登录社区云,与社区用户共同成长
邀请您加入社区
InnoAI SQL 助手一、项目说明非功能需求:① 兼容性:适配 openEuler/RHEL Linux 系统,兼容 MySQL 8.0.45,适配Qwen、DeepSeek 系列开源模 型;② 稳定性:自然语言识别容错率高,无匹配数据可正常提示,API、数据库异常捕获不崩溃;③ 安全性:仅开放只读查询权限,密钥文件设置 600 权限,不打印明文账号密三、环境搭建系统搭建及初始化1、安装虚拟机
本文介绍了一个基于MySQL 8.0和Python 3.11的数据库智能助手项目,主要实现自然语言转SQL查询和SQL性能调优两大功能。项目采用openEuler操作系统,整合了腾讯云大模型API(TokenHub)和Streamlit框架,通过以下技术方案实现。
Oracle性能问题分析:SQL内存管理器Latch竞争 文章分析了Oracle数据库(10.2.0.5.8 RAC环境)中出现的严重性能问题,主要表现为大量"latch free"等待事件(高达700个)。通过排查发现是"SQL memory manager latch"竞争导致的系统瓶颈。 关键发现: 多会话(包括CRM_APP和INTF用户)都在竞争同
监控先行:建立完善的SQL性能监控体系基线管理:定期收集性能基线,及时发现退化计划分析:深入理解执行计划,找出性能瓶颈索引优化:合理创建和维护索引SQL改写:掌握常见的SQL优化模式并行执行:充分利用OceanBase的并行处理能力持续优化:建立持续的性能优化机制。
http://www.oschina.net/p/chartsqlhttps://github.com/paulasmuth/fnordmetric FnordMetric ChartSQL 可以让你用 SQL 语句来生成图表,图表可使用 SVG 向量图进行渲染,可轻松的嵌入到网页中。ChartSQL 可以通过 FnordMetric Server 直接在Web 端运行并生成图表
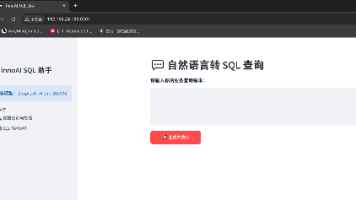
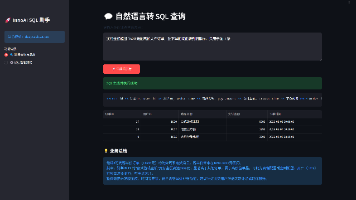
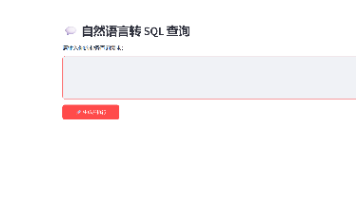
输入中文业务描述,大模型自动生成合规SELECT语句,强制拦截 INSERT/UPDATE/DELETE/ALTER等危险操作;自动执行 SQL,表格化展示查询结果;调用大模型生成通俗易懂的业务数据分析总结,替代人工报表解读。本项目打通Linux 运维 + MySQL 性能调优 + Python 开发 + 大模型 NL2SQL四大技术栈,完整实现 AI 赋能数据库运维的轻量化解决方案。
《基于AI的MySQL智能查询与优化工具开发实战》项目摘要 本项目针对传统DBA工作中的三大痛点(业务人员SQL门槛高、性能优化效率低、数据安全风险),开发了一套轻量化智能工具。核心功能包括:1)自然语言转SQL查询,业务人员输入中文需求即可获取格式化数据及AI业务解读;2)SQL自动调优,通过EXPLAIN分析执行计划输出索引优化方案;3)全链路安全管控,拦截危险SQL语句,敏感配置隔离存储。项
/ 继承MyBatis-Plus的CRUD方法。
50+ SQL 数据库,一个桌面客户端。AI agent 能力,Rust + Tauri 原生构建。
一、项目概述本项目是基于openEuler、MySQL8.0、Python3.11与腾讯云TokenHub大模型平台开发的电商订单智能SQL工具,支持命令行终端、Streamlit网页双交互入口,核心实现自然语言自动生成合规MySQL查询、SQL执行计划解析与性能调优两大核心能力,融合数据库运维与大模型NL2SQL技术,适用于数据查询、SQL性能优化轻量化场景。二、需求分析(一)功能性需求。
ChatDB是一个将自然语言自动转换为SQL查询语句的系统。ChatDB是什么:用自然语言自动生成SQL的工具核心价值:让不懂SQL的人也能查数据库安装简单几个包,配置一下API就能用使用方便:打开网页,输入中文问题就行【完】
做电商运维经常遇到两大痛点:1. 业务运营、产品不懂 SQL,每次查订单报表都要排队找开发,沟通成本极高;2. DBA 日常重复分析慢查询 EXPLAIN 执行计划,判断全表扫描、索引缺失、文件排序等瓶颈,机械工作占用大量精力。为此我基于openEuler + MySQL 8.0.45 + 腾讯云 TokenHub 大模型聚合平台,单人 3 天完成一套「InnoAI SQL 助手」,实现自然语言一
