- @leah126
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
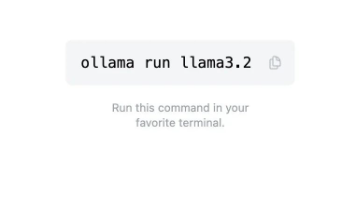
前两天发了一篇[怎么更好使用 DeepSeek 的文章]后,很多朋友在后台留言,希望了解 DeepSeek 的更多玩法。春节前几天事情较多,这两天终于闲下来了,打算再分享一些自己使用 AI 功能的经验,包括但不限于 DeepSeek。这一篇先介绍呼声较高的在本地部署 DeepSeek-R1 大语言模型的方案,后续会带来 DeepSeek 平替、DeepSeek 生成图片、视频、构建知识库等一系列文
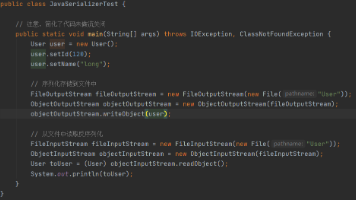
反序列化其实就是序列化的逆向过程,如果你看懂了序列化的关键代码,那么看这个过程就不会很难,下面贴出关键代码做出分析这里能够看到会根据反序列对象的具体类型分别做不同的处理,我们当前的对象是 User 对象所以会进入箭头指向的方法。
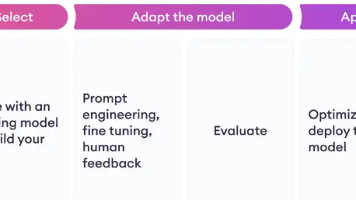
众所周知,大语言模型(LLM)正在飞速发展,各行业都有了自己的大模型。其中,大模型微调技术在此过程中起到了非常关键的作用,它提升了模型的生成效率和适应性,使其能够在多样化的应用场景中发挥更大的价值。那么,今天这篇文章就带大家深入了解大模型微调,主要包括什么是大模型微调、什么时候需要大模型微调、大模型微调方法总结、大模型微调最佳实践等。
即便检索到了优质的上下文信息,大语言模型(LLM)生成答案的环节仍需优化,才能确保最终输出精准契合用户需求。
吴恩达的话让我特别振奋:AI时代不是威胁,而是机遇!产品经理,尤其是AI产品经理,将成为未来软件开发的核心角色。别被AI的“速度”吓到,关键是提升自己的能力——懂技术、会迭代、善管理、不怕模糊、爱学习。如果你像我一样对AI产品管理感兴趣,不妨从现在开始行动:多看点AI技术资料、试试用AI工具做原型、跟工程师多交流……未来属于那些敢想敢干的人!让我们一起抓住这个创造的黄金时代吧!
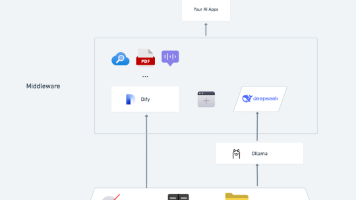
想象一下,拥有一款独立运行、全程保密、还能够分析本地文本内容,随时提供精准的对话服务,并且具备联网搜索能力的私有化 AI 应用是一种怎样的体验?本文将带你一步步搭建,快速部署全功能的私有化 AI 助手。DeepSeek 是一款突破性的开源大语言模型,它的先进算法架构和“反思链”能力,让 AI 对话交互变得更智能与自然。通过私有化部署,你可以完全掌控数据的安全性,并根据自己的需求灵活调整部署方案,打
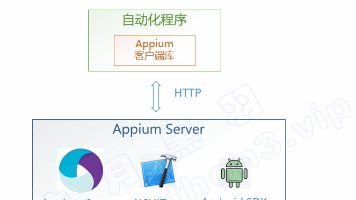
Appium 是一个开源的移动应用自动化测试工具,支持 iOS 和 Android 平台。它可以用来自动化测试原生应用、混合应用和移动网页应用。Appium 提供了跨平台支持,能够在真实设备、模拟器和虚拟机上进行测试,并使用统一的 API。同时,Appium 兼容 WebDriver 协议,支持多种编程语言,如 Java、Python 和 JavaScript,简化了移动应用测试的自动化过程,并与
*工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。红
手工测试的占重比例达到了70%,相对开发来说,测试的门槛低,薪资也相对比开发的低不少,所以做自动化测试。接下来我们就来讲解自动化测试实战场景文件上传与弹窗处理。
自动化:接口自动化,Web自动化(selenium),APP自动化(appium)web自动化环境搭建中遇到的最大问题,就是各个版本不匹配导致,所以找到与之相匹配的版本很重要,只要这样才能继续……大纲:1.如何下载对应的web驱动2.eclipse中简单的demoWeb自动化原理1.如何下载对应的web驱动在downloads页签下的找到浏览器driver区域,点击最新的到了详情页面驱动不要太新,