




- @Hofong1966
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
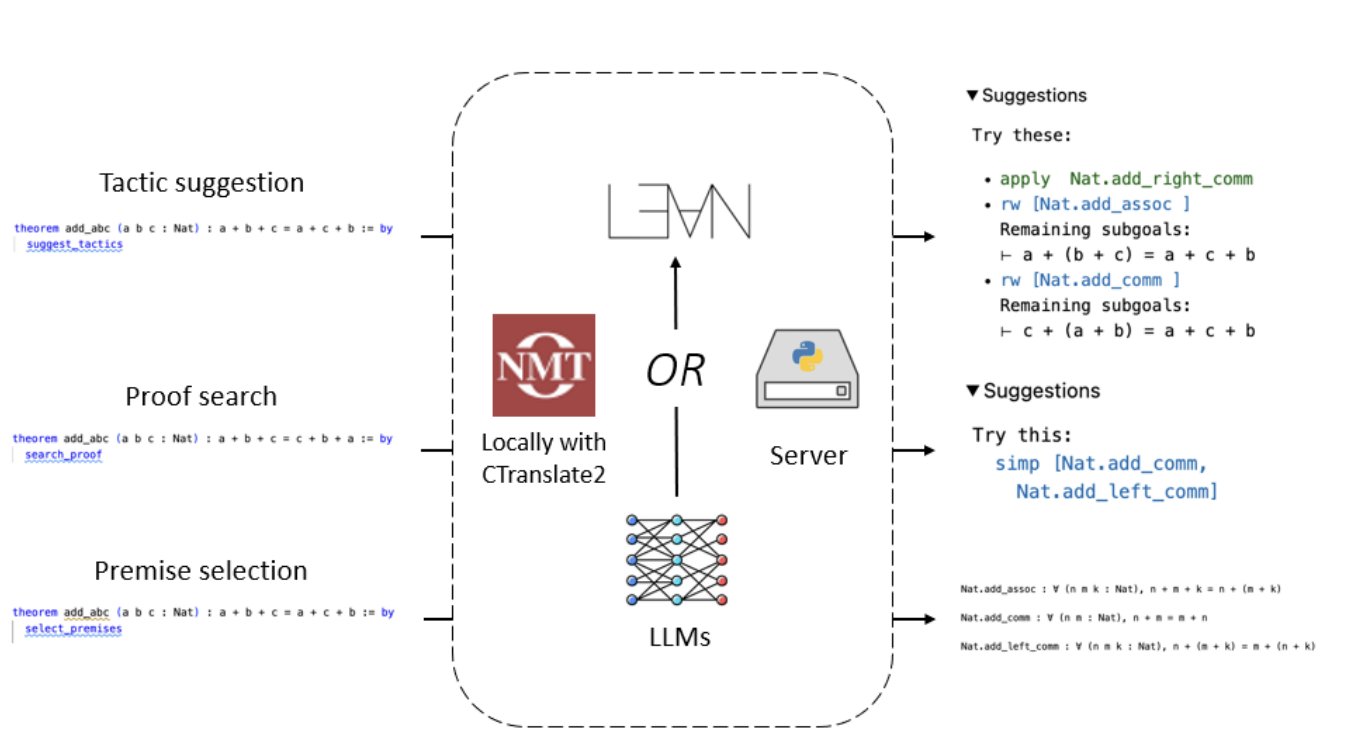
search\_proofs工具通过结合LLM生成的建议和现有的基于规则的搜索方法,进一步自动化了证明过程,探索潜在的证明路径。随着这一领域的研究进展,我们可以预期更多复杂和强大的基于LLM的工具将重塑数学研究和教育的格局。Lean Copilot的设计考虑到了当前基于LLM的定理证明方法中存在的问题,特别是在静态数据集上训练的模型与交互式证明助手的动态环境之间的脱节。想象有一个世界,数学家身边有
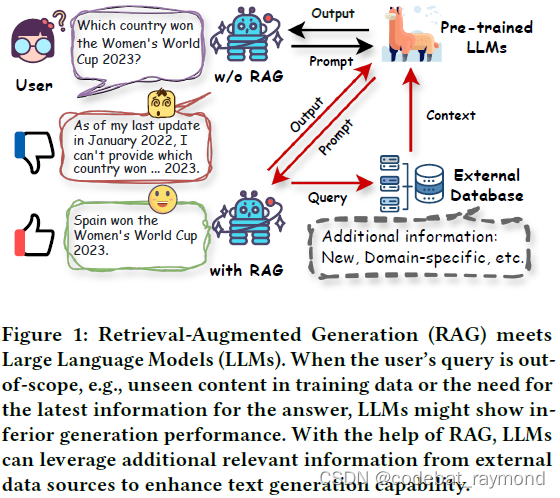
作为最基础的数据挖掘技术之一,检索旨在理解输入查询并从外部数据源中提取相关信息。它在各个领域都有广泛的应用,如搜索、问答和推荐系统。例如,搜索引擎(如谷歌、必应和百度)是检索在行业中最成功的应用;它们可以过滤和检索与用户查询最相关的网页或文档,使用户能够有效地找到所需信息。同时,通过在外部数据库中有效地维护数据,检索模型可以提供可靠和及时的外部知识,从而在各种知识密集型任务中发挥重要作用。由于其强
值得注意的是,由于语言的顺序特性,token级MDP具有独特的树形结构(tree structure),即在给定输入提示(初始状态)的情况下,模型的每个决策都会导向一个全新的状态,这与一般的MDP(例如棋类游戏)不同。DPO算法的目标就是调整模型参数,使其所对应的奖励函数符合人类偏好,同时DPO能够学习任意密集奖励函数对应的最优策略。近年来,随着深度学习的发展,深度Q网络(DQN)等算法将神经网络

