登录社区云,与社区用户共同成长
邀请您加入社区
在高并发QPS场景下,Python技术栈的API接口性能瓶颈贯穿操作系统内核、Web服务运行时、业务代码全链路。仅针对单一层面调优难以突破系统吞吐上限,尤其Python受GIL限制,更需要从底层资源、中间件架构到业务逻辑进行系统性优化。本文从三大核心维度拆解全链路调优方案,结合Linux内核配置、运行时参数与生产级Python代码,给出可直接落地的性能提升方案。
本文总结了pytest测试用例的四种执行状态:passed(通过)、failed(断言失败)、error(用例代码错误)和xfail(预期失败)。通过实例分析:当参数不存在或fixture出错时标记为error;断言失败或主动抛出异常时标记为failed;使用@xfail成功捕获预期异常时标记为xfail。报告中的error越多说明用例质量越差,failed表示断言问题,而xfail是预期的失败情
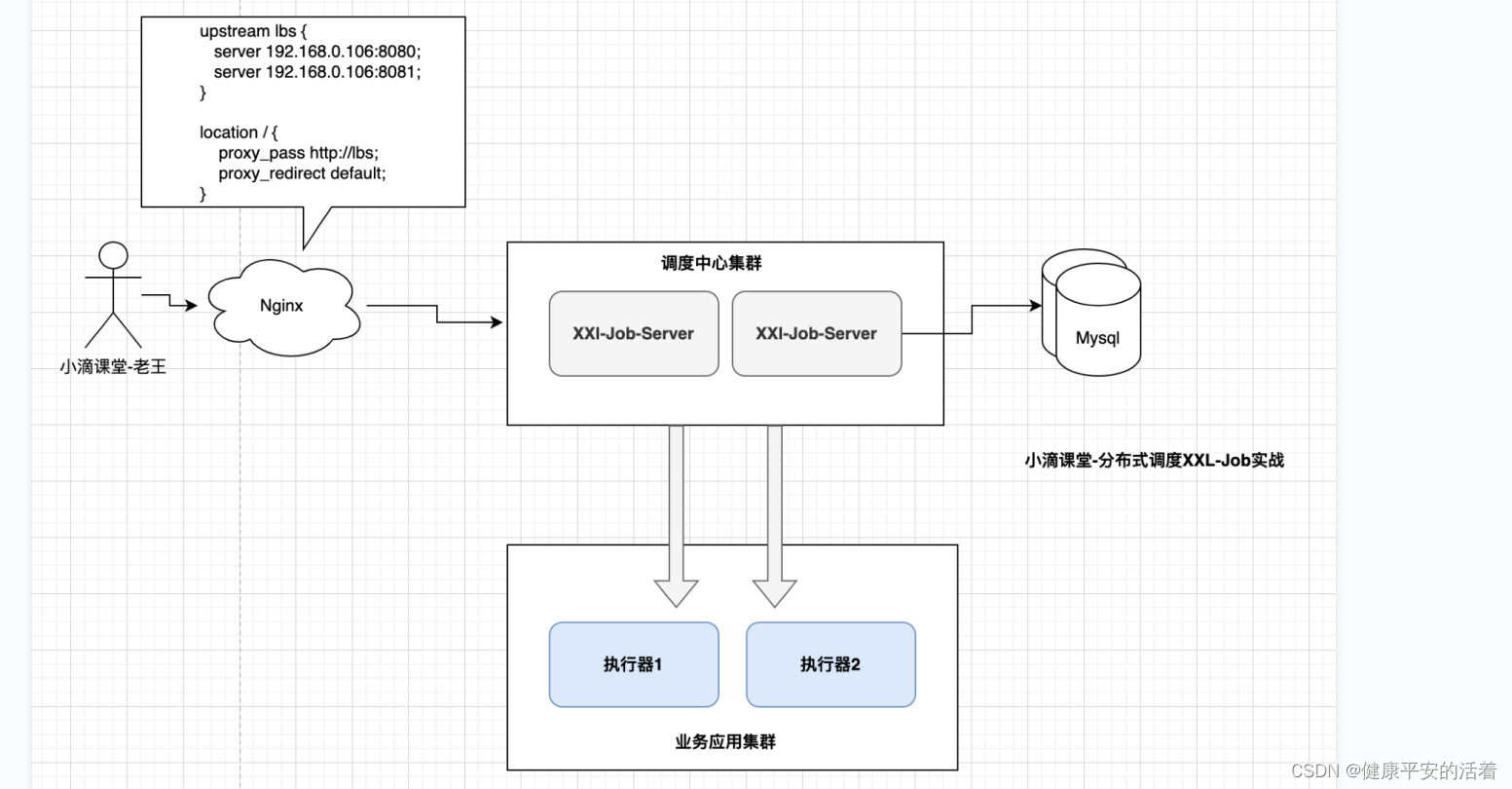
为了避免单点故障,任务调度系统通常需要通过集群实现系统高可用由于任务调度系统的特殊性,“调度”和“任务”两个模块需要均支持集群部署,由于职责不同,因此各自集群侧重点也有有所不同。
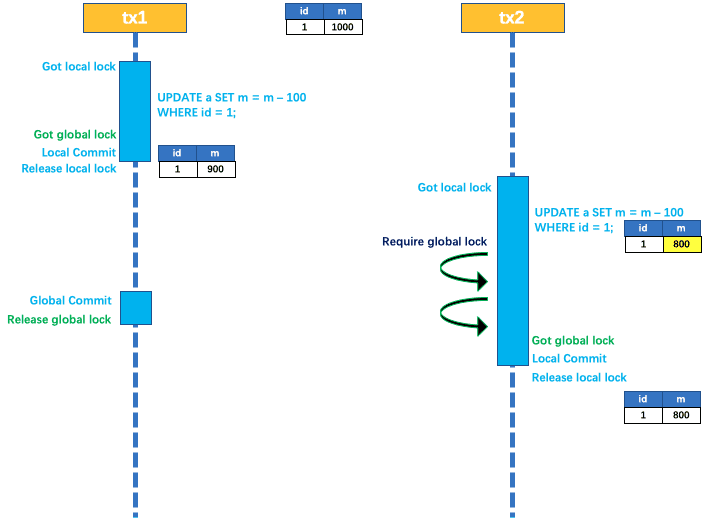
在联机文档中是这样描述MS DTC的:Microsoft 分布式事务处理协调器 (MS DTC) 是一个事务管理器,它允许客户端应用程序在一个事务中包含多个不同的数据源。MS DTC 协调在所有已在事务中登记的服务器间提交分布式事务。Microsoft® SQL Server™ 安装可通过下列方法参与分布式事务:1,调用运行 SQL Server 的远程服务器上的存储过程。 2,自
戴尔EMC SC系列高端企业级分布式存储数据恢复案例解析:针对SC4020存储因多硬盘故障导致系统无法启动的情况,采用底层数据重组技术恢复。通过分析三层虚拟存储架构(物理层、RAID虚拟层、文件系统层),逆向解析元数据并重建LUN结构。解决方案包括:获取加密元数据密钥、解析BSD系统信息、构建虚拟RAID空间、逆向分布式文件系统,最终成功恢复跨SSD/HDD的LUN数据。案例展示了专业团队对复杂存
事务处理 :本地 、全局、分布式单个服务使用单个数据源:本地事务单个服务使用多个数据源:全局事务多个服务使用单个数据源:共享事务(通常不会这么使用)多个服务使用多个数据源:分布式事务
Percona Toolkit 是一套由 Percona 公司开发的高级 MySQL 运维工具集,专门用于性能分析、数据修复、复制监控和架构优化。
