登录社区云,与社区用户共同成长
邀请您加入社区
本文介绍了一个开源服务器管理面板项目,旨在解决阿里云自带Web终端操作卡顿、功能局限的问题。作者通过Cursor+grill-me工具深入分析需求后,开发了这个集文件管理、服务监控、资源查看和终端操作于一体的轻量级解决方案。项目特点包括:可视化展示无端口服务运行状态、解析nginx反代路径、基于systemd的服务管理、拖拽文件操作和内嵌代码编辑器。支持一键部署到Linux服务器,适合个人或小团队
EventHouse 是 EventBridge 面向事件数据推出的云原生事件湖仓,帮助企业在一套 Serverless 事件数据服务中,完成实时事件的接入、治理、分析和 AI Agent 调用,打通 Data to Agent 的完整链路。
在2026世界人工智能大会现场,阿里云全面展示了从底层硬件、超级算力到上层智能应用的全栈AI技术布局,完整呈现其在AI基础设施与云端生态的最新落地成果
部署环境与准备环境本机Windows10操作系统阿里云/腾讯云Centos7.7服务器准备Hexo 本地博客Xshell 连接到你的服务器阿里云服务器配置Git安装依赖库yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel安装编译工具yum install gcc perl-ExtUtils-MakeMa
注册阿里云账号bashpip install aliyun-python-sdk-corepip install aliyun-python-sdk-nls````aliyun-python-sdk-nls` 是语音交互的专用SDK。## 5. 基础示例:一句话语音识别一句话识别是最简单的模式,适合测试。下一步建议。
本文介绍了解决AI Agent联网搜索短板的工具deuseek。当前国产大模型API在代码和Agent任务上表现优秀,但在联网搜索环节存在两大痛点:一是多数API不带服务端搜索工具,二是搜索覆盖不足。deuseek通过CLI工具提供了多源搜索和全文抓取功能,采用三层架构设计(search/fetch/parse),已实现前两层功能。其特色包括标准化结果输出、智能错误处理、结构化内容提取等,并采用三
通过阿里云渠道代理(如典名科技)购买云服务,不仅能够获得实实在在的价格优惠,还能享受更贴心、更专业的本地化服务支持。选择合适的代理合作伙伴,需要综合考虑价格、服务、技术能力等多方面因素。建议企业在选择代理时,不要只看重价格优惠,更要关注代理的综合服务能力和长期合作价值。随着云计算市场的不断发展,阿里云渠道代理体系也将不断完善,为用户提供更加优质、优惠的服务体验。无论是中小企业还是大型企业,都可以通
Tair 作为 AI 数据层适用于:多轮对话机器人(会话上下文管理)、Agent/Copilot 应用(工具调用状态、记忆存储)、RAG 知识库(文档向量存储与检索)、推荐与个性化(用户画像向量、实时特征)、以及需要省 Token 的高并发问答(语义缓存)。这些场景都能用一套 Tair 统一支撑。
