- @m0_59163425
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
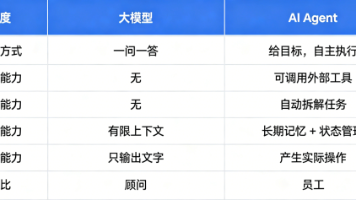
今天,5分钟,让你彻底搞懂这件事。一、先搞清楚:大模型 ≠ AI Agent---------------------很多人把大模型和智能体混为一谈,这是最大的误解。
前几天跟一个做AI应用开发的学员聊,他跟我说了一件事。去年年底他把简历投出去,大模型应用开发相关的岗位,投了三十多家,面试邀请拿到了两个。
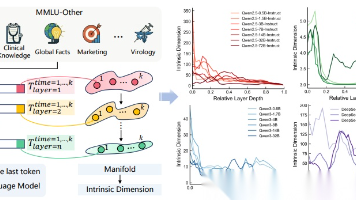
基于内部动力学提出统一的标签无关诊断指标,完全不依赖外部标注即可量化推理质量,为基准测试中心主义提供了互补框架。
概念边界 → 核心原理 → 适用场景 → 数据准备 → 参数配置 → 评测迭代大模型已经很强了,为什么还要微调?
让 Agent 会干活不难,难的是让它干得安全、可控、有迹可循。prompt 约束是软的,Agent 一旦"自信"起来就会绕过;真正的安全边界,要靠工程架构来保障。

前两个月,我在重构 AlgoMooc 网站过程中,发现一个问题:在 Claude Code 里把一个任务拆给 5 个 Subagent 并行跑,结果可能比 1 个 agent 从头干到尾还慢?

面试官问:"模型一本正经胡说时,logprobs 抓得到吗?"> "3 年 LLM 应用开发,主导过企业 RAG 知识库和多个 Agent 项目,熟悉主流大模型 API 与推理优化。"
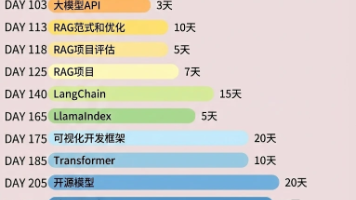
新手零门槛!全程复制命令直接跑通,一站式搞定 Python 高性能包管理器 + LangChain 框架 + DeepSeek 大模型本地开发环境,不用复杂配置,不用踩坑,看完就能上手实操~

在搭建私有知识库、落地文档问答类大模型应用时,RAG 是解决模型知识滞后、回答内容不可溯源问题的核心方案。不少开发者可以依托开源项目快速完成环境部署与功能调试,但对于整条技术链路背后的设计逻辑、核心组件的运行原理缺少系统性认知。
RAG(Retrieval-Augmented Generation,检索增强生成)已成为大模型落地最核心的技术方案之一。无论是智能客服、企业知识库、合同审查还是内部问答助手,RAG 都是标准答案。