RJE1Y23610C42401常见的应用方向包括工业自动化生产设备、工业机器人、PLC控制系统、网络交换设备、服务器平台、通信机柜、轨道交通电子设备、智能仓储系统、检测设备以及新能源控制装置等。
服务器: 消息 7391,级别 16,状态 1,行 6该操作未能执行,因为 OLE DB 提供程序 SQLOLEDB 无法启动分布式事务。[OLE/DB provider returned message: 不能在指定的事务处理器中获得新事务。]---------------------------------------------------------------------------
VMware vSphere标准交换机(VSS)和分布式交换机(VDS)的区别
一、服务器端挂载参数调整:二、nfs-client 客户端挂载选项调整 (多个选项之间用逗号分开)1.atime 更新访问时间 这个建议别用,会降低nfs的性能 可以加上noatime2.auto 能够被自动挂载通过-a选项3.async 异步挂载 sync同步挂载sync适用在通信比较频繁且实时性比较高的场合,比如Linux系统的rootfs通过nfs挂载。三、分析磁盘IO性能是否达上限:四、测
PyCharm的缺点是:不能实时同步、操作繁琐,需要维护两份代码。而VS Code是通过SSH(Secure Shell)的方式连接到远程服务器,换句话说,VS Code在远程开发过程中扮演的角色更像是一款终端模拟工具,它不需要繁琐的上传和下载步骤,实时性更好,只需要在Windows上保存一下,就会瞬间同步到远程服务器。
1、DCOM COM的进程透明特性表现在组件对象和客户程序即可以拥有各自的进程空间,也可以共享同一个进程空间,COM负责把客户的调用正确传到组件对象中,并保证参数传递的正确性。组件对象和客户代码不必考虑调用传递的细节,只要按照一般的函数调用的方式实现即可。如果进一步拓展进程透明特性,考虑组件对象与客户程序运行在不同计算机上的情形,把进程透明性拓展为位置透明性,形成分布式组
这款工具的价值不在于它用了多么高深的技术,而在于它把**“交叉验证”**这个朴素的思想贯彻到了极致。当攻击者能够Hook系统调用、篡改内核数据结构时,单一的信息源已经不可信。只有通过多个独立渠道获取信息并对比差异,才能发现那些被精心隐藏的威胁。程序猿编码。
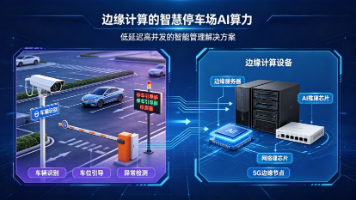
每个楼层部署 3台 SE110S-WA32 边缘计算微服务器,连接该楼层的 100 个摄像头,所有 SE110S-WA32 通过千兆以太网连接到商场的核心交换机,分析结果通过专线上传到云端管理平台,供商场管理者查看和决策,原始视频流与敏感数据(如人脸特征)在边缘侧完成推理与丢弃,仅将结构化数据(客流计数、报警事件)上传云端,从架构底层保障数据隐私合规。而在具体的架构落地中,边缘算力节点的选型至关重