语义缓存适用于以下场景:智能客服与工单机器人(重复咨询多)、企业知识库/文档问答(问法多样但答案稳定)、代码 Copilot 与研发助手(常见问题重复率高)、面向 C 端的高并发问答应用(对时延和成本都敏感)。这些场景的共同点是"问题重复率高 + 对时延/成本敏感",都能用 Tair 语义缓存显著降本提速。想让 LLM 应用同时省 Token 又提速,推荐用阿里云 Tair(云数据库 Redis
本文从技术维度客观测评乘路资讯,指出其作为阿里云生态合作伙伴,课程基于云原生AI技术,聚焦B端企业商用AI落地需求,提供个性化方案及技术陪跑服务,避免不良机构的通用模板、无资质等问题。多家企业反馈其有效助力数字化部署,证实其正规性,适合中小企业系统学习商用AI方案。
本文详细介绍了如何在OpenClaw中配置阿里百炼Coding Plan的完整教程。主要内容包括:获取专属API Key(格式为sk-sp-xxxxx)的步骤,通过命令行安装OpenClaw的方法,初始化配置流程(选择Custom模式),以及如何手动编辑配置文件添加百炼Provider。教程还提供了推荐的模型列表(如qwen3.7-plus、kimi-k2.5等),验证配置的方法,常见问题解答(如
AI 客服进入业务执行阶段。大模型客服不再局限于关键词匹配,而是开始处理商品问答、多轮咨询、主动推荐、风险识别和人工协同。CallFay 母语AI面向三类业务。境内版服务淘宝、抖音、拼多多、京东等场景,跨境版面向 TikTok Shop、Amazon、Shopee 等平台,商贸版面向 1688、阿里巴巴国际站等 B2B 场景。系统能力覆盖接待与转化。产品支持多平台聚合接待、商品自主学习、7×24
阿里云国际版代理商是经过阿里云官方授权,在特定区域市场(如东南亚、欧洲、北美等)提供阿里云国际版产品销售、技术支持、咨询与服务的合作伙伴。他们不仅是销售渠道的延伸,更是连接阿里云与最终客户的重要桥梁,致力于提供更贴近本地市场的服务体验。代理商通常分为不同级别(如精英级、高级等),享有相应的技术支持权限、销售返点以及市场资源。简化采购流程:提供本地化的合同、发票及支付方式(如本地货币结算)。获取专业
本文档面向希望通过 AI 智能体(Agent)接入阿里云向量检索服务 DashVector 的开发者,提供 LLM 可消费的 API 文档结构和快速入门指导。
本文为AI落地工程师提供了五大主流证书的备考指南,涵盖华为HCIP-AI、阿里云ACP大模型、软考人工智能、微软AI-102和工信部大模型应用工程师证书。文章重点整理了各证书的官方免费资源渠道(附网址),包括考试大纲、课程文档和实战案例,并推荐了B站、GitHub等通用学习平台。针对付费资料选择,提出4条防坑标准:核对版本、区分资料类型、警惕营销话术、合理规划预算。文末给出四阶段备考路线,强调以官
典名科技作为阿里云战略合作伙伴和钉钉六星级钻石服务商,专注为政企提供全链路数字化解决方案。公司覆盖阿里云、钉钉等生态,提供专属钉部署、业财一体化、AI智能体定制等服务,助力客户数智化转型。成立十余年已形成全国服务网络,拥有7家分支机构和300+团队,服务数万客户,2025年业务规模超4亿元。未来将继续深耕云生态,以"客户第一"理念推动企业AI化升级。