作为最基础的数据挖掘技术之一,检索旨在理解输入查询并从外部数据源中提取相关信息。它在各个领域都有广泛的应用,如搜索、问答和推荐系统。例如,搜索引擎(如谷歌、必应和百度)是检索在行业中最成功的应用;它们可以过滤和检索与用户查询最相关的网页或文档,使用户能够有效地找到所需信息。同时,通过在外部数据库中有效地维护数据,检索模型可以提供可靠和及时的外部知识,从而在各种知识密集型任务中发挥重要作用。由于其强
不过,正如我所指出,文章对 xLLM 的实际效能和普适性的讨论还比较少,可能还需要更多研究和实践来验证。总的来说,xLLM 提出了一个很有价值的思路,通过专业化和知识结构化来提升语言模型效能,这与我早年在 IBM 的经验不谋而合。1. 针对不同领域构建专门的语言模型,并提供定制化参数,这种"专业化"的做法有助于提升模型在特定领域的表现,降低计算成本,并避免大而全模型常见的"幻想"问题。5. 作者慷
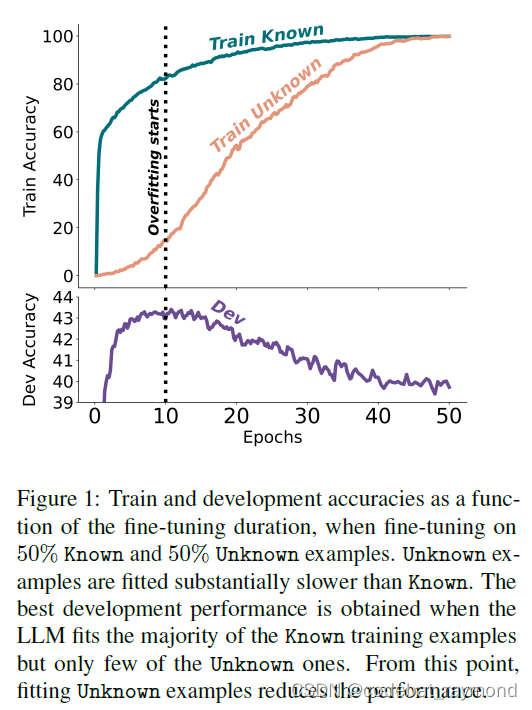
当大型语言模型通过监督式微调进行对齐时,它们可能会遇到在预训练期间没有获得的新事实信息。人们经常推测,这可能会教导模型产生事实上不正确的回应的行为,因为模型被训练成生成没有基于其预先存在的知识的事实。在这项工作中,Google研究了这种暴露在新知识下对微调后模型利用其预先存在知识的能力之影响。为此,他们设计了一个受控的设置,专注于闭书问答,改变引入新知识的微调样本的比例证明,大型语言模型在通过微调
jianxie22@m.fudan.edu.cn, {zhang.13253, su.809}@osu.edu摘要通过向大型语言模型(LLMs)提供外部信息,工具增强(包括检索增强)已成为解决LLMs静态参数记忆局限性的一个有前景的解决方案。然而,当外部证据与其参数记忆冲突时,LLMs对这种外部证据的接受程度如何?我们对LLMs在知识冲突下的行为进行了第一次全面和受控的调查。我们提出了一个系统的框

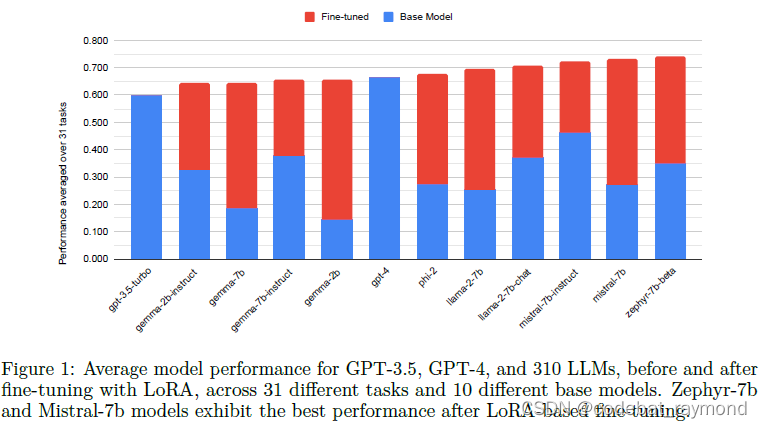
全面评估了LoRA微调在提升语言模型性能方面的有效性。通过在大量任务和基础模型上的实验,证实了LoRA作为一种参数有效微调技术的优势。4位量化LoRA微调模型能够以较小的开销达到甚至超过GPT-4的性能,这一结果非常振奋人心。
值得注意的是,由于语言的顺序特性,token级MDP具有独特的树形结构(tree structure),即在给定输入提示(初始状态)的情况下,模型的每个决策都会导向一个全新的状态,这与一般的MDP(例如棋类游戏)不同。DPO算法的目标就是调整模型参数,使其所对应的奖励函数符合人类偏好,同时DPO能够学习任意密集奖励函数对应的最优策略。近年来,随着深度学习的发展,深度Q网络(DQN)等算法将神经网络
多年來,大型語言模型(LLMs)已成為一項突破性技術,在醫療保健的各個方面都有巨大的潛力。這些模型,如GPT-3、GPT-4和Med-PaLM 2,在理解和生成類人文本方面表現出卓越的能力,使其成為應對復雜醫療任務和改善患者護理的寶貴工具。它們在各種醫療應用中都顯示出前景,例如醫療問答(QA)、對話系統和文本生成。此外,隨著電子健康記錄(EHRs)、醫學文獻和患者生成數據的指數級增長,LLMs可以