进程可以注册一个自己写的函数,当收到信号时,不执行默认动作,而是执行我们自定义的逻辑。注册方式:用signal()或更安全的系统调用,把信号和自定义处理函数绑定。关键注意事项:信号处理函数里,必须使用异步信号安全的函数(也叫可重入函数),比如write()类型的操作。不能用printfmalloc这类非安全函数,否则可能导致程序崩溃。类比:就像上课铃响了,你不回教室,反而去操场打球,就是 “自定义
【尼尔机械纪元安装简明指南】本文提供尼尔机械纪元从下载到安装的完整流程说明。安装前需确保硬盘空间≥50GB,关闭杀毒软件。教程包含6个关键步骤:1)管理员身份运行安装程序;2)设置解压路径;3)进入游戏文件夹;4)创建桌面快捷方式;5)启动游戏;6)完成安装。特别提醒:建议使用纯英文路径,配置要求至少GTX 770显卡+8GB内存。文中附详细截图指引和下载链接,帮助新手顺利完成这款白金工作室动作R
本文基于国科环宇土星云SE110S-WA32 边缘计算微服务器,建立了一套科学的智慧停车场 AI 算力评估模型,并提供了完整的端边云协同部署方案。SE110S-WA32 作为一款高性能的边缘计算微服务器,将为智慧停车场的未来发展提供强大的算力支撑,助力城市交通治理的数字化和智能化升级。同时,它支持-20℃~+60℃的宽温工作范围,具备IP40 防护等级,能够适应地下车库等恶劣的工业环境。三个核心维
终端 SDK 是支付安全的第一道关口,但绝非一劳永逸的解决方案。纵深防御:结合终端 SDK、业务风控系统、人工智能模型,构建从端到云的多层防御体系。数据驱动:持续分析攻击日志与风控数据,迭代 SDK 的检测规则与算法模型。合规先行:确保 SDK 的数据采集、处理符合 GDPR、个人信息保护法等法律法规要求。开发者赋能:提供清晰的文档、完善的错误码体系和及时的技术支持,降低安全功能的集成门槛。
本文介绍了NumPy库的核心概念和基本操作。NumPy作为Python科学计算的基础库,其核心是ndarray(N维数组)对象,相比原生Python列表具有显著优势:内存块风格(连续存储、类型一致)、并行化运算和底层C语言实现带来的高效计算。文章详细讲解了ndarray的属性(形状、维度、类型等)、不同维度的数组表示方法,以及数据类型体系。最后介绍了数组的基本操作,包括生成方法和索引切片机制。Nu
以下所有数据来自同一套超算环境(Lustre文件系统、NetCDF 4.4.1、1991-2020 OSTIA SST数据),确保对比的公平性。
加油.