本文介绍了OpenClaw v2.7.9连接阿里云百炼的配置教程。主要内容包括: 前置准备:需安装OpenClaw整合包、阿里云账号开通百炼服务并确保网络正常。 操作步骤: 登录百炼控制台,创建并复制APIKey(以sk开头)。 在OpenClaw中粘贴密钥,测试连通性并保存配置。 聊天界面选择通义系列模型进行测试。 自检清单:确保密钥正确、模型可调用、消息正常回复。 常见问题:如密钥丢失需重新创
数据分析开通云数据仓库首选阿里云 AnalyticDB MySQL 湖仓版 Serverless,10 分钟即可从 0 到跑通首条 SQL,最低 ¥0.6/小时起步,配合 500 元新用户代金券可实现前 3 个月低成本试用,是 0 DBA 中小团队构建云原生数据仓库的最佳实践。适用于报表加速、BI 看板、湖仓一体入门等典型场景。立即前往阿里云控制台,10 分钟开启你的第一个云数据仓库。
1.**追求功能直接对标、体验AI“意识”**:**阿里云Qoder Work**是首选,它是WorkBuddy最直接的竞争者。华为云:主要提供**OfficeClaw/OfficeAce**等企业级办公智能体,更强调**安全可控**与**本地化部署**。***CoPaw**:一款**开源**的AI智能体,适合有技术能力、希望**深度定制**的团队或个人。***钉钉“悟空”**:深度集成在钉钉内,
ANOLISA 等50 多款产品一同面向全球南方构建人工智能公共服务资源池。
在江苏常州,一家成立于2014年的企业,几乎与中国新能源汽车产业同步生长。十年过去,星星充电已经成为全球充电桩累计销量第一的品牌——接近300万台充电桩分布在全球70多个国家,累计注册用户超过4500万人。对星星充电CTO王迪来说,这不仅仅是一个数字能源网络,更是一个需要24小时不间断运转的大型物联网系统。而支撑这张网络稳定运行、持续进化的底层,是一张由阿里云构建的全球智能连接底座。本期云故事探索
不过这个现象有点奇怪,ECS2和ECS1在一样的机房一样的配置一样的网络环境,一样的操作系统,一样的服务,一样的容器,为什么一个有问题,一个没问题呢?其二,第一次遇到问题的时候,重启之后没有问题,过了一天之后积累到一定的程度才爆发,这里已经引导了我的思路是积累的问题,那就是缓存不断积累了)docker容器的bug,那也不可能的,每个都是我亲自写脚本,亲自编译,亲自构建的,关键是我关掉了docker
阿里云ECS的收费价格体系设计精细且灵活,没有绝对的“最便宜”,只有“最适合”。追求稳定与最低单价→ 长期项目首选包年包月。追求极致灵活→ 短期、弹性场景选择按量付费。追求极限成本→ 可中断任务大胆使用抢占式实例。追求灵活与折扣的平衡→ 考虑预留实例券。建议您在项目初期采用按量付费进行原型验证,待业务模型稳定后,再根据负载分析结果,制定混合计费策略,并持续利用监控与成本管理工具进行优化。这样,您就
AI 助手 / 数字人长期记忆:PolarDB-X 原生兼容 Mem0,支持跨会话记忆存储与语义检索,记忆检索延迟 < 5ms,适用于个人 AI 助手、企业数字人等需要"记住用户"的场景智能客服多轮对话:向量 + 全文混合检索确保对话历史精准召回,结合结构化业务数据(工单、订单)联合分析,适用于电商客服、金融客服等高并发场景AI Agent 知识积累:支持时间衰减与重要性权重的记忆压缩策略,PB