35岁,Java后端十年,上个月被"优化"了。HR说的是"结构调整",但我看了一眼留下来的名单——清一色30岁以下。我没马上投简历。因为我知道,投了也没用。十年经验在简历上看起来挺厚重,但招聘方看到"35岁"这俩字,基本就翻篇了。那三天我就在家发呆。第四天,我打开了一个AI工具,不知道要干嘛,就随手输了一句:“帮我分析一下,我这十年经验,在AI时代还有没有价值。AI给我回了一大段。我仔细看,有一句
本文介绍了一个基于MySQL8.0和大语言模型的电商订单库智能查询系统。系统通过自然语言输入自动生成合规SQL语句,执行查询并输出结构化结果,同时提供执行计划分析和优化建议。主要内容包括:1.环境搭建(openEuler系统、Python3.11、MySQL8.0部署);2.核心功能实现(自然语言转SQL、查询执行、性能分析);3.两种交互方式(命令行和Streamlit可视化界面);4.安全防护
st.warning("此处请输入待分析的 SELECT SQL 语句,请勿输入自然语言描述。# ====================== 全局CSS样式定制:优化字体、间距、按钮、代码块、表格展示 ======================# ===================== 模板2:SQL性能调优分析专用提示词 =====================# ==========
本文完整分享InnoAI SQL助手实战项目:基于国产化openEuler服务器,结合MySQL 8.0、腾讯TokenHub大模型,实现自然语言生成只读SQL、自动查询、AI业务解读、EXPLAIN智能调优,同时提供命令行+Streamlit网页双端,全程可落地、含完整部署代码与界面演示。本项目完整覆盖国产化服务器环境搭建、Python分层工程开发、大模型NL2SQL落地、Web可视化部署全流程
本项目基于 openEuler Linux、MySQL 8.0.45、Python 3.11 以及腾讯云 TokenHub 大模型聚合平台,构建了一套名为 InnoAI SQL 助手的电商订单库 AI 智能查询与 SQL 性能调优一体化工具。该工具旨在降低数据库查询门槛,业务人员无需掌握 SQL 语法,只需输入自然语言描述,即可自动生成安全的只读 MySQL 查询语句、执行查询,并以结构化表格形式
本文将揭开大模型训练的神秘面纱,聊聊那些教科书不会告诉你的工程化细节。
本文结合售后工单完整实战案例,从零讲解 LangGraph 与 CrewAI 两大主流多智能体框架核心用法,包含可运行完整代码、单元测试、业务场景选型分析,区分两种框架适用场景,适合大模型工程落地入门学习。
本文介绍了一个基于MySQL8.0与大模型API的电商订单智能查询与调优系统项目。系统通过自然语言输入自动生成合规SQL查询语句,执行查询并提供业务解读,同时支持SQL性能优化分析。项目采用分层架构设计,包含交互层、核心业务层和AI服务层,支持命令行和Web两种方式。详细说明了环境搭建:OpenEuler系统、Python3.11.9、MySQL8.0.45;API获取、脚本开发及测试流程,并提供
数据表字段名并没有标注 “单价(price per unit)”,仅仅命名为 price。所以 price 既可能代表总价,也可能代表单价。(模型)默认把它当成了总价。如果 price 确实是总价,那大模型给出的答案就是正确的。但现实场景里,数据库的字段命名往往不会尽善尽美,本例就是模拟真实业务里的这种情况。由此得出结论:大模型很容易出现推理错误。我们需要通过某种方式告知模型:price 字段指的
本项目基于国产openEuler操作系统、MySQL 8.0数据库,结合腾讯云TokenHub大模型网关,开发轻量化InnoAl SQL智能助手系统,面向电商订单数据业务场景,支持接收自然语言需求自动生成合规只读SQL查询语句、执行数据统计并输出AI业务分析结果,同时可解析SQL执行计划、智能生成索引优化方案。将上一步生成的统计 SQL 粘贴至调优功能,程序自动抓取 EXPLAIN 执行计划,识别
数据库的页(如PG的8KB)在操作系统层面通常由多个OS页(如4KB)组成。当数据库发起一个8KB的写操作时,在存储层实际上是两次4KB写入。如果写入中途断电或系统崩溃,可能出现前4KB写入成功、后4KB未写入的情况——这个数据库页就变成了"一半新一半旧"的损坏状态,这就是页分裂。