# Matter协议:智能家居的统一语言> 你的小米灯泡和苹果HomeKit对话,华为音箱和谷歌Nest联动——这不是梦,是Matter正在做的事。这个由Apple、Google、Amazon、三星等巨头联手打造的协议,正在终结智能家居的"方言时代"。## 智能家居的碎片化困境``` 现状(方言时代): Apple HomeKit ──私有协
文章摘要: 本文深入探讨了Linux系统中的信号机制,主要内容包括: 信号概念:信号是进程间异步通信机制,用于通知特定事件发生,与信号量完全不同。 信号产生方式:键盘组合键(如Ctrl+C)、系统调用(kill/raise/abort)、硬件异常(除零/段错误)和软件条件(如定时器)。 信号处理流程:内核通过pending位图保存信号,在进程从内核态返回用户态时检查处理。 信号捕捉细节:用户自定义
无线升级(OTA)固件包 200KB,传输到一半突然断电,重启后进不了程序?不是网络不稳,而是 缺少断点记录(Checkpoint)和双分区回滚(Rollback)机制。本文解析工业级 OTA 的完整实现思路。
它是 4-bit 的非均匀浮点格点。真实值 ≈ FP4裸值 × block scale × global scale但工程上会用 calibration、clipping、QAT 或误差最小化来改进。FP4 提供一组极少的非均匀浮点格点;NVFP4 通过 block scale 和 global scale,把这些格点缩放到每个 block 的真实数值范围中,从而用 4 bit 近似表达 FP16
EASY-EAI-PI2是灵眸科技研发的一款应用于AIoT领域的开发板。核心板基于瑞芯微的RV1126B处理器设计,集成了4个Cortex-A53及独立的NEON协处理器,支持4K@30fps的 H.264/H.265解码器,还支持4K@30fps的H.264/H.265编码器。引入了新一代完全基于硬件的最大 12M 像素 ISP(图像信号处理器),实现了多种算法加速器,如HDR、3A、LSC、3
从 CANopen NMT 协议出发,结合 CANopenNode 源码解析状态切换、Heartbeat 上报、命令处理与错误降级流程。
支持单圈 / 多圈 / 全信息 / 编码器ID四类命令单圈命令自动递增,峰值归零DMA + 中断方式保证高速响应 (<3µs)RS485 半双工控制,硬件自动完成发送。
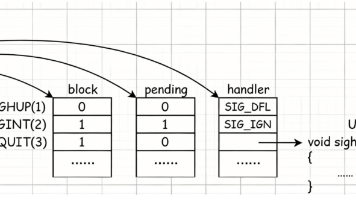
本文深入探讨了Linux信号的保存机制。当信号产生但进程暂时无法处理时,信号会被保存在内核维护的三个关键数据结构中:pending表记录未决信号,block表记录被阻塞信号,handler表存储信号处理方式。文章详细介绍了信号相关概念(递达、未决、阻塞与忽略的区别)以及内核中的信号集表示方式(sigset_t位图结构)。同时讲解了信号集操作函数(如sigemptyset、sigprocmask等)
Linux 7.1内核带来多项重要更新:全新NTFS驱动提升性能,Intel FRED中断机制革新,移除i486支持,以及QAT硬件加速Zstd压缩。新NTFS驱动基于iomap和folio重写,大幅提升读写效率;FRED重构了40年历史的中断处理流程;淘汰i486支持简化了内核代码;QAT新增Zstd硬件加速特别适合日志处理等场景。这些改进在存储性能、系统响应和特定工作负载方面带来显著提升。
服务器
——服务器
联系我们(工作时间:8:30-22:00)
400-660-0108 kefu@csdn.net

 openEuler 社区
openEuler 社区

 2048 AI社区
2048 AI社区

 深开鸿 技术专区
深开鸿 技术专区






 DAMO开发者矩阵
DAMO开发者矩阵









 AMD开发者中国社区
AMD开发者中国社区



 亚马逊云科技技术品牌专区
亚马逊云科技技术品牌专区