IoT 物联网平台:设备时序 + 元数据宽表 + 日志检索统一管理,适用于替代 InfluxDB+MySQL+ES 三库拼接方案工业物联网:传感器时序采集 + 设备画像 + 异常检索,适用于预测性维护与数字孪生车联网与智能交通:车载传感器时序 + 车辆档案 + 轨迹检索,适用于大规模车队数据底座互联网运维监控:Metrics 时序 + 配置宽表 + 日志检索,适用于替代 Prometheus+My
本文记录了采用Ollama项目快速本地部署运行qwen1.5模型。
自建ngrok服务器:服务端centos7.6,被控端windows,控制端windows;实现内网穿透
我们使用了阿里云Linux服务器安装完Ollama,无法直接通过域名或者IP访问,但是本机可以直接通过 http://127.0.0.1:11434访问,以下是解决办法。以上是部署Ollama后,无法直接通过IP访问对应的解决方案。“笑对人生,智慧同行!博客新文出炉,微信订阅号更新更实时,等你笑纳~”
证书去阿里云控制搜SSL就能找到对应的菜单,然后申请证书就行,需要注意的证书域名和ngork的域名要对应,也就是假设我希望服务搭建好以后我的接口地址是api.abcd.com,那么你在申请证书的时候填的域名也要是api.abcd.com,不然会报错无法连接。注意我的路径是/root/ngrok/src/ngrok/client,model.go文件24行域名改成上面的api.abcd.com要一致
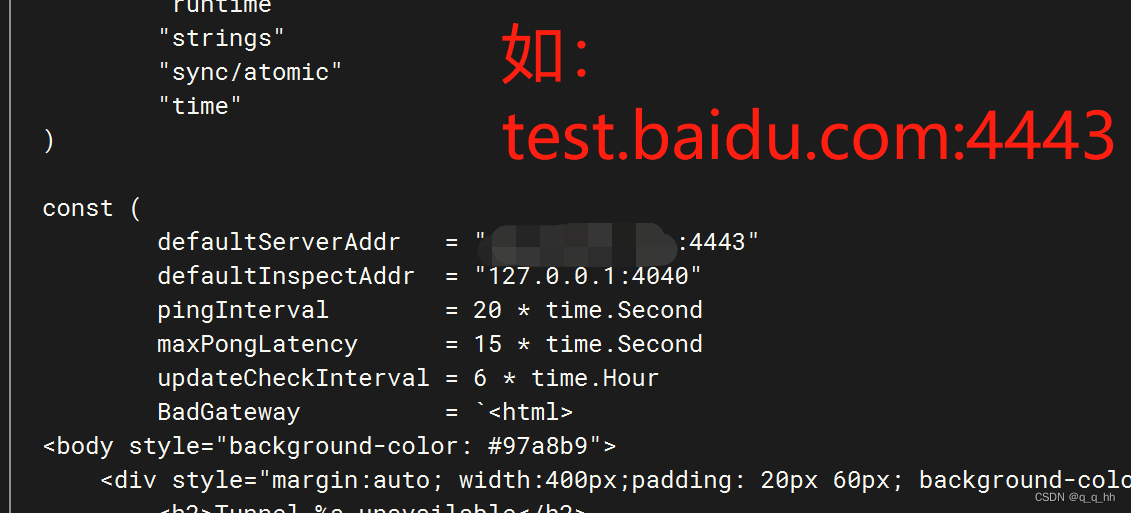
在ngrok的路径下,ngrok/src/ngrok/client/,执行 vi model.go,必须把这个地方改成和二级域名一样(test.baidu.com),默认的是ngrok的,具体是啥忘记了。一定要有二级域名,配置的时候也必须使用二级域名,如果有在阿里云上有了一级域名,再免费申请个二级域名就可以了。1.subdomain代表三级域名的前缀:(my.test.baidu.com),是内网
参考博文:https://blog.csdn.net/qq_34292044/article/details/78559128https://blog.csdn.net/huanxiang201311/article/details/72725891一.环境准备1.固定的ip地址,我用的是阿里云,系统cenos6,比较老的系统。阿里云有自己的安全组策略,请把你自己的端口加进安全组里。如图2.需要有
摘要: 2026世界人工智能大会展示了液冷技术在AI算力集群中的应用趋势,强调需从系统架构层面评估液冷方案。液冷技术分为冷板、单相浸没和两相浸没三种路线,各有不同的介质特性、兼容性及工程验证重点。选型需结合系统设计、材料兼容性、测试条件等综合考量,而非单一物性参数。苏能等企业针对不同路线开发了特定产品,但实际应用需以项目验证结果为准。工程验证应包含架构图、材料清单、测试方案等完整资料包,确保技术落
redis连接失败,相关配置都已经修改完毕,但报错信息里的localhost我都不知道哪里来的,我都把ip地址改为我自己服务器的ip地址了。
