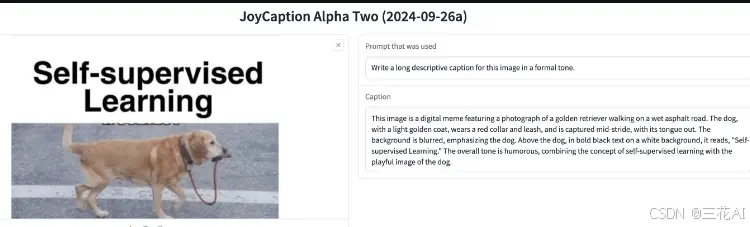
LangChain[6]推出了开源异步编码 Agent OpenSWE,该工具基于 LangGraph 技术栈构建,深度集成了 GitHub 平台,能够自主完成从规划到提交 PR 的整个开发流程。实际体验下来,就像是低配版 NotebookLM,生成时间需要 1-3 分钟,采用一男一女双角色对谈模式,音色和语调处理还可以,值得佬们前往官网[10]亲自尝试。具体申请条件和完整功能介绍可查看。此外,还
Qwen2 是对前一代 Qwen1.5 全面升级,它提供了多种尺寸的模型,支持更多语言,并在代码理解、数学解题等方面表现更加出色。千问 2 系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型,尤。其是代码及中文理解上,重回开源天花板模型。

详细介绍了其用于娱乐表演的机器人的设计图纸和主要控制技术,该机器人能在复杂地形行走,还能跳舞和表演。

的谷歌 NotebookLM 开源替代方案。只实现了核心功能,能够将 PDF 文件转换为播客。看了下代码,作者也是白嫖仙人,Llama 模型用的 fireworks 的免费接口,MeloTTS 用的 HF Space 的 gradio 接口。是一个基于 Llama 3.1 405B 和。

是由字节豆包团队推出的图像编辑工具,它能够根据任何文本提示修改现有图像,并保持一致性。该工具支持多种功能,如局部替换、几何变换、重新打光、风格更改、表情编辑、文字替换、姿势修改以及局部擦除等。从演示视频和官方提供的演示来看,效果非常强大,你们可以。不过,我看了下代码实现,发现它调用了字节的 API,但目前这个 API 还没有公开申请的地方,期待后续的开放。

他还表示他家的 Optimus 机器人可以变身猫娘、帮你接孩子、教孩子一切知识。未来量产Optimus 机器人的成本将低于一辆汽车,还讨论了未来战争形态、机器人数量比例等等。马斯克在直播玩大菠萝的切片视频中,预言 2026 年将实现AGI,并表示有1%概率我们的文明将直接Over。

产品搭载超级小爱 AI 助手,支持语音控制和智能交互,配备 1200 万像素摄像头可实现实时拍摄、记录和场景识别功能。现已发布开源权重,这是一个支持多模态(文本/音频/图像/视频)理解的大模型,仅需 2GB RAM 即可运行,也是第一个在 lmarena 上得分超过 1300 分的 10B 参数模型。Claude 推出 Artifacts Space,即在你创建了 Artifact 后,可以把这个
这模型支持文生视频和文+视频生视频,主要应用于机器人和自动驾驶领域的大规模合成数据生成。目前,英伟达已经开放了多个不同的预训练模型,这些模型均支持商业用途。,看看这个模型的实际效果如何。
