




- @weixin_52582710
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
NVIDIA Isaac GR00T N1.5-3B是一款开源人形机器人基础模型,具备多模态处理能力,整合视觉(SigLip2 Transformer)和语言(T5 Transformer)编码器,采用流匹配动作Transformer架构。该模型通过扩散Transformer(DiT)和自适应层归一化技术处理机器人本体感知与动作序列,支持224×224 RGB图像、浮点数状态数据和文本指令输入。适

目前最强大的开源具身智能模型速览:RoboBrain2.0-7B
DeepSeek-OCR是由DeepSeek-AI团队开发的开源OCR模型,采用"LLM为中心"的视角,通过上下文光学压缩技术将高分辨率图像压缩为64-400个视觉token,显著降低计算资源需求。该模型支持多种分辨率模式,在保持高准确率的同时实现20倍以上的信息压缩率,显存占用低于同类模型10倍以上。在Fox benchmark测试中,大模型版本达到97.3%的准确率,小模型

本文提出了一种基于视觉-文本压缩的新型大语言模型DeepSeek-OCR,旨在解决长文本处理的计算挑战。通过将文档转换为图像实现高效信息压缩,模型采用DeepEncoder编码器和MoE解码器架构,支持多分辨率输入和多种压缩比需求。实验表明,在10倍压缩比下模型保持97%的解码精度,在OCR任务中表现出色。该研究为长文本处理提供了新思路,通过模拟人类记忆遗忘机制,有望实现理论上无限上下文架构。

在新的yolov5版本中已加入了–frame-interval参数,可直接使用。以下用于早期版本无此参数的情况。

目前最强大的开源具身智能模型速览:RoboBrain2.0-7B
研究背景与目的:通用机器人需要兼具多样的身体和智能的大脑。尽管人形机器人硬件平台已取得进展,但要实现通用自主性,还需一个在大规模多样化数据上训练的机器人基础模型,使机器人能够推理新情况、稳健处理现实世界的变化并快速学习新任务。方法与创新点:介绍GR00T N1,一个面向通用人形机器人的开放基础模型。它是一个视觉-语言-行动(VLA)模型,采用双系统架构。视觉-语言模块(系统2)通过视觉和语言指令解

区域注意力模块(Area Attention)区域注意力模块是一种简单高效的注意力机制,通过将特征图在垂直或水平方向上划分为多个区域,避免了复杂的窗口划分操作,仅需简单的 reshape 操作即可实现,从而提高了速度并保持了较大的感受野。该模块将注意力机制的计算复杂度从 2n²hd 降低到 1/2n²hd,同时对性能影响较小。残差高效层聚合网络(R-ELAN)R-ELAN 是为了解决注意力机制引入

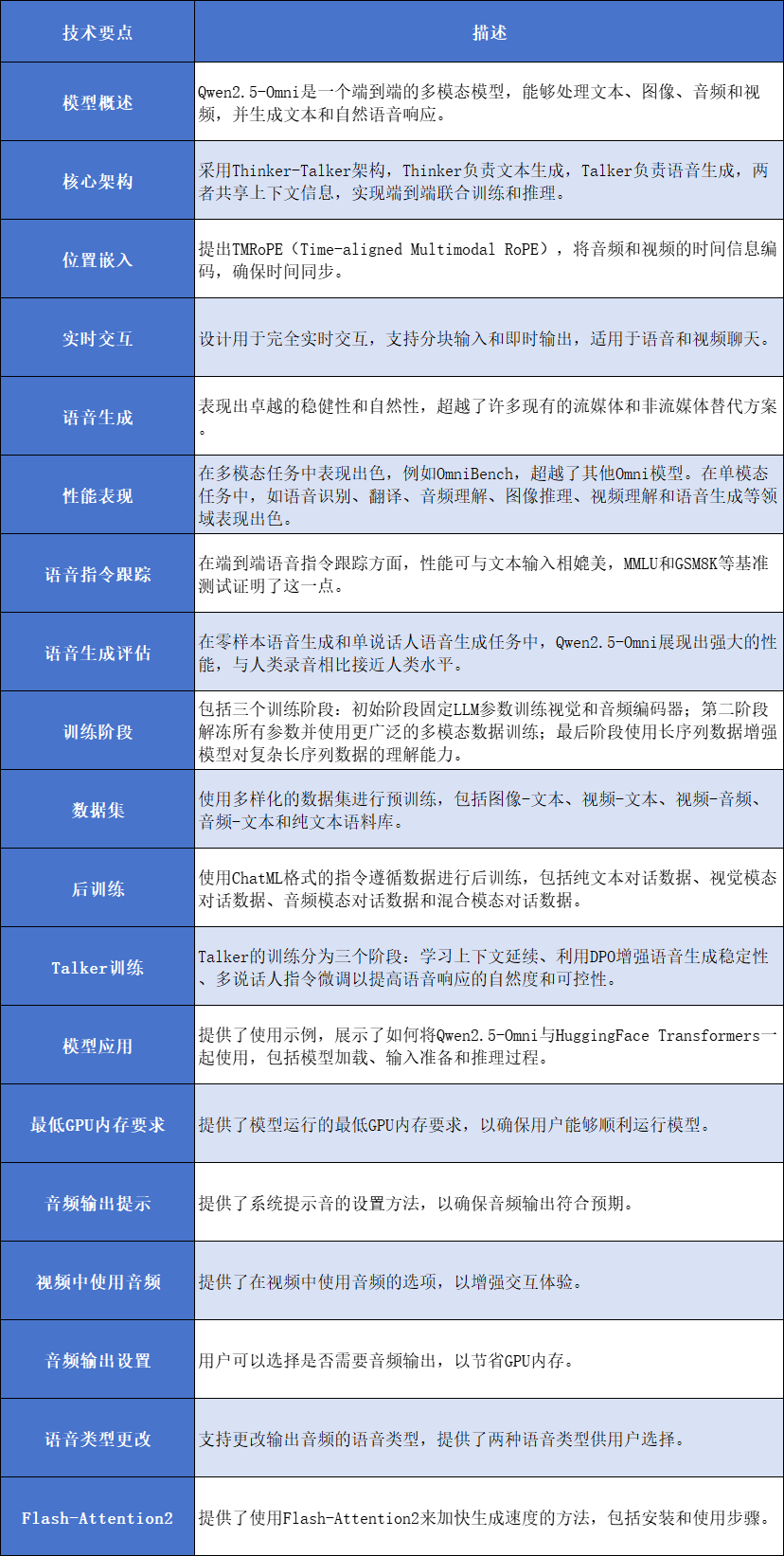
Qwen2.5-Omni在多模态任务中表现出色,不仅在需要集成多种模态的复杂任务中表现出色,而且在单模态任务中也展现了强大的性能。其创新的架构和位置嵌入方法使其在实时交互和语音生成方面具有显著优势。未来,Qwen团队计划进一步提升模型的性能和输出能力,以推动人工通用智能(AGI)的发展。
从抽象到具体:用于机器人操作的统一大脑模型