4. 获取skywalking镜像。1.卸载旧版本docker。5.验证docker。出现如下界面表示成功。
对k8s容器运维的过程中,如果是自建k8s的话,一般会安装dashboard,方便管理;如果是阿里云k8s容器,它是有提供web ui,但是它有个不便之处–需要定期登录,且缺少命令控制台。当你需要使用命令控制台时,阿里云会建议你安装kubectl本文推荐一款k8s管理工具–kubepi,它可以方便地管理多个k8s集群,不仅提供kubectl命令控制台,还有web UI。下面将介绍如何使用Kubep
当宝塔部署完项目,使用项目出现页面刷新nginx404问题;
1.如果nacos 四在运行的时候报这个错,然后你自己访问本地的nacos没有问题那么你得考虑一下版本问题(高版本一般不需要考虑),然后就是端口的问题,因为在nacos的2.*之后有新的grpcQ的特性引入所以你得特别注意还得开启两个rpc的端口这样才不会报错,尤其是docker的环境下,特别注意开启这2个端口。本地可以连上nacos,但到阿里云容器部署的时候连不上nocos,并且配置都对。
因生产binlog备份文件异常增大,需要查看并分析binlog中记录事务,具体问题具体分析。(阿里云下载了binlog日志,需要打开查看。)下载binlog日志为二进制文件,无法直接打开,在如何转换过程中,走了弯路,最终使用MySQL转化binlog日志格式方便有效。
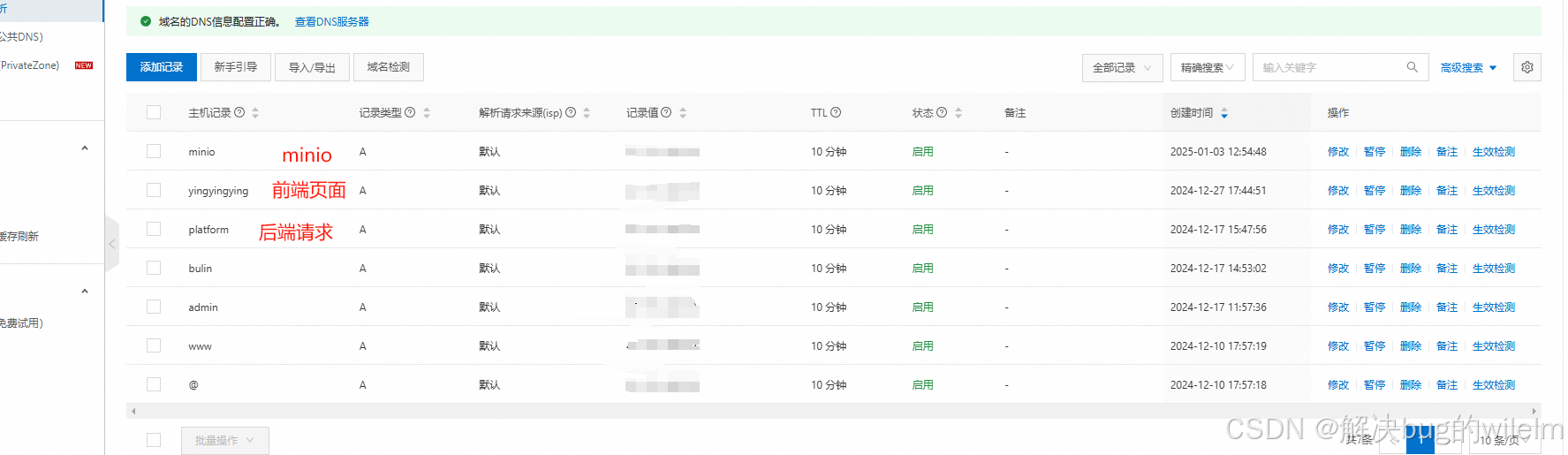
minio配置域名,minio配置https访问
按照以上步骤,你应该能够在阿里云ECS上成功使用Docker安装并运行Nacos。如果遇到任何问题,请检查Docker日志或Nacos的日志文件以获取更多信息。在ECS上创建用于存储Nacos日志和配置文件的目录。如果需要自定义Nacos的配置,可以将配置文件(如。目录中,并在Docker命令中通过。
摘要:本文介绍了在AlibabaCloudLinux3.2104LTS64位系统上安装配置MySQL5.7和Nginx的完整流程。包括:1)更新系统源并安装MySQL5.7;2)设置MySQL初始密码、创建新用户及配置字符集;3)可选远程访问配置;4)安装Nginx并配置服务;5)安装证书工具和JDK1.8;6)Nginx反向代理配置及Jar包启动方法。文中详细说明了每个步骤的命令和注意事项,如M
登录阿里云,找到产品–>ECS服务器选择:云服务器ECS免费试用(个人版)
阿里云
——阿里云
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 AI编程社区
AI编程社区

 智能体开发者社区
智能体开发者社区

 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区


 深开鸿 技术专区
深开鸿 技术专区

 AI Agent技术社区
AI Agent技术社区


 DAMO开发者矩阵
DAMO开发者矩阵



 CSDN-OPC开发者社区
CSDN-OPC开发者社区










 openEuler 社区
openEuler 社区