本文探讨了数据库迁移中“零代码”与“零业务代码修改”的区别,指出MySQL与人大金仓数据库在语法上的四大核心差异(标识符包裹、空值处理、分页语法、大小写敏感)。为实现在不改动业务代码的前提下完成迁移,提出两层技术方案:1)数据库层通过金仓的MySQL兼容模式和关键参数配置(如enable_ci)实现80%的语法兼容;2)应用层通过MyBatis拦截器动态改写剩余20%的特殊语法(如反引号替换、函数
NineDataSkill作为AI Agent与数据库之间的安全中间层,通过权限管控、SQL审核、审批流程三重机制解决AI直接操作数据库的安全隐患。其核心功能包括:1)权限隔离,Agent无法获取凭证;2)只读查询需人工确认并过规则引擎;3)变更操作强制走工单审批;4)数据导出受流程管控。该方案在提升开发效率的同时,确保所有数据库操作符合企业安全规范,审计记录完整可追溯,实现AI自动化与数据安全的
某天临时被当成壮丁拉去参加一个非常牛逼的应用监控平台(后续会开源),然后大佬就给我派了一个任务,要将项目中的查询性能优化 50 倍以上,大佬对我如此地寄予厚望,我怎么能让大佬失望呢(虽然我...
性能优化是婚恋交友系统源码的重要一步,婚恋交友系统源码可以用到的性能优化工具有哪些呢?性能优化的帮助工具:MAT,Memory Monitor(属于AndroidMonitor中一个模块),HeapTool(查看堆信息),Allaction Tracking,LeakCanaryLint工具1.Allaction Tracking(1)追踪在内存图中点击途中箭头的部分,启动追踪,再次点击就是停止追
不是过时技术,而是 Spring Boot 自动配置体系中经过十年生产验证的“稳压器”。它用简单的 Properties 格式,换来了确定性的加载顺序、可控的条件解析边界、以及无与伦比的跨版本韧性。而是 Spring Boot 为简化新项目入门体验所做的妥协,它牺牲了鲁棒性,换取了语法简洁——这本无对错,但当你的 Starter 要承载金融交易、医疗影像、政务审批等关键业务时,简洁就不再是美德,确
日常开发与数据库实训中,慢查询、高并发阻塞、分页卡顿等问题几乎都源于不合理的 SQL 编写与索引设计。很多人只停留在基础 CRUD 编写,不会借助 EXPLAIN 分析执行计划,也不了解联合索引、行锁、临键锁会对查询性能产生连锁影响。本文结合实操 SQL 案例,系统梳理索引规范、语句改写、分页 / 分组优化、锁机制避坑等全套 SQL 优化方案,兼顾理论原理与落地实操。
核心作用:定义项目命名空间和窗体主类,承载所有分页查询相关逻辑。namespace 分页查询// 后续所有模块代码依次插入此处核心作用:定义数据库连接字符串和分页核心参数,全局可用,方便后续调用。// 数据库连接字符串(硬编码,实际开发建议配置在app.config中)uid=sa;// 当前页数,默认初始化为第1页// 每页显示的记录条数,默认每页3条// 总页数,初始化为0,后续通过计算赋值。
Etched 的技术路线提供了一种有别于 Nvidia GPU 基础设施的替代方案,尽管此前曾遭受市场质疑,但其创新方向仍赢得了投资者的强烈信…CYBERTEC 工程师 Wellingtone Luvonga 详细介绍了如何配置 CloudNativePG 的分布式拓扑来应对这一挑战,内容涵盖所需的 YAML 配置、部署流程,以及实际操作中遇到的各类问题。此次更新标志着 Claude 在语音交互能
本文详解工业场景时序数据架构方法论——时序数据的核心价值是"看到变化",但需与关系、GIS、向量数据关联才能做出准确判断。拆解金仓 KES TimeSeries 在写入(Append 追加写、无锁化)、存储(Delta-of-Delta 压缩 10:1)、查询(连续聚合毫秒级响应)三个链路的专项优化,给出融合架构选型建议。
sql
——sql
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 深开鸿 技术专区
深开鸿 技术专区






 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区
 AI Agent技术社区
AI Agent技术社区







 EazyDevelop社区
EazyDevelop社区




 乐奇 Rokid 开放社区
乐奇 Rokid 开放社区



 DAMO开发者矩阵
DAMO开发者矩阵
 2048 AI社区
2048 AI社区


 AI硬件创业社区
AI硬件创业社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